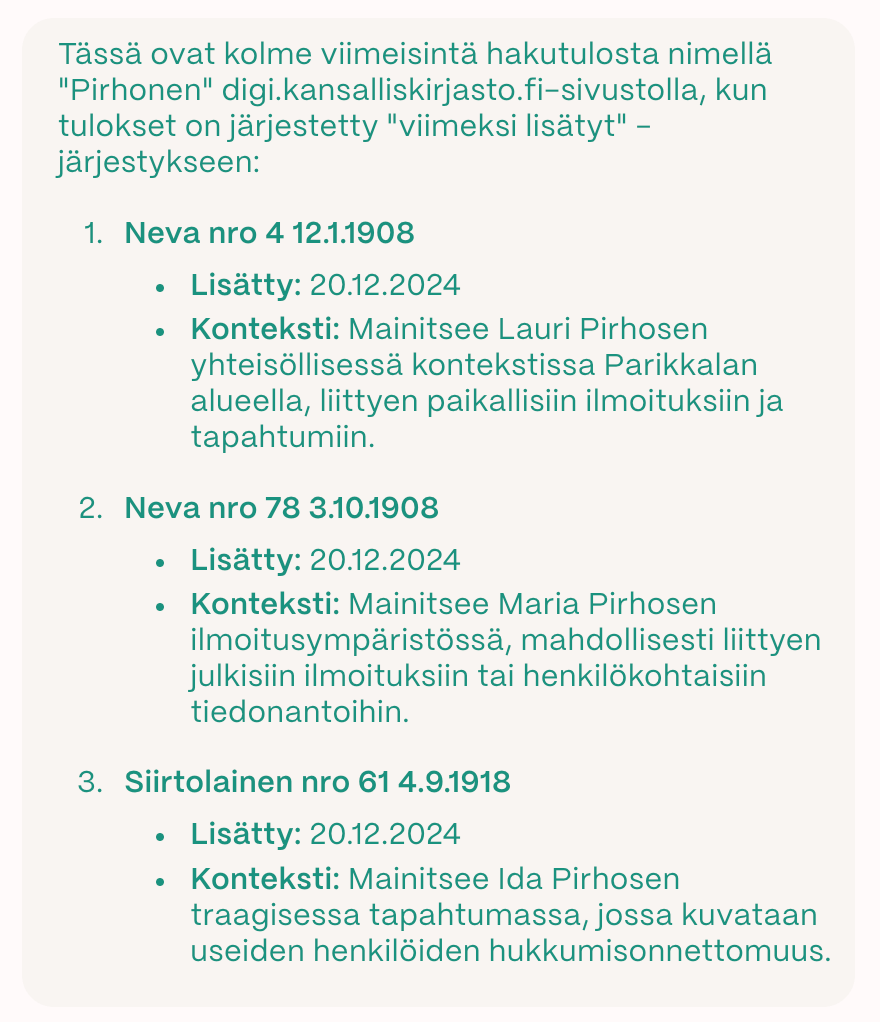
Tekoäly muuttaa hakukoneita – mutta mitä se tarkoittaa medioille? Riippuu siitä, haluatko tulla helposti löydetyksi vai suojella sisältöäsi. Kumpikin voi olla tapauksesta – ja sisällöstä – riippuen perusteltua, mutta kumpaakin on vaikea saada samassa paketissa.
Kokoan tähän kirjoitukseen eri lähteistä kokoamiani pohdintoja siitä, millainen sisältö olisi tämänhetkisen käsityksen mukaan parhaiten suojassa vaikkapa Googlen tekoäly-yhteenvedoilta ja toisaalta, millaiset toimenpiteet nostavat mahdollisuuksia päästä niissä esille mahdollisimman hyvin. Puhutaan siis tekoälyoptimoinnista eli GEO:sta tai jopa AEO:sta eli “hakukoneoptimoinnista vastausmoottoreille”.
Samaan aikaan niin sanotun perushaun optimointiakaan ei voi vielä unohtaa.
Medioille aihe on hankala, sillä tekoälyt käytännössä vähentävät medioille tärkeää liikennettä. Googlen osalta huolestuttavinta tällä hetkellä lienee, että se on ollut tuomassa tekoäly-yhteenvetoja myös Discover-uutissyötteeseen, joka on pitkään ollut perushakua tärkeämpi liikenteenlähde.
ChatGPT:n ja Clauden kaltaisille tekoälypalveluille journalistinen sisältö on tärkeää, sillä niiden siteeraamasta materiaalista jopa 25-50 prosenttia on peräisin uutismediasta.
AI-epäystävällinen sisältö
- Kaikki sellainen, mikä on koneelle vaikeinta tiivistää/kopioida/pilkkoa.
- Suosi sellaista kerrontaa, jossa näkyy kirjoittajan oma kokemus ja läheisyys aiheeseen (paikalla oleminen, henkilökohtaiset havainnot, yksityiskohtaiset kuvaukset). Kuvaileva, värikäs kieli, sanaleikit, metaforat, monitulkintaisuus – mutta ei toki asiakkaan ymmärryksen kustannuksella. Hollantilainen mediastrategi Piet van Niekerk tiivistää tämän käsitteeseen “emotional proximity”: jos onnistut luomaan sitä, se on vaikeinta tekoälyn kopioida tai tiivistää. Van Niekerk ehdottaa myös edellä kuvatun tyyppisen “pitkähäntäisen” eli hyvin aikaa kestävän sisällön lisäämistä. Toisaalta esimerkiksi aikaa kestävä lifestyle- tai ruokasisältö, tai horoskoopit, näyttäisi ensihavaintojen mukaan kärsivän eniten hakukoneliikenteen vähenemisestä, varmaankin osin koska niiden yhteydessä tekoälytiivistelmät näyttävät harvemmin linkkejä.(linkkien määrä vaihtelee sen mukaan, onko kyse esim. Perplexitystä, ChatGPT:stä tai Googlen tekoäly-yhteenvedoista tai Googlen AI Modesta).
- Käytännössä uutispuolella esimerkiksi hetki hetkeltä -seurannat tai pidemmät kuvailevat jutut kuten reportaasit ja featuret voivat olla tällaisia. Mitä uniikimpi ja omaleimaisempi tyyli, sen parempi.
- Kiinnostavin fakta tai faktat eivät selkeästi poimittavissa jutun alusta, esim. yhdessä lauseessa. Useampi näkökulma samassa jutussa. Pitkissä jutuissa kronologian rikkominen.
- Jutussa olennaisia tietoja muuallakin kuin vain perustekstinä, kuten grafiikassa tai videolla. Useat sisältöelementit aiheuttavat sen, että pelkkä tekstin lukeminen ei anna tekoälylle koko kuvaa (tässäkin toki mietittävä ensisijaisesti asiakkaan käyttökokemusta, ei tekoälyä – itsehän olen sitä mieltä, että valtavat monimediaiset juttupläjäykset turhan usein lähinnä karkottavat lukijan, vaikka toimituksen mielestä hienolta näyttää).
- Tekniset toimenpiteet, esimerkiksi tekoälybottien blokkaus, jotta tekoäly-yhtiöt eivät käyttäisi medioiden materiaalia vastikkeetta. Blokkaamisen toimivuudesta ei ole takeita, eikä välttämättä edes maksumuuri pidättele tekoälyjä.
- Oikeudelliset toimenpiteet (esim. New York Times vs. OpenAI, tai Chilessä Copesa vs. Google)
AI-ystävällinen sisältö
- Mieti sisältöjä ja niiden rakennetta siten kuin ne ovat esillä tekoälychäteissä tai esimerkiksi Googlen tekoäly-yhteenvedoissa.
- Tässä INMA:n artikkelissa hieman konkretiaa: “Think featured snippets, “people also ask” boxes, or position zero.”
- Kaikki sellainen, mikä on koneelle helpointa tiivistää.
- Kiinnostavin fakta tai faktat heti selkeästi jutun alussa, esim. yhdessä lauseessa.
- Selkeä otsikko ja ingressi, joista jutun pääsisältö käy jo ilmi.
- Kaikki oleellinen html-tekstinä, ei esimerkiksi grafiikoihin tai videoihin “piilotettuna”.
- Valmiit tiivistelmät jutun yhteydessä, tai juttu itsessään tiivistelmämuodossa.
- Listamuotoiset jutut (kuten tämäkin tekemäni tässä nyt).
- Nimet, numerot ja muut keskeiset tiedot selkeästi esillä.
- Lineaariset aikajanat. Lyhyet kappaleet.
- Erillissopimus tekoäly-yhtiöiden kanssa median aineistojen käytöstä saattaa nostaa todennäköisyyttä näkyvyydelle tekoälypalveluissa – tosin päinvastaisiakin havaintoja on.
- Tekniset toimenpiteet: metadatan rakentaminen tukemaan em. asioita.
Iso kuva
Suomi on siinä mielessä poikkeus, että täällä monia muita maita isompi osa tulee uutispalveluihin suoraan, joten tekoälyhakujen laajemmat vaikutukset näkyvät meillä viiveellä. Asiantuntijat kehottavatkin toimenpiteisiin, jotka edelleen vahvistavat suoraa liikennettä palveluihin, mikä voi tarkoittaa esimerkiksi uutiskirjeiden tai etusivun ja artikkelinäkymän kehittämistä.
Medioiden suhteessa tekoälyjätteihin on kaikuja sosiaalisen median nousun alkuaikoihin: oli jälkikäteen katsottuna perinteiseltä medialta virhe tehdä liiaksi someen nojautuvaa strategiaa (vrt. Buzzfeed), mutta ei sieltä kokonaankaan voinut tietenkään pois olla. Sama tasapainottelu on edessä nytkin. Se on ainakin selvää, että mediataloissa kannattaa vastuuttaa henkilö tai henkilöitä seuraamaan tätä kehitystä, ei vain liikennetasolla, vaan myös sisältö/aihetasolla, kuten INMA:kin alleviivaa.
Kuvituskuva: Adobe Firefox.