Suomeksi – in Finnish (find the English version below or on the side depending on whether you use desktop or mobile):
1. Suuret yrityskaupat
Paramount Skydance–WBD: Yhdysvaltain oikeusministeriö hyväksyi Paramountin 110 miljardin dollarin jättikaupan, jossa se ostaa Warner Bros. Discoveryn (HBO, CNN ym.). Useat osavaltiot kuitenkin nostivat oman kanteensa kaupan pysäyttämiseksi kilpailuoikeudellisin perustein, joten sen toteutuminen on yhä epävarmaa. Taustalla on kilpailuoikeudellinen huoli, myös poliittiset jännitteet.
Comcast jakautuu kahtia: Yhdysvaltalainen media- ja tietoliikennekonserni Comcast ilmoitti erottavansa NBCUniversalin ja eurooppalaisen mediayksikkönsä Skyn omaksi pörssiyhtiökseen, erilleen laajakaistaliiketoiminnastaan. Uusi sisältöyhtiö (Universal-studiot, teemapuistot, Peacock, NBC, Telemundo, Bravo) olisi houkutteleva kohde varakkaille ostajille. CNN:n mukaan analyytikot pitävät järjestelyä askeleena kohti seuraavaa mediakauppa-aaltoa, vaikka Comcast itse kiistää tämän ja korostaa NBCUniversalin kasvumahdollisuuksia itsenäisenä yhtiönä. Isossa-Britanniassa jakautuminen on herättänyt huolta Sky Newsin tulevaisuudesta.
Fox ostaa Rokun 22 miljardilla dollarilla: Suoratoistoalusta Rokun osto käytännössä tuo Foxin sisällöt aiempaa voimakkaammin älytelevisioihin ja vahvistaa sen asemaa suoratoistomarkkinoilla perinteisen tv-kanavabisneksen rinnalla. Kauppa on vielä lopullista hyväksymistä vailla.
Axel Springer sai vihdoin Telegraphin: Saksalainen mediakonserni Axel Springer (mm. Bild, Politico) sai kolmen vuoden veivaamisen jälkeen päätökseen kaupan, jossa se osti brittiläisen laatulehden The Telegraphin.
2. Kävijäliikenteen lasku
Suurimpien englanninkielisten sivustojen liikennepudotus: Kesän aikana julkaistut mittaukset osoittivat, että valtaosa isoista uutissivustoista menetti kävijöitä vuodentakaiseen. Suhteellisesti suurin pudotus oli Intiassa toimivissa englanninkielisissä sivustoissa. Useimmat brittiläiset uutisbrändit menettivät yli 10 % liikenteestään verrattuna vuodentakaiseen. Taustalla ovat erityisesti Googlen hakutuloksiin ilmestyvät tekoälyvastaukset, mutta arvioiden mukaan myös muut Googlen algoritmimuutokset.
SPUR-koalitio laajenee: Kustantajien perustama yhteenliittymä SPUR rakentaa seurantajärjestelmän, jonka avulla julkaisijat voivat todentaa, millä tavoin tekoälyfirmat käyttävät niiden sisältöä. Tämä toimii pohjana mahdollisille korvausvaatimuksille. Kesän aikana koalitioon liittyivät mm. WAN-IFRA ja uutistoimisto AP, mikä kasvattaa sen painoarvoa.
UK:n Google-päätös: Britannian kilpailu- ja markkinaviranomainen määräsi, että Googlen on annettava mediatalojen halutessaan kieltäytyä siitä, että heidän sisältöään käytetään Googlen tekoäly-yhteenvedoissa ilman, että kieltäytyminen “rankaisee” niitä tavallisissa hauissa.
Mikromaksut/tekoälyagentit maksajina: OpenAI:n toimitusjohtaja Sam Altman totesi keväällä uskovansa julkaisijoiden tulevaisuuden olevan mikromaksuissa, mutta ihmislukijoiden sijaan tekoälyagenttien maksamina. Useita erilaisia toteutustapoja on kokeiluvaiheessa (mm. Tollbit, Prorata.ai, Cloudflaren pay-per-crawl ja Stripen kesäkuussa julkaisema Machine Payments Protocol), vaikka vakiintunutta mallia ei vielä ole. Aihe nousi kesän media-alan keskusteluun heinäkuussa The Rebootingin ja News Machinesin uutiskirjeissä. Ero nykyisiin kertaluonteisiin lisenssisopimuksiin on se, että kiinteän vuosisumman sijaan julkaisija saisi pienen korvauksen jokaisesta yksittäisestä agenttikäynnistä.
Katso myös päivitetty listani tekoälyn käyttötapauksista mediassa täältä.Tsekkaa myös mediastrategi Sergey Yakupovin vastaavantyyppinen listaus.
4. Perinteisen median liiketoimintamallit
Belgialainen Le Soir kokeilee lojaliteettiperustaista hinnoittelua eli mallia, jossa hinta ei perustu vain tilausjaksoon vaan siihen, kuinka aktiivinen lukija on, palkiten uskollisia lukijoita esim. edullisemmalla hinnalla.
Fox teki poikkeuksellisen edullisen MM-kisadiilin, analysoidaan media-alan lähteitä kokoavassa CNN:n Reliable Sources -uutiskirjeessä. Katsojaluvut rikkoivat ennätyksiä toistuvasti Yhdysvalloissa läpi koko turnauksen, myös sen jälkeen kun USA putosi kisoista. Fox Sports ilmoitti jo kesäkuun lopussa yli 84 miljoonan amerikkalaisen seuranneen lähetyksiään.
Yle sai kritiikkiä tekoälyavusteisesti editoitujen ottelukoosteidensa puutteista: Iltalehden mukaan katsojat huomasivat, että joistain Yle Areenan koosteista jäi pois ratkaisuhetkiä. Yle myönsi tekoälytyökalun olleen uusi ja puutteellinen erityisesti rangaistuspotkukilpailuissa, ja vähensi sen roolia turnauksen loppupuolella.
Lähteinä on käytetty seuraavia uutiskirjeitä kesän ajalta: Axios Alerts, CNN Reliable Sources, Press Gazzette, WAN-IFRA, Digiday, Media Copilot, The Rebooting, News Machines. Lisäksi Nieman Lab ja Iltalehti.
Muista myös DNR26. Maailman suurin vertaileva uutistutkimus, Reuters-instituutin Digital News Report 2026 julkaistiin taas kesäkuussa. Kv-raportti löytyytäältä, Suomen-maaraporttitäältäja blogiin tekemäni tiivistelmätäältä.
Kesän kirjasuositus on Aftonbladetin entisen tekoälypomon Martin Schorin ”AI in the Newsroom”, jota on suositeltu laajalti, mm. täällä, täällä ja täällä.
In English (find the Finnish version above or on the side depending on whether you use desktop or mobile):
1. Major Corporate Deals
Paramount Skydance–WBD: The US Department of Justice approved Paramount’s $110 billion mega-merger, under which it acquires Warner Bros. Discovery (HBO, CNN, etc.). However, several states filed their own lawsuit to block the deal on antitrust grounds, so its completion remains uncertain. Behind it lies antitrust/competition-law concern, as well as political tensions.
Comcast splits in two: US media and telecommunications conglomerate Comcast announced it will spin off NBCUniversal and its European media arm Sky into a separate publicly traded company, apart from its broadband business. The new content company (Universal studios, theme parks, Peacock, NBC, Telemundo, Bravo) would be an attractive target for deep-pocketed buyers. According to CNN, analysts see the move as a step toward the next wave of media dealmaking, even though Comcast itself denies this and emphasizes NBCUniversal’s growth prospects as a standalone company. In the UK, the split has raised concerns about the future of Sky News.
Fox buys Roku for $22 billion: The acquisition of streaming platform Roku brings Fox’s content more directly onto smart TVs and strengthens its position in the streaming market alongside its traditional TV channel business. The deal is still pending final approval.
Axel Springer finally gets the Telegraph: German media group Axel Springer (Bild, Politico, among others) completed its acquisition of British broadsheet The Telegraph after three years of wrangling.
2. Declining Traffic
Traffic drop at the largest English-language news sites: Measurements published over the summer showed that most major news sites lost visitors compared to a year earlier. The steepest relative decline was among English-language sites based in India. Most British news brands lost more than 10% of their traffic year-on-year. The main driver is Google’s AI-generated answers appearing in search results, though other Google algorithm changes are also thought to have played a role.
SPUR coalition expands: SPUR is an alliance founded by publishers. It is building a shared ”Content Telemetry Framework” tracking system that lets publishers see and verify how much, and in what ways, AI companies are using their content – providing a basis for potential compensation claims. Over the summer, WAN-IFRA and news agency AP joined the coalition, increasing its clout.
UK’s Google ruling: Britain’s competition and markets authority ordered Google to allow media outlets to opt out of having their content used in Google’s AI summaries, without that opt-out ”penalizing” them in regular search results.
Micropayments/AI agents as payers: OpenAI CEO Sam Altman said in spring 2026 that he believes publishers’ future lies in micropayments but paid not by human readers, rather by AI agents each time they use content. Several different implementations are already in testing (including Tollbit, Prorata.ai, Cloudflare’s pay-per-crawl, and Stripe’s Machine Payments Protocol launched in June), though no single standard model exists yet. The topic entered summer media-industry discussion in July via The Rebooting’s and News Machines’ newsletters. The difference from current one-off licensing deals is that instead of a fixed annual sum, the publisher would receive a small payment for every individual agent visit.
See also my updated list of AI use cases in media here. Also check out media strategist Sergey Yakupov’s listing.
4. Traditional Media Business Models
Belgium’s Le Soir is testing loyalty-based pricing – a model where the price isn’t based on subscription length alone but on how engaged and active the reader is, rewarding long-term, loyal readers with, for example, a lower price.
Fox struck an exceptionally cheap World Cup deal, according to analysis compiled in CNN’s media-industry newsletter Reliable Sources. Viewership figures repeatedly broke records in the United States throughout the tournament, even after the US team was eliminated. Fox Sports reported by late June that more than 84 million Americans had watched its coverage.
Finnish Broadcasting Company Yle faced criticism over the shortcomings of its AI-edited match highlight reels: according to Finnish tabloid Iltalehti, viewers noticed that some of the highlight clips left out key moments. Yle admitted the AI tool was new and had flaws, particularly around penalty shootouts, and reduced its role toward the end of the tournament.
Sources: the following newsletters from over the summer: Axios Alerts, CNN Reliable Sources, Press Gazette, WAN-IFRA, Digiday, Media Copilot, The Rebooting, News Machines. Also Nieman Lab and Iltalehti (Finnish tabloid).
Also worth noting: DNR26. The world’s largest comparative news study, the Reuters Institute’s Digital News Report 2026, was published again in June. The international report can be found here, the Finland country report here, and my own blog summary here (in Finnish).
This summer’s book recommendation is Martin Schori’s ”AI in the Newsroom” – the former head of AI at Aftonbladet — which has been widely recommended, including here,here and here.
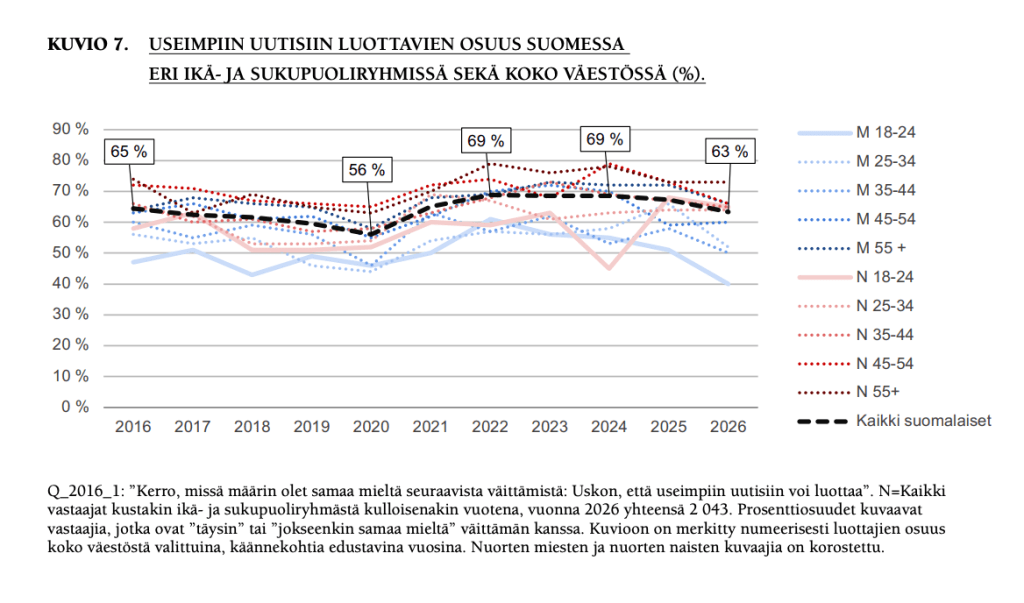
1) Luottamus uutisia kohtaan laskee, mutta Suomi on yhä maailman kärjessä. Laitavasemmistoon tai oikeistoon itsensä mieltävissä laskua.
63 prosenttia suomalaisista ilmoittaa luottavansa useimpiin uutisiin, laskua edellisvuoteen neljä prosenttiyksikköä. Raportissa ennakoidaan, että myös perinteisten uutisbrändien on syytä varautua luottamuksen laskuun, vaikka tilanne on hyvä.
Nuoret luottavat vähemmän kuin iäkkäämmät. Naiset luottavat merkittävästi enemmän kuin miehet, mikä eroaa kansainvälisestä vertailusta, jossa sukupuolieroa ei ole.
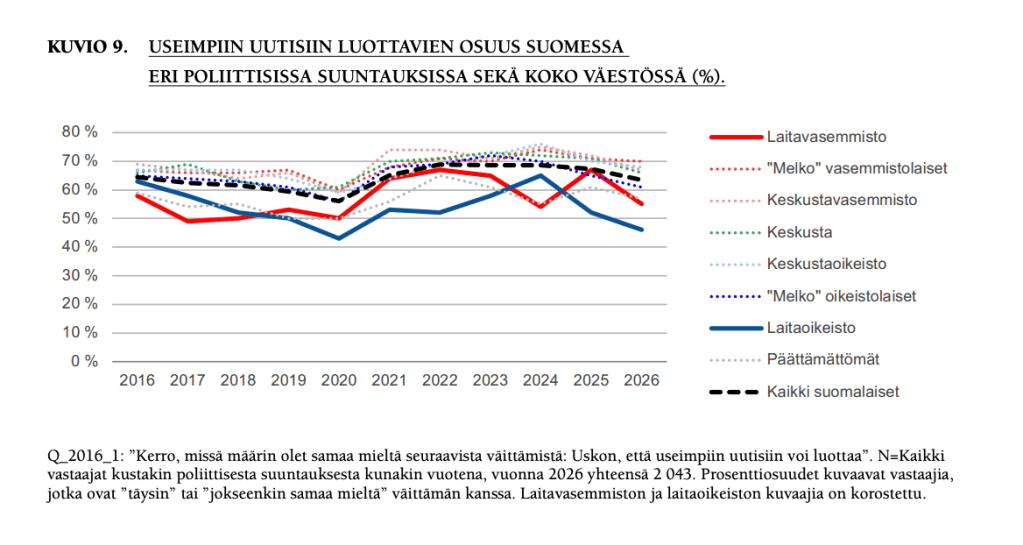
Kun katsotaan aatteellisesta kulmasta, luottamuksen lasku on suhteellisesti suurinta itsensä joko laitavasemmistoon tai laitaoikeistoon mieltävissä.
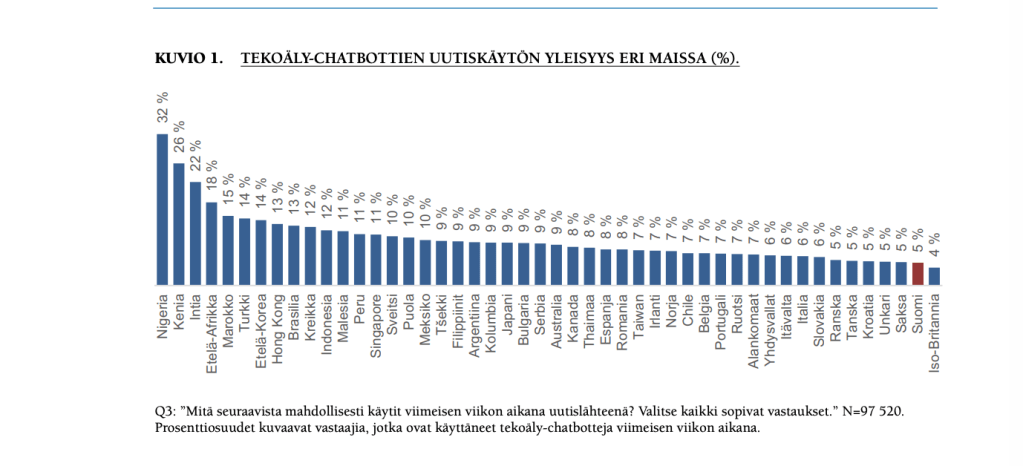
2)Suomessa tekoälypalveluiden käyttö uutislähteenä on kasvanut hieman, mutta yhä pientä ja pienempää kuin monessa muussa maassa (n. 5 % on käyttänyt niitä uutisten etsimiseen edeltävän viikon aikana, edellisvuoden luku oli 3 %). Niiden käyttö uutislähteenä on yleisintä alle 35-vuotiaissa miehissä.
Huomionarvoista on, että suomalaiset tekoälykäyttäjät maksavat verkkouutisista lähes kaksinkertaisesti muuhun väestöön verrattuna.
Kiinnostavaa on myös, että suomalaiset klikkaavat (tai ainakin kysyttäessä kokevat klikkaavansa) tekoälyn tarjoamia linkkejä alkuperäisiin uutislähteisiin kansainvälisesti vertailtuna harvoin. Raportin mukaan uhkakuvana on, että jos tekoälyn uutiskäyttö yleistyy, uhkaa uutismedian verkkoliikenne vähentyä enemmän kuin monessa muussa maassa.
Raportissa arvioidaan, että uutisten kulutus tekoälypalveluiden tulee myös Suomessa kasvamaan varsinkin, jos niistä tulee luotettavampia. Intiassa ne ovat jo ohittaneet radiolähetykset tärkeimpänä uutislähteenä.
Tekoälyä suomalaiset käyttävät kuitenkin muuten laajasti.
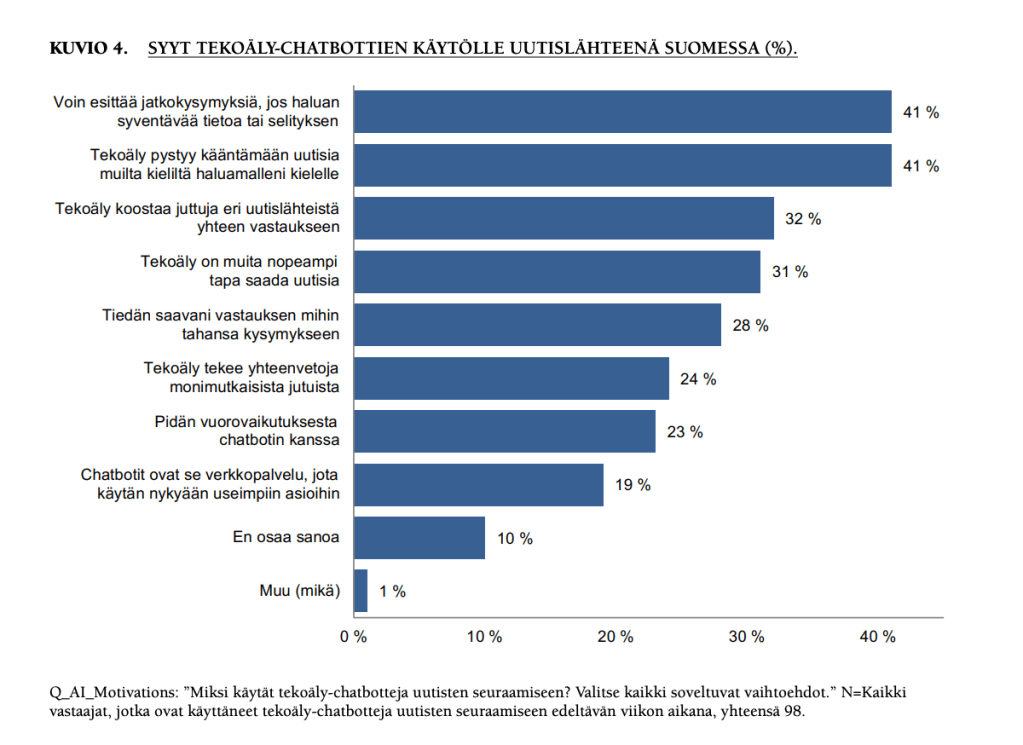
Yleisimmät syyt tekoälypalveluiden käytölle uutislähteenä on suomalaisten mielestä mahdollisuus esittää jatkokysymyksiä, kääntäminen sekä mahdollisuus koosteen saamiseksi yhteen vastaukseen.
Isossa kuvassa Suomessa tekoälypalveluiden uutiskäyttö on toiseksi vähäisintä tutkimuksen yli 40 maasta.
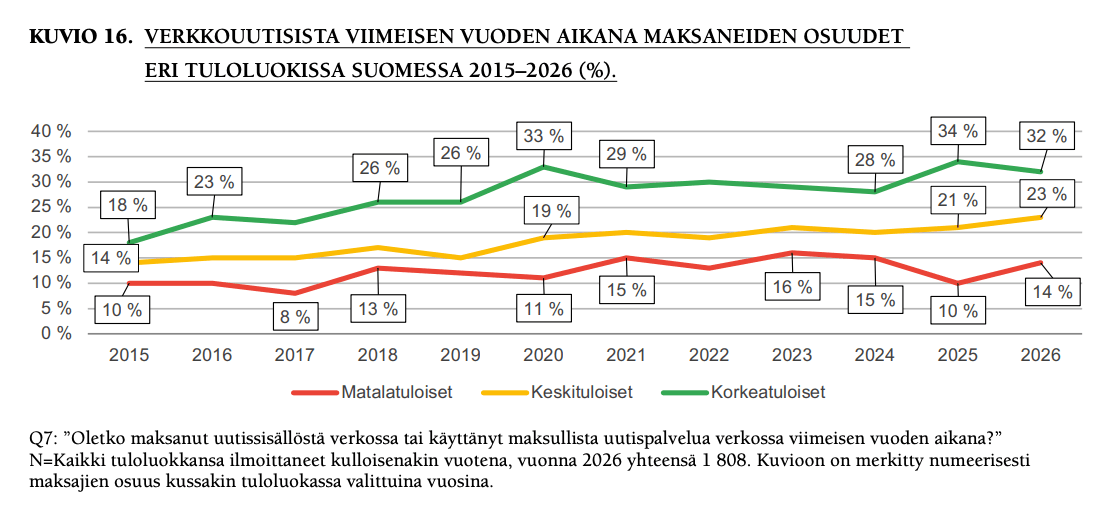
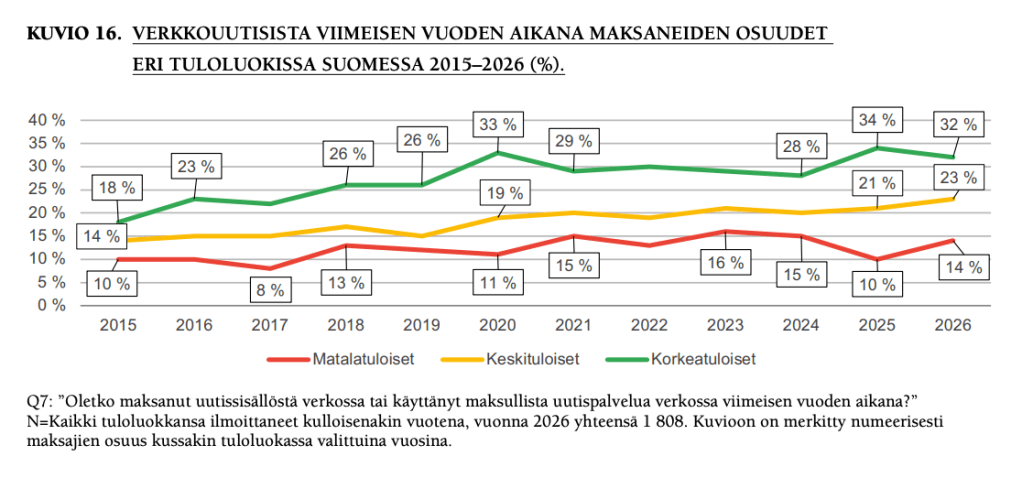
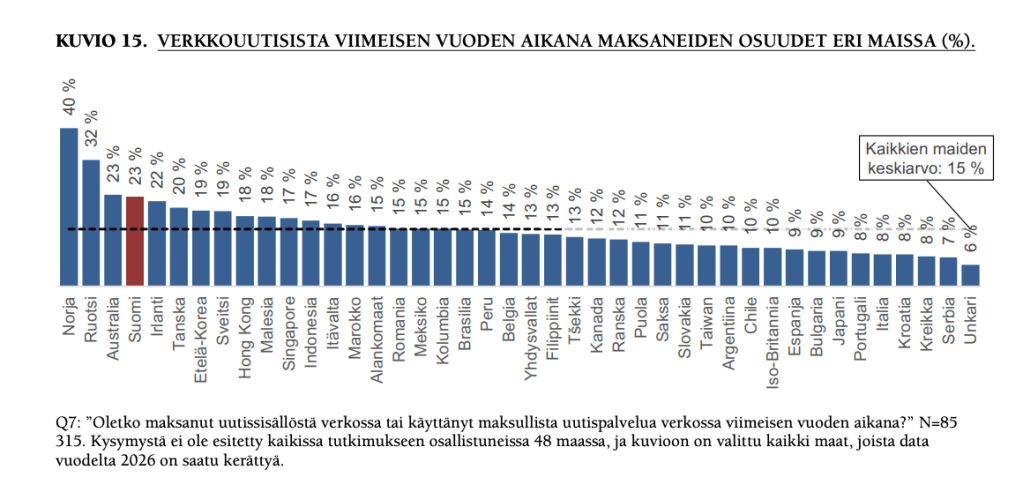
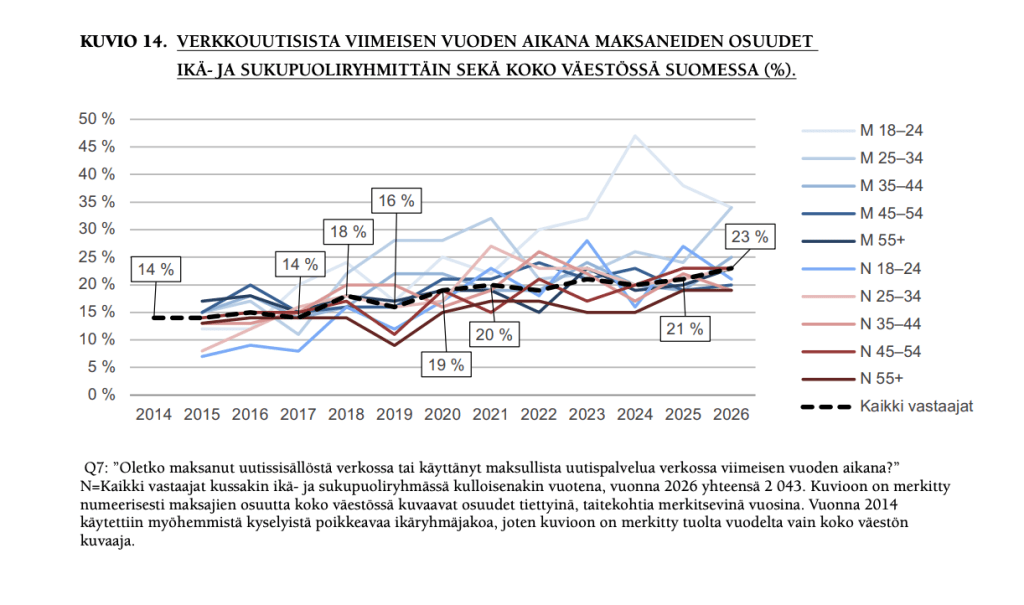
3) Verkkouutisista maksaneiden osuus kasvaa(vähän, mutta kasvaa). 23 prosenttia kertoo maksaneensa verkkouutisista viimeisen vuoden aikana (edeltävänä vuonna 21).
Suomalaisten maksuhalukkuus on tutkituista maista kolmanneksi korkein, eli voisi ajatella, että potentiaaliakin vielä riittää.
Omaan silmään kiinnostava detalji on, että matalatuloisten verkkouutisista maksamisessa on tapahtunut neljän prosenttiyksikön hyppäys ylöspäin vuodessa, toki vuosi 2025 näytti olevan jonkinlainen poikkeus (10), kun edellisvuosina taso on ollut 11-16 prosentin luokkaa.
Iso kuva näyttää siltä, että verkkouutisista maksamisesta alkaa Suomessa tulla ”valtavirtainen tapa kuluttaa uutisia”, kuten raportissa todetaan.
Raportin mukaan alle 35-vuotiaiden joukossa ”identiteettiin ja yhteiskunnalliseen vaikuttamiseen liittyvät syyt ovat yleisempiä kuin vanhempien parissa: he maksavat uutisista, koska samastuvat uutisten tuottajaan ja koska haluavat tukea journalismia ja sen saatavuutta yhteiskunnassa”.
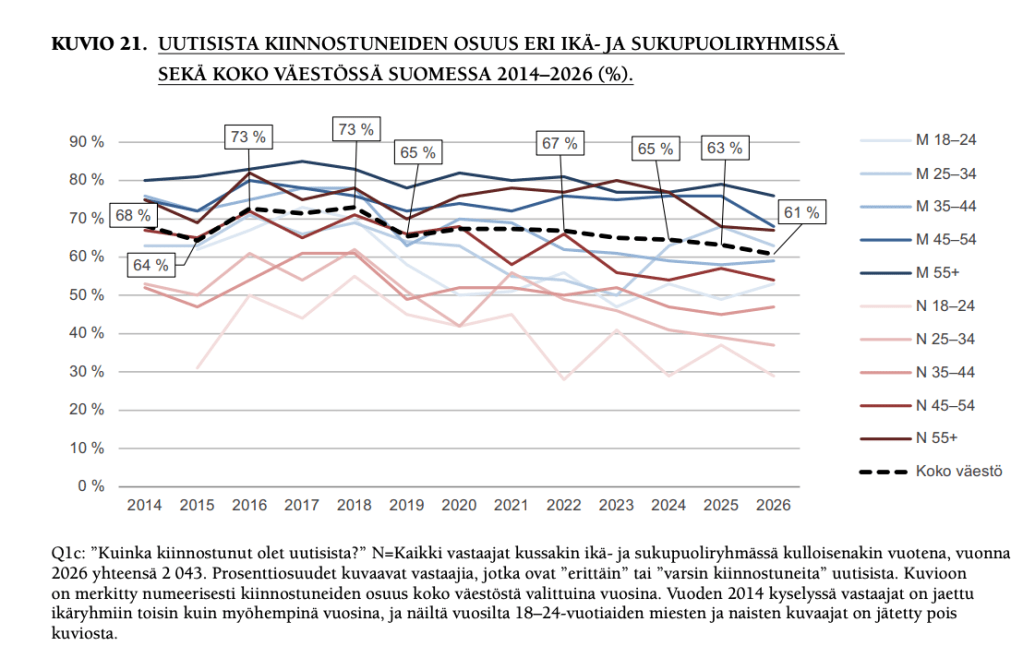
4)Vaikka verkkouutisista maksaminen on kasvanut, kiinnostus uutisia kohtaan yleisesti laskee, uutisten aktiivinen välttely yleistyy ja yhä useampi etsii uutisensa muualta kuin perinteisestä mediasta.
Uutisia usein välttelevien osuus on Suomessa seitsemän prosenttia. Se on kaksinkertaistunut vuodesta 2017. 31 prosenttia välttelee vähintään joskus (nousua neljä prosenttiyksikköä). Raportti summaa, että syyt tauon tarpeeseen voivat olla joko kognitiivisia (uutisväsymys) tai emotionaalisia (uutisten aiheuttamat negatiiviset tunteet). Raportissa todetaan, että uutismedian yksi suurimmista tulevaisuuden haasteista on juuri kasvava uutisväsymys.
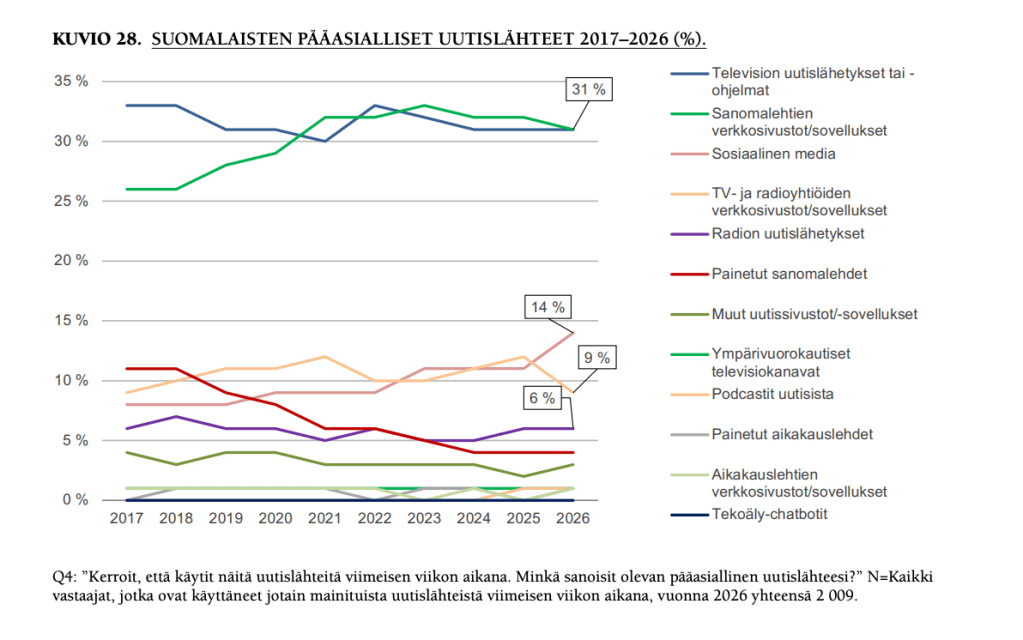
Sosiaalisen median rooli suomalaisten pääasiallisena uutislähteenä pompsahti taas ylöspäin (10 % -> 14 %). Podcastien rooli pääasiallisena uutislähteenä puolestaan tuli samaa luokkaa alaspäin.
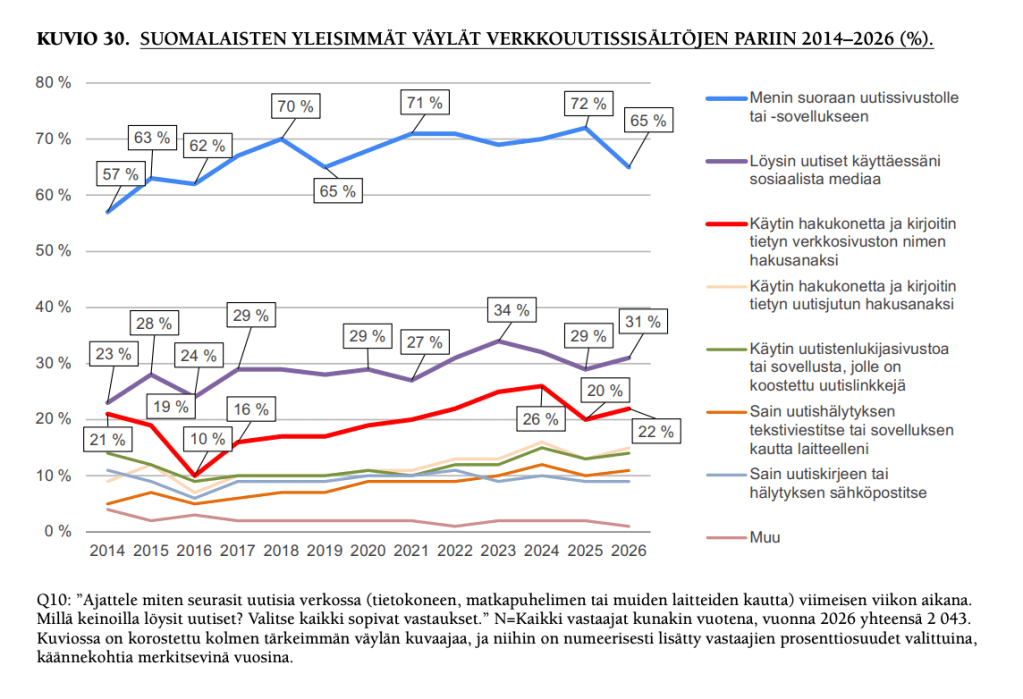
Maailmanlaajuinen trendi on, että suora liikenne uutissivustoille laskee. Tämä näkyy myös kyselytutkimuksessa: niiden suomalaisten osuus, jotka kertovat viimeisen viikon aikana menneensä suoraan uutissivustolle tai sovellukseen, on laskenut 65 prosenttiin 72:sta.
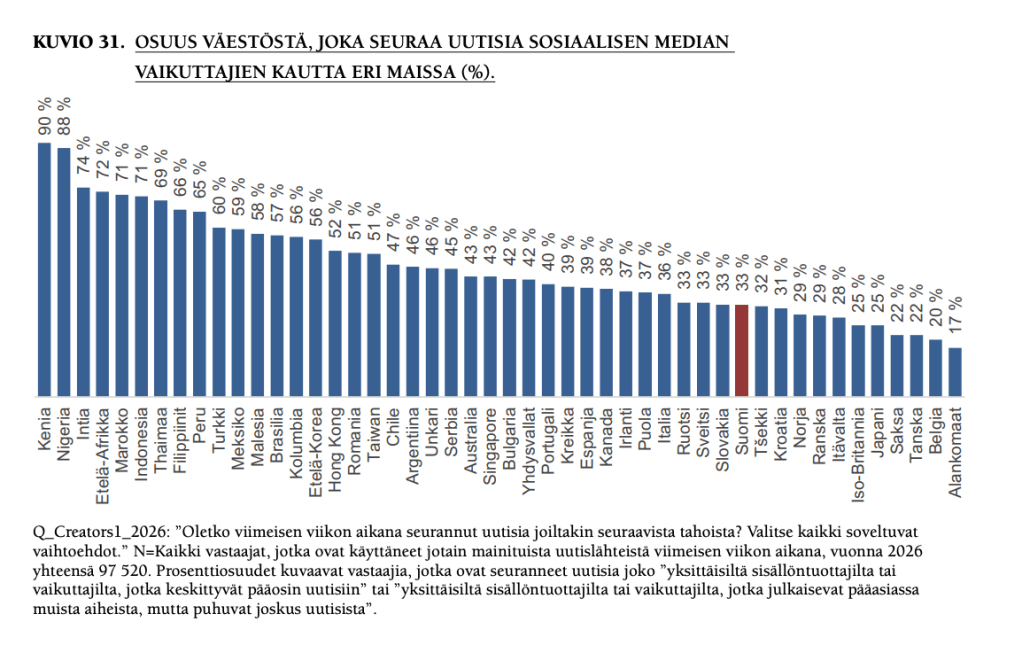
5)Suomessa joka kolmas seuraa uutisia sosiaalisen median vaikuttajien kautta. Tämä on kiinnostava tulos. Harva suomalainen kuitenkin kokee vaikuttajasisältöjen yksin riittävän tyydyttämään heidän tiedontarpeitaan (vain 8 %).
Vaikuttajasisältöjen kuluttajista enemmistö on sitä mieltä, että ne ovat jokaisella tarjotulla mittarilla samantasoista tai parempaa kuin perinteisen uutismedian sisältö. ”Selkein etumatka on aitouden, viihdyttävyyden, ymmärrettävyyden ja samastuttavuuden saralla.”
Alle 35-vuotiaista miehistä vaikuttajien kautta seuraa uutisia peräti 69 prosenttia ja samanikäisistä naisistakin enemmistö (53 %).
Raportin mukaan vaikuttajauutisilla on alle 35-vuotiaiden keskuudessa Suomessa parempi viikkotavoittavuus kuin millään perinteisellä medialla.
Vaikuttajia koskevat osuus oli kyselytutkimuksessa nyt uusi, eli aiheesta ei ole kysytty aikaisemmin. Kansainvälisesti vertailtuna Suomessa kulutetaan uutisia vaikuttajien kautta vielä melko vähän.
Oma kysymyksensä on, minkä asian kukakin kysyttäessä mieltää ”uutiseksi”.
Reuters-instituutin Digital News Report -tutkimus vertasi uutisten käyttöä 48 maassa. Suomessa kyselyyn vastasi noin kaksituhatta henkilöä alkuvuodesta 2026.Maaraportin löydät siis täältä.
Koosteitani edellisvuosien vastaavista raporteista voit lukea täältä.
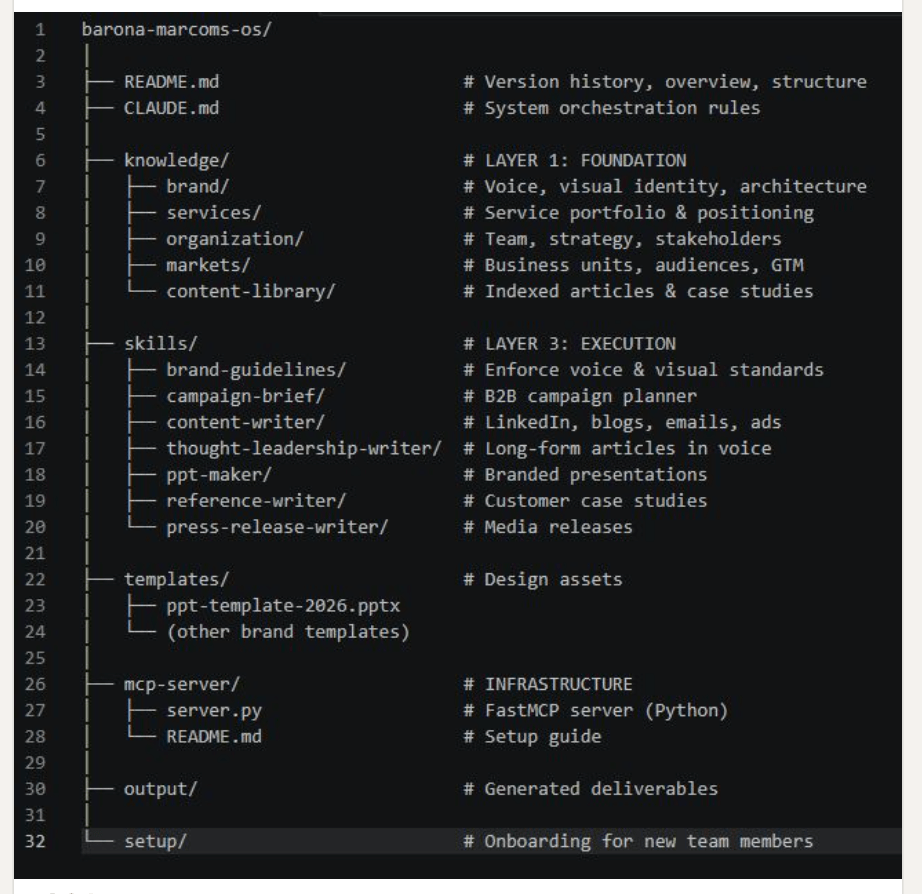
Karkeistettu kuvaus Claude-rakenteestani. Se on yhdistelmä siviili- ja työtarpeita.
Aloitin reilu viikko sitten uudessa työssä toimituksellisen AI-kehityksen parissa. Uudessa työssä on aina paljon tutustuttavaa – ihmisiä, prosesseja, substanssia. Mutta tekoälyaikana on yksi asia, jonka voi tehdä hieman eri tavalla kuin ennen: rakentaa itselle kontekstin eli tavallaan pysyvän asiayhteyden tai työmuistin, joka on automaattisesti saatavilla joka kerta kun avaat uuden keskustelun. Yhteisesti tekoälylle jaetut ohjeet, ovat ne tallessa sitten koodareiden varastointipalvelu Githubissa, omalla koneella tai muualla, tekevät tuloaan myös mediaan. Kirjoitin aiheesta laajemmin aiemmin tässä blogissa.
En ole tässä mikään megaekspertti. Rakennan samalla kun opin, kokeilen, korjaan ja muutan lähestymistapaa sitä mukaa kun ymmärrys kasvaa. Tämä kirjoitus on siis pikemminkin väliraportti kuin ohje kenellekään. Nyt oli tilaisuus aloittaa tämä aiempien puuhastelujen pohjalta puhtaalta pöydältä, koska työn mukana vaihtuu luonnollisesti myös tekoälylle annettava työn konteksti.
Perusongelma on se, että Claude, kuten useimmat tekoälypalvelut, aloittavat jokaisen keskustelun tyhjästä. Vaikka olisit yleisasetuksiin jotain kuvausta itsestäsi ja toimintatavoistasi laittanut, se ei oikeasti kovinkaan hyvin muista, miten missäkin tilanteessa toimit saati mikä asia jäi mihinkin vaiheeseen. Käy työlääksi selittää konteksti aina alusta osittain tai kokonaan.
Itselleni ratkaisuksi rakensin pysyvän ”muistin” tiedostoihin, jotka Claude saa käyttöönsä automaattisesti aina kun avaat uuden keskustelun. Samalla tästä rakentuu minulle päivittyvä tutustumispaketti uuteen työhön.
Käytän Claudea kahdessa eri ympäristössä, joilla on hieman eri käyttötarkoitus: Claude Desktop on päivittäinen työassistentti, käytännössä Macille lataamani sovellus. Claude Code on teknisempi työkalu koodaamiseen ja mm. automatisointiin, jota voi käyttää myös Desktopin kautta, mutta pidän usein enemmän Pääte- eli terminaalikäyttöliittymästä. Muisti täytyy käytännössä rakentaa molempiin erikseen, koska ne yhdistyvät ulkoisiin palveluihin kuten sähköpostiin, kalenteriin, dokumentteihin tai viestintäkanava Slackiin, hieman eri tavoin ja eri laajuudella. Sisältö on kuitenkin pitkälti sama.
Claude Desktop: työasiat samaan projektiin
Claude Desktop on sovelluskäyttöliittymä, jota käytän päivittäiseen työhön: kirjoittamiseen, suunnitteluun, tiedonhakuun. Siellä muisti rakentuu Projects-ominaisuuden varaan. Loin projektin nimeltään Kaikki työasiat, johon liitin keskeisiä työdokumentteja (tavoitteet, linjaukset, organisaatiomalli, yhteisten työtapojen viitekehys) Project Files -osioon. Project Instructions -kentässä on tiivistetty konteksti: kuka olen, miten haluan vastaukset, mistä Claudeen kytketyistä liittimistä se hakee tietoa tarvittaessa (esim. Slack). Tähän projektiin kytketyt keskustelut saavat siis kontekstin automaattisesti, eikä tarvitse selitellä lähtötilannetta joka kerta uudestaan. Olen nähnyt tätä samaa fiksua työtapaa myös ChatGPT:n kanssa varsinkin ihmisillä, jotka eivät halua käyttää komentorivityökaluja. Lisään tänne projektitiedostoihin myös tietyt taidot eli skillit, vaikka voisin sisällyttää ne myös yleisasetuksiin.
Claude Code: sama asia hieman eri tavalla
Claude Code on komentorivityökalu, joka on periaatteessa suunnattu koodaamiseen ja teknisempiin tehtäviin, mutta sillä voi tehdä käytännössä kaikkea. Desktop-sovelluksen erillinen Cowork-ominaisuus – työkalu ei-kehittäjille tiedostojen ja tehtävien automatisointiin – on jäänyt itselläni käyttämättä, koska huomaan tekeväni samat asiat aina Claude Coden puolella. Siellä muisti toimii CLAUDE.md-nimisen tiedoston kautta, jonka työkalu lataa automaattisesti jokaiseen keskusteluun. Käytännössä siellä on sama sisältö kuin Desktop-projektissa.
Clauden yleisrakenteeni on karkeasti kuvattu tämän blogin lähtökuvassa.
Obsidian muistiinpanoja terävöittämään
Obsidian on muistiinpanosovellus, jossa kaikki tieto tallennetaan tavallisina tekstiä sisältävinä markdown-tiedostoina minun tapauksessani omalle koneelle yhteen kansioon. Pidän siellä omia muistiinpanoja, ideoita ja havaintoja, joita en halua jakaa mihinkään järjestelmään. Claude Code pääsee lukemaan tätä Obsidianin kielellä ”holvia” suoraan koneelta, joten muistiinpanot ovat käytettävissä ilman että niitä tarvitsee kopioida minnekään.
Obsidian ei välttämättä kaikessa työssä tuo kauheasti lisäarvoa, mutta siitä on siviili-Claudessani ollut sen verran apua kokonaisuuksien välisten yhteyksien hahmottamisessa, että olen pitänyt sen käytössä.
Siviilipuolella Obsidian-tiedot päivittyvät automaattisesti Drive-kansiooni. Tällä tavoin voin pyytää halutessani Claudea lisäämään sinne tietoja myös tien päällä ollessani, Clauden kännykkäsovelluksellani.
Työpäiväkirja M365:ssä
Pidän Word-muotoista työpäiväkirjaa Microsoftin pilvipalvelussa (SharePoint), johon pääpiirteissään kirjaan päivän tapahtumat ja ajatukset. Claude Desktop osaa hakea sen suoraan Microsoft 365 -liittimen kautta halutessani. Sama onnistuu Claude Codessa. Käytännössä siis työdokumentit antavat pysyvän kontekstin ja työpäiväkirja tuo mukaan sen mitä on tapahtunut tänään tai tällä viikolla.
Nähtäväksi jää, miten pieteetillä jaksan päivittää työpäiväkirjaa, mutta ainakin alkuvaiheessa aion näin tehdä, ihan oman ajattelunikin jäsentämiseksi.
Päivityslogiikka kuntoon
Claude on ohjeistettu muistuttamaan, jos se keskustelussamme havaitsee tiedon, joka vaikuttaa vanhentuneen. Desktop ja Code voivat lukea samoja tiedostoja, joten päivitys riittää tehdä kerran kunhan huolehtii, että molemmat on ohjattu samaan lähteeseen. Automaattista synkronointia näiden kahden välillä ei ole.
Mitä enemmän tekoälyä käytetään tiimeissä ja organisaatioissa, sitä tärkeämmäksi nousee se, että yhteisesti jaetut dokumentit ovat kunnossa, olivat ne sitten suunnitteludokumentteja, prosessikuvauksia tai muuta.
Tämä sanottua, erilaisista syistä johtuen näiden ohjeiden ajan tasalla pitäminen ei aina ole ihan helppo homma. Usein esimerkiksi tietoturvasyistä on fiksua antaa joillekin liittimille vain lukuoikeus eikä kirjoitusoikeutta, mikä toisaalta voi hidastaa tekemistä, kun et voi sanoa vaikkapa Claudelle suoraan, että lisää sinne-ja-sinne sitä-ja-sitä.
Yksi asia on ollut selvästi ongelma, tai ainakin sekoittanut omaa päätäni. Minulla on erikseen työ-Claude ja siviili-Claude. Siviilipuolella ei ole työasioita, se on selkeä raja, mutta osin nämä menevät ristiin. Toisaalta oma Claudeni on kytketty omaan Driveeni ja omaan Slack-työympäristööni, joihin en työ-Claudea haluaisikaan kytkeä. Jää nähtäväksi, miten näiden kahden Clauden rinnakkaiselo tulee toimimaan. Toistaiseksi ratkaisuna on ollut pitää siviili-Claude joskus auki työkoneen ”kakkosselaimella”, jos sitä satun tarvitsemaan. Samassa Desktop-sovelluksessa ei voi olla kahta profiilia auki yhtä aikaa.
Viikon kokeilujen perusteella tämä rakenne toimii ehkä paremmin kuin odotin sekä Desktopissa että Codessa, mutta se vaatii kurinalaisuutta eli osa tiedoista pitää ajan tasalla itse ja lisätä uutta sitä mukaa kun sitä tulee. Se toki hieman auttaa, jos ohjeistat Claudea muistuttamaan tästä asiasta soveltuvissa kohdissa.
So last week we wrapped up our five months long AI Journalism Lab: Builders at Craig Newmark Graduate School of Journalism at CUNY (City University of New York), in partnership with Nordic AI Journalism.
Shoutout especially to Aldana Vales and Marie Gilot for organizing this so professionally, and of course to the whole amazing cohort of 24 people and our coaches and speakers such as Nikita Roy, Lukas Nielsen, Kasper Lindskow, Joe Amtidis, Upasna Gautam, Elite Truong and others.
The curriculum of the program consisted of these themes:
Designing AI products for newsrooms
Prototyping with No-Code Tools
(Un)Structured data, Semantic Search & RAGs
AI Agents & Autonomous Workflows
Measurement & Ethics in the Product Lifecycle
Launching and Sustaining Products in an AI Future
Each one of us built a final project during these five months, from which you will hear a bit more later on. Mine unfortunately is not public information since I’ve just changed jobs but what I can tell is that it is a python-based tool that has to do with videos, it was built with Google Antigravity, and I’m really happy with how it turned out.
What did I learn?
A whole lot of new stuff, starting from how to actually build a good PRD, product requirement document for AI to use. I will also definitely use several of the newsroom spesific frameworks we came across on the course, like one that helps evaluate and prioritize AI products or features from five different perspectives simultaneously. All in all, I’d say I learned a lot from…
How to identify whether a problem is genuinely an AI problem
How to prioritize AI development by value and feasibility
How to build prototypesfast
How the underlying data and AI infrastructure works and where it typically breaks
How to evaluate an AI product’s value across multiple dimensions simultaneously
How to deal with the fact that building the tools is not usually the hardest part (but scaling)
So why was this the best AI course I ever had?
It was both strategic and concrete. Spesific newsroom context, really hands on. Excitement but not overhype. Realism.
What’s also nice is that our cohort will continue to have discussions in our joint Slack group that will remain after the course as well.
So, if you have the possibility to attend some of CUNY’s offerings, I highly recommend. Check it out here.
Tapahtuman sessioiden nimiä (kuvitus: Gemini). Olen jäsentänyt 41 sessiota tässä kirjoituksessa seitsemän teeman alle lukemisen helpottamiseksi.
Kolme ihmistä rakentaa journalistista organisaatiota, jolla on heidän lisäkseen kolme nimettyä Claude-agenttia “co-founderina” — kukin omalla roolillaan ja vastuualueellaan (Ryan, Justin, Liz).
Lehti, joka kehitti kolmessa kuukaudessa yli sataa lähdettä automaattisesti seuraavan työkalun toimittajille: RSS-syötteistä somen kautta erilaisiin hallinnon asiakirjoihin. Filosofia työkalun taustalla on “vibe engineering”.
Poliisiradion kaikki keskustelut kulkevat Raspberry Pi -tietokoneen kautta ja systeemi hälyttää Slackiin, jos jotain uutisarvoista tapahtuu.
Voittoa tavoittelemattoman organisaation tutkivat toimittajat löysivät parhaan tekoälytyökalunsa, ja se ei ole tekoälychat, vaan Google Sheets.
Milloin rakentaa tekoälytyökalu itse, milloin ostaa se ulkoa ja milloin olla tekemättä mitään? Tähän löytyy useampikin malli uutismediasta.
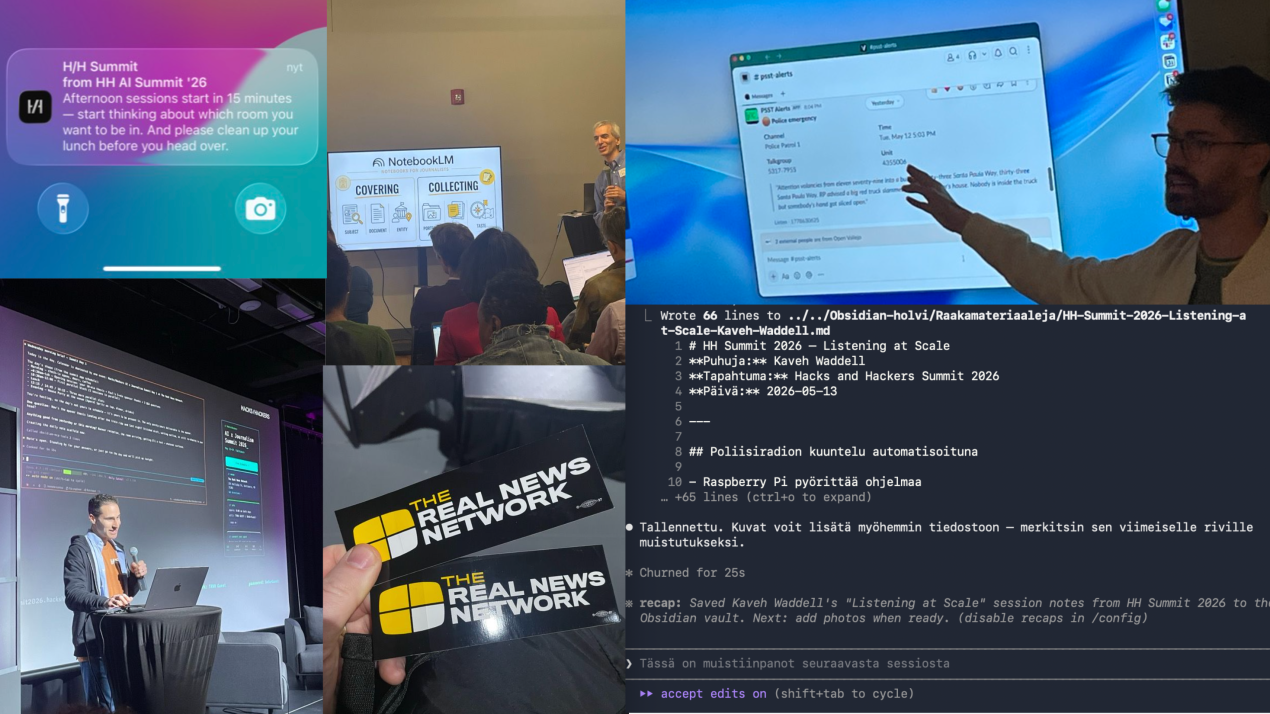
Muun muassa nämä esimerkit tulivat vastaan kahden päivän aikana Hacks and Hackers AI × Journalism Summit -tapahtumassa Baltimoressa 13.-14. toukokuuta 2026.
Tapahtuman anti oli sen verran konkreettinen, että päätin purkaa kaikki yli 40 sessiota lyhyesti tähän kirjoitukseen. Ne joissa olin itse mukana tekemässä muistiinpanoja, olen avannut laajemmin. Otsikkoteemoitus on minun, jotta kokonaisuutta olisi helpompi hahmottaa.
Tapahtumaan kokoontui kaikkiaan kolmesataa journalistia, kehittäjää ja median ammattilaista.
TEEMA 1: Milloin ostaa, milloin tehdä itse ja milloin luopua koko ideasta?
SESSIO: Build, Buy, or Ignore: A Framework for Prioritizing AI in News Organizations
Shira Center (Boston Globe Media), Aimee Rinehart (Frontier Collective), Chase Davis (Local Angle), Paris Brown (Baltimore Times)
”Voisiko AI auttaa tässä?”. Jokainen on kuullut tämän kysymyksen organisaatiossaan. Session pointti oli, että kaikille ei voi vastata kyllä, eikä pidäkään. Sessio tarjosi mm. kolmivaiheisen mallin, jonka avulla uutisorganisaatio voi päättää, kannattaako jokin AI-hanke toteuttaa itse, ostaa valmiina tuotteena vai jättää kokonaan väliin. Mallin kolme vaihetta ovat Impact (edistääkö se tavoitteitasi), Risk (miten huonosti käy jos kaikki menisi pieleen) ja Commonality (ovatko muutkin tässä samassa tilanteessa). Hyvä esimerkki medioiden haasteista käytännössä: Boston Globe rakensi 2023 itse Slack-botin otsikkoehdotuksia varten, 2024 markkinoille tuli valmistuotteita jotka tekivät saman asian, ja 2025 Globen julkaisujärjestelmän sisälsi kaikki samat ominaisuudet valmiina.
Omat muistiinpanoni yo. sessioon:
Konkreettisin esimerkki tuli Baltimoresta: piskuinen kolmen hengen paikallislehti rakensi AI-työkalun, joka auttaa toimittajaa etsimään uutisaiheita ja tuottaa artikkeliluonnoksen suoraan julkaisujärjestelmään. Koko työkalu maksoi alle 2 000 dollaria ja ostettiin ulkoiselta kumppanilta, koska se oli käytännössä ainoa vaihtoehto. Kaikki meni hyvin. Panelisti Paris Brownin vinkki oli hyvä: “Testaa jokainen työkalu sillä metodilla, että mikä on pahinta mitä voi tapahtua, jos kaikki menee pieleen. Useimmiten ei kovinkaan pahaa.”
SESSIO: Building Better Products With AI
Aldana Vales (CUNY), Scott Klein, Julia Moak (Greenpointers), Kalle Pirhonen
Olin itse mukana tässä paneelissa osana AI Builders -kurssini lopputyötä sivuavaa keskustelua. Sessio käsitteli sitä, miten tekoälyä voidaan käyttää tuotteiden rakentamiseen tavalla, joka on aidosti hyödyllinen, luotettava ja yleisöjen tarpeisiin vastaava.
SESSIO: Smart, Confident, and Wrong: Designing Responsible A.I. Tools in the Newsroom
Dylan Freedman & James O’Toole (The New York Times)
New York Timesin tuotekehitystiimi purki ongelman, joka on tuttu kaikille tekoälyn kanssa työskenteleville: AI-järjestelmät kuulostavat vakuuttavilta myös silloin, kun ne ovat väärässä. Sessiossa kerrottiin, miten vastuullinen tuote- ja käyttöliittymäsuunnittelu voi auttaa. Käytännön esimerkit tulivat NYT:n omista sisäisistä työkaluista, kuten Cheatsheetistä, jolla käsitellään laajoja datamassoja strukturoidusti.
SESSIO: Are U.S. Journalists Getting Lapped in the AI Race?
Amy Mitchell (Center for News, Technology & Innovation), Akintunde Babatunde (Centre for Journalism Innovation and Development), Gordon Saft (Rest of World)
Sessiossa käsiteltiin tutkimusta, joka vertailee tekoälyn käyttöönottoa uutisorganisaatioissa eri maissa.
SESSIO: The Blueprint for Success: How to Get Buy-In and Build AI Systems That Actually Work
Ryan Struyk (CNN), Heather Ciras McCarthy (Boston Globe), Rubina Fillion (The New York Times), Ole Reissmann (SPIEGEL-Group)
Monet toimitukset kokeilevat tekoälyä, mutta harvat onnistuvat muuttamaan kokeilut järjestelmiksi, joita toimittajat käyttävät paljon ja säännöllisesti. Paneeli käsitteli sitä, miten toimittajat, insinöörit ja tuotejohtajat saadaan samalle aaltopituudelle. Yhteinen teema oli se, ettei pelkkä tekninen toteutus riitä: muutosjohtaminen, luottamuksen rakentaminen ja yhteiset käytännöt ovat yhtä tärkeitä kuin itse työkalut.
TEEMA2: Tekoäly silmäparina — signaaliseuranta ja uutisten löytäminen
Listening at Scale: Building AI Tools for Audio and Video Monitoring
Kaveh Waddell (Verso)
Toimittajat hukkuvat audioon ja videoon, jota he eivät pysty seuraamaan: kaupunginhallitusten kokoukset, poliisiradiot (Yhdysvalloissa), podcastit ja suoratoistosisällöt. Waddell esitteli, miten AI-järjestelmät pystyvät kuuntelemaan ja katsomaan puolestasi. Käytännön esimerkkejä oli kaksi: ensimmäisessä poliisiradiota seurataan Raspberry Pi:llä pyörivällä järjestelmällä, joka litteroi jokaisen puhelun automaattisesti ja lähettää hälytyksen Slack-kanavalle vain silloin, kun jotain uutisarvoista tapahtuu. Toinen esimerkki oli työkalu, joka litteroi kaikki Joe Roganin podcastit tekstuaalisesti etsittävään ja vertailtavaan muotoon.
Omat muistiinpanoni yo. sessioon:
Audio ja video ovat yhä alihyödynnetty kulma media-alalla suhteessa tekoälyyn, mistä puhuttiin myös tässä sessiossa.
Waddell korosti, että poliisiradiotyökalu ei ole täydellinen, mutta se on tarpeeksi hyvä säästämään valtavasti aikaa. Waddell nosti esiin neljä keskeistä kysymystä ennen kuin alkaa rakentamaan tällaista monitorointijärjestelmää: reactive vs. proactive (milloin hälytät), human in the loop (missä kohdassa ihminen on mukana), alert vs. synthesis (yksittäisiä hälytyksiä vai yhteenvetoja) ja transcription vs. native input (käytätkö litteroitua tekstiä vai audiota suoraan syötteenä).
Kiinnostavaa tässä sessiossa: pääsimme kokeilemaan Googlen Opalia, jolla voi agenttisesti luoda sovelluksia. Käyttöliittymä muistuttaa hieman n8n- tai Make-automaatioalustoja. Opalia ei toistaiseksi voi käyttää Suomessa:
Google Opal
Building an AI Tool That Finds News Amid the Noise
Peter Rasmussen & Biswajit Ganguly (The Baltimore Banner)
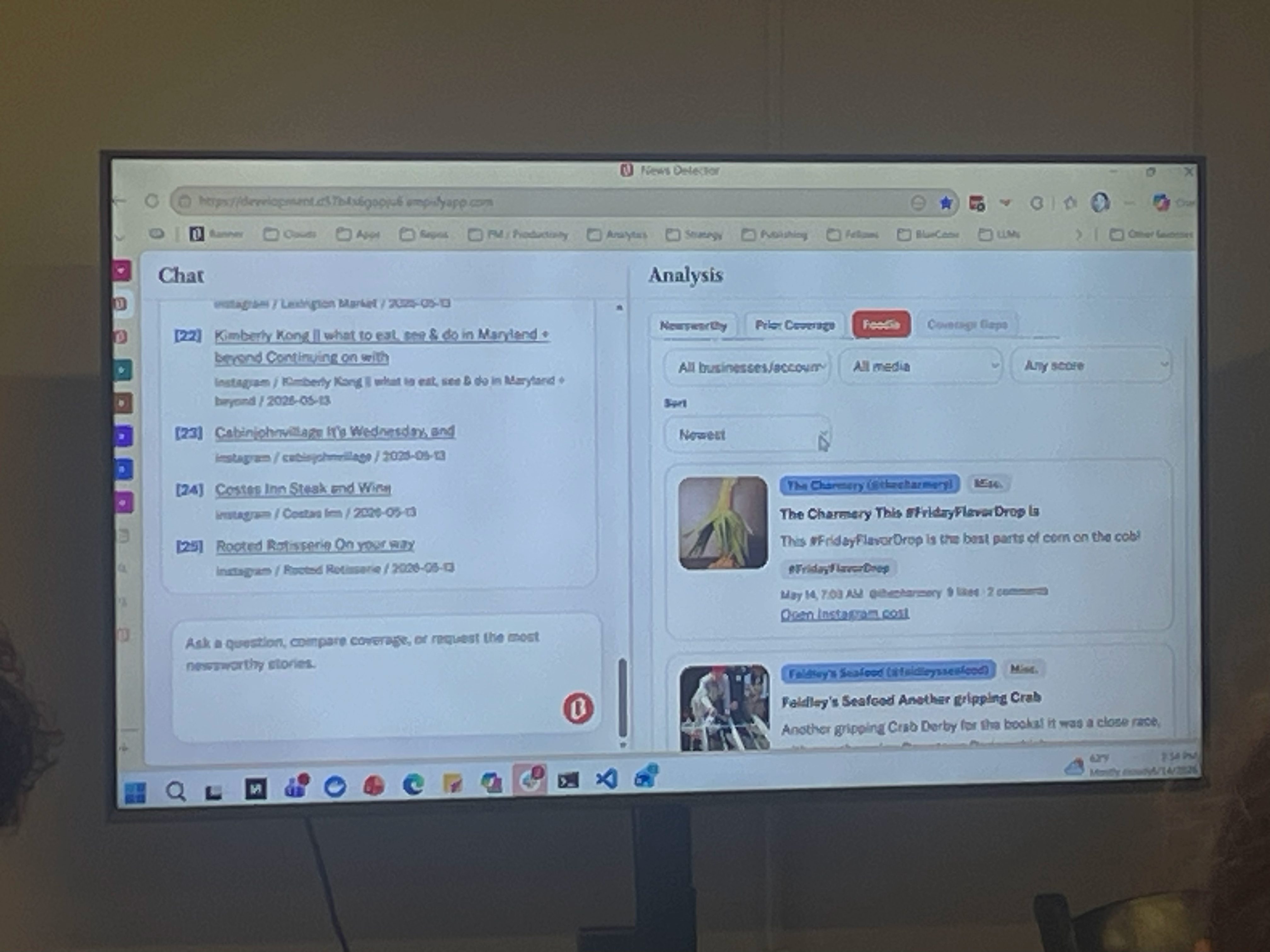
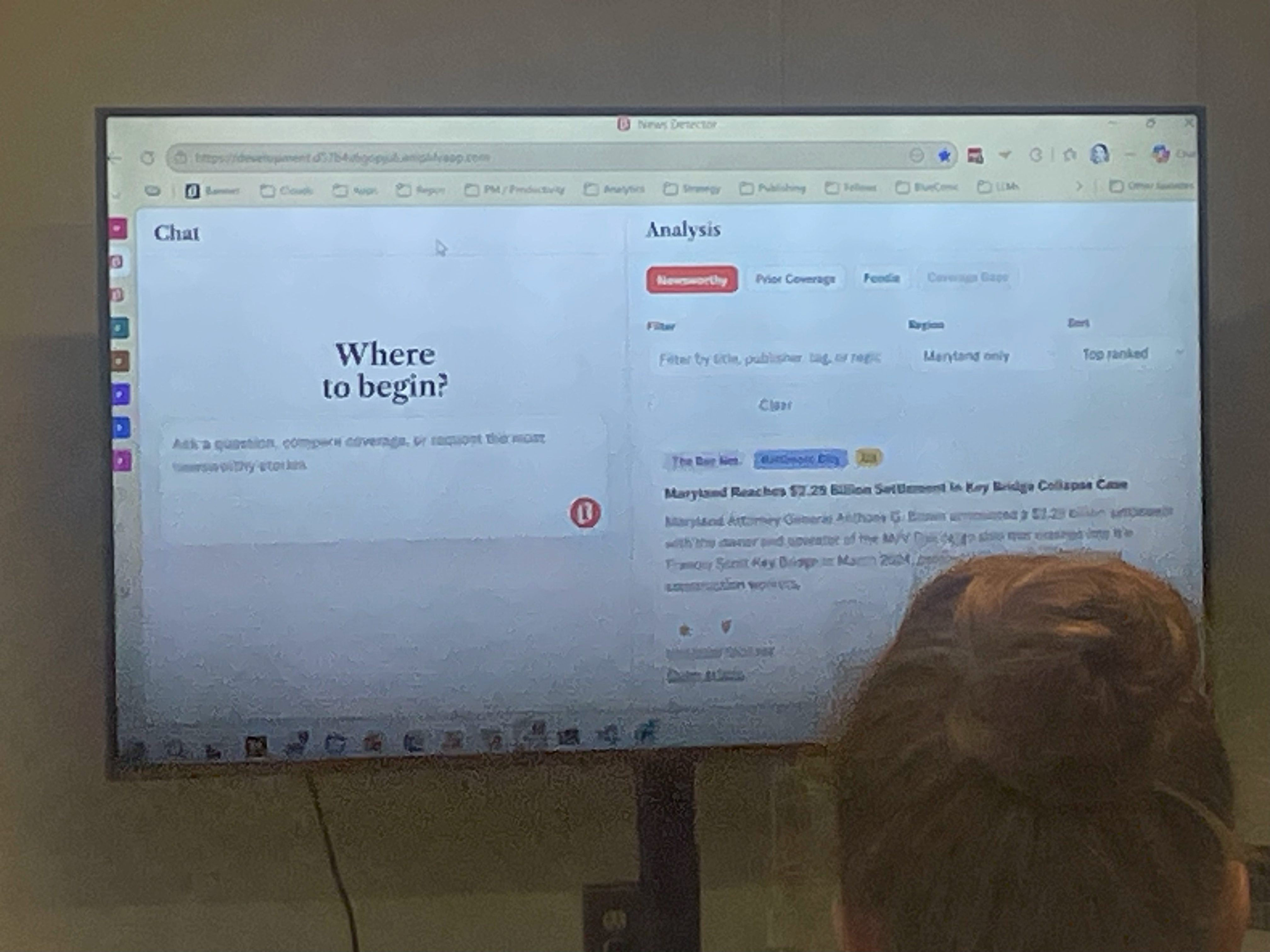
Baltimore Bannerin News Detector -työkalu syntyi käytännön tarpeesta: toimittajat kävivät päivittäin manuaalisesti läpi kymmeniä ulkoisia lähteitä, ja laajentuminen uusille alueille teki siitä pullonkaulan. Ensimmäinen versio oli karsittu: se skreippasi paikallisia sivustoja, pisteytti aiheet ja lähetti ne toimitukselle Excel-tiedostona sähköpostilla.
Omat muistiinpanoni yo. sessioon:
Amerikkalainen Baltimore Banner rakensi kolmessa kuukaudessa vaikuttavan näköisen uutissignaalien seurantatyökalun, jossa on yli sata lähdettä RSS-syötteistä someen ja skreipattuihin sivustoihin. Sen ytimessä on uutisarvopisteytys, joka pohjautuu ihmisten määrittelemiin uutisarvokategorioihin, joiden täsmäävyyttä päivitetään koko ajan tuoreiden esimerkkien pohjalta. Päivitys tarkoittaa käytännössä sitä, että toimittajat antavat säännöllisesti palautetta työkalun arviointikyvystä (peukku ylös tai alas), mikä parantaa sitä vähitellen.
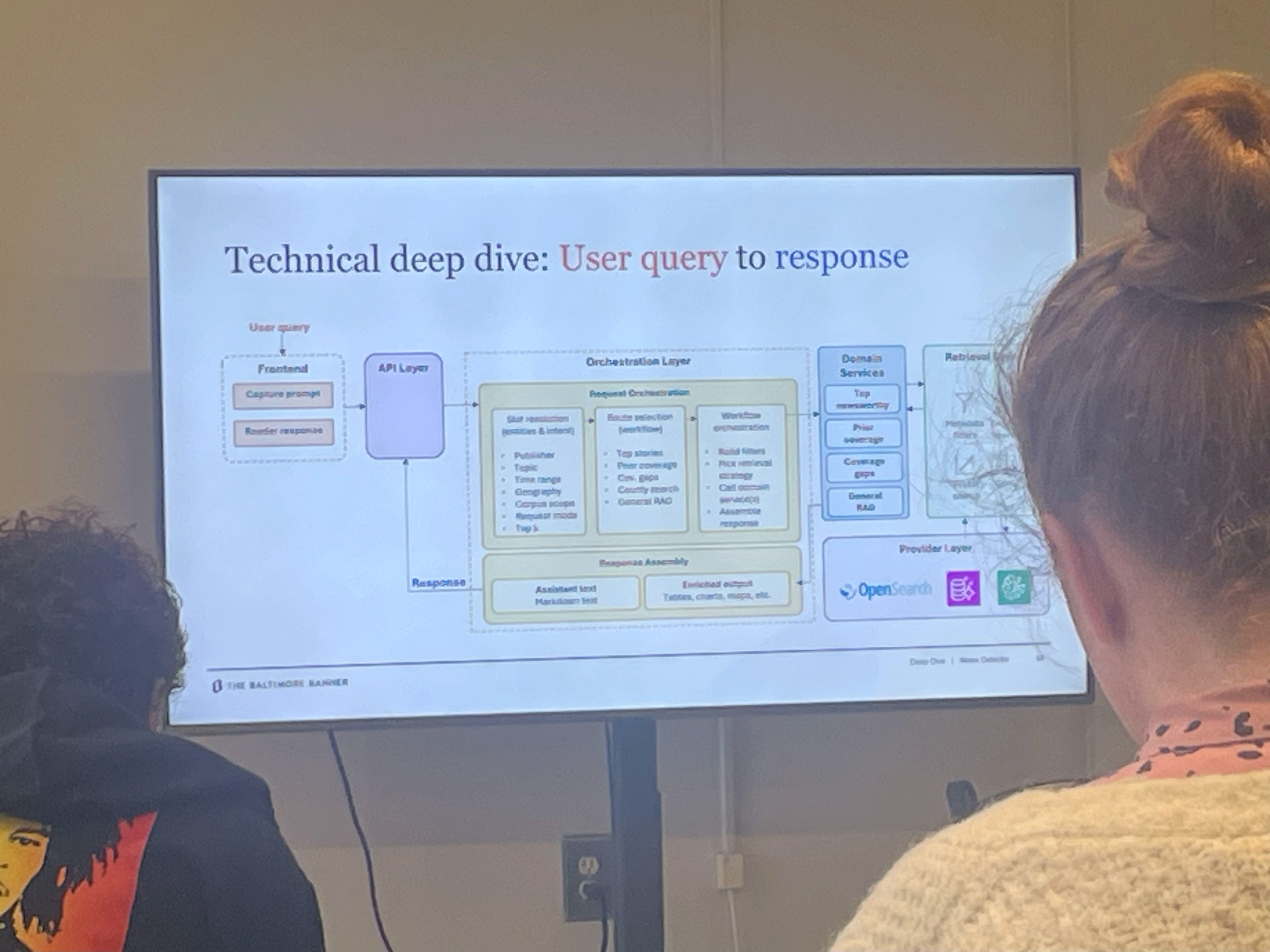
Rautalankaistettuna työnkulku on tällainen:
1. Kerääminen
Kone käy jatkuvasti läpi yli sataa lähdettä — uutissivustoja, somea (somessa hyödynnetään Apifyta), hallinnon asiakirjoja. Se siivoaa datan yhtenäiseen muotoon.
2. Pisteytys
Jokainen artikkeli tai sisältö menee tekoälyn läpi, joka arvioi, onko siinä vaikuttavuutta, konfliktia tai paikallisuutta ja missä määrin. Tekoäly tekee tulkinnan, mutta varsinainen numero lasketaan sääntöpohjaisella koodilla.
3. Haku ja vastaus
Kun toimittaja kysyy jotakin (kuten ”Mitä tärkeää tapahtui tällä viikolla Baltimoressa?”), järjestelmä hakee relevantin materiaalin kolmella tavalla: hakusanoilla, vektorihaulla ja metadatasuodatuksilla. Sitten se kokoaa vastauksen ja näyttää sen chatissa sekä rikastettuna listauksena vieressä.
Omat ajatukseni:
Sivustojen skreippaamisen eettinen puoli ei näytä Yhdysvalloissa lainkaan vaivaavan mediatoimijoita, tuntuu siltä että kaikki tekevät sitä. Tämä yllätti. Somen osalta Baltimore Bannerin työkalu käyttää Apifytä, jonka kanssa ainakin Euroopassa liikuttaisiin vähintäänkin harmaalla alueella. Asian toinen puoli on se, että usea yhdysvaltalaisemedia näyttää ottaneen uutisseurannan automatisoinnissa isoja harppauksia viimeisen vuoden aikana. Sanoisin, että alkavat olla jo paikoin edellä eurooppalaisia.
Baltimore Bannerin työkalun pääkehittäjä avasi teknistä filosofiaansa toteamalla, että heidän työkalunsa on vibekoodauksen hengessä rakennettu, mutta insinöörityön kurilla strukturoitu järjestelmä. Hän käytti termiä “vibe engineering”. Käytännössä pääkehittäjä vibekoodasi itse esimerkiksi käyttöliittymän työkalulle, vaikka korosti, että ei ole mikään ohjelmointimaailman moniottelija.
Why You Should Use AI to Monitor Local Meetings
Stephen Stirling & Kevin Hoffman (Philadelphia Inquirer)
Yhdysvalloissa on 90 000 paikallishallinnon yksikköä, ja uutismedia seuraa niistä yhä pienempää osaa. Stirling ja Hoffman esittelivät, miten raaka-audio tai -video kaupunginhallituksen kokouksesta muuttuu toimittajan kannalta hyödylliseksi tiedoksi.
Building Sparks: What We Learned Turning 1.2 Million Story Pickups Into an AI-Powered Recommendation Engine
Ken Romano & Cole Carter (Stacker)
Sessiossa kerrottiin, miten Stackerin 1,2 miljoonan jutun arkistoaineistosta rakennettiin AI-pohjainen suosittelumoottori journalisteille.
Building Beat Books From News Archives
Derek Willis (University of Maryland)
Useimpien uutismedioiden arkistot sisältävät paljon sellaista tietoa, jota harva toimittaja koskaan lukee. Willis Marylandin yliopistosta esitteli metodin, jolla tätä tietoa hyödynnetään. ”Beat book” on toimittajakohtainen tietopohja omasta vastuualueesta, koottu AI-avusteisesti arkistosta. Käytäntö toimii myös uusien toimittajien perehdyttämisessä.
TEEMA3: AI yhteistyökumppanina — agentit ja muisti
How a Three-Person Startup Added AI as the Fourth Co-Founder
Justin Bank & Ryan Kellett (The Independent Journalism Atlas)
Independent Journalism Atlas on verifioitu tietokanta yli 1 200 vaikuttaja-journalistista (paremman suomenkielisen vastineen puutteessa käytän tätä), jotka tekevät journalismia perinteisten medioiden ulkopuolella. Startupilla on kolme perustajaa, ja lisäksi kolme muuta “founderia”, jotka ovat Claude-agentteja. Yhtiö julkaisee live-datatuotteita, interaktiivisia visualisointeja ja uutiskirjeitä, joista kaikki hoituvat ihmisen ja tekoälyn yhteistyönä.
Omat muistiinpanoni yo. sessioon:
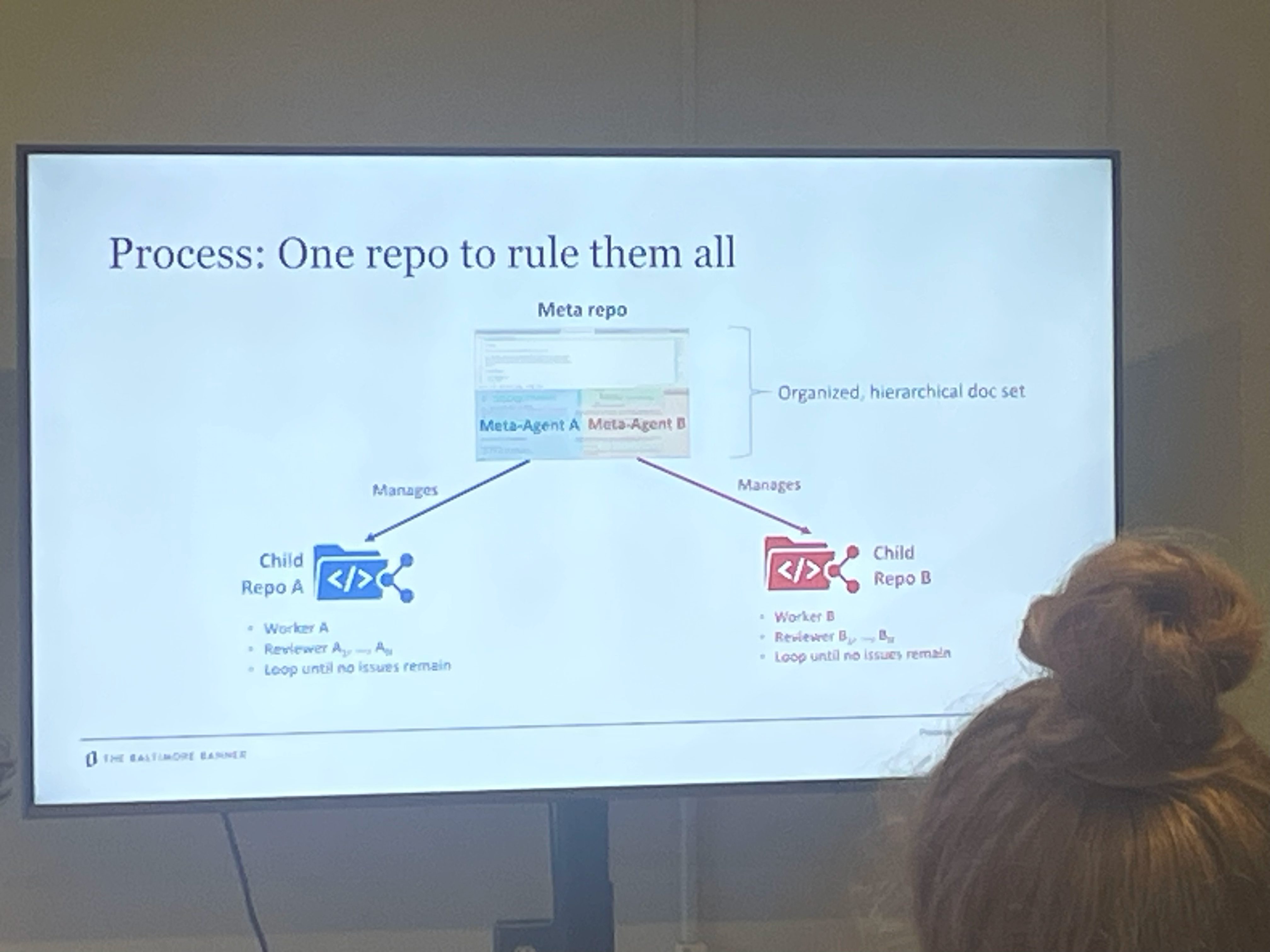
Tämä sessio oli tapahtuman kiinnostavimmasta päästä. Heillä on kolme nimettyä agenttia: Ryan hoitaa datan puhdistuksen ja metodologian, Justin kehityksen ja visualisoinnit, Liz strategian ja kumppanuudet. Jokainen agentti on saanut roolin, kontekstin ja muistin.
Muistiongelman he ratkaisivat kahdella Markdown-tiedostolla: CURRENT_STATE.md (mitä on tehty, mikä on rikki, mitkä ovat seuraavat askeleet) ja MEMORY.md (miksi tämä on olemassa, mitä päätöksiä on tehty, miltä ”hyvä” näyttää).
Tämä käytäntö herätti kysymyksiä: yrityksen jokainen palaveri, myös 1:1-keskustelut, nauhoitetaan ja litteroidaan Granola-nimisellä ohjelmalla ja viedään tekoälylle .md-tiedostona. ”Me voimme tehdä näin — emme ole suuri media.”
He kertoivat myös suoraan, missä tällainen agenttinen co-founder-malli epäonnistuu: Claude hylkäsi aluksi ruokajournalistit soveltaen ”accountability”-kriteeriä liian kapeasti. Pitkissä sessioissa tulee joskus ongelmia. Kerran Claude ehdotti yrityskauppaa lukemalla “rivien välistä” palaverimuistiinpanoista. Tärkein opetus oli, että tekoälylle on annettava selkeä rooli, ei vain käyttötapauksia referenssiksi.
AI Coding Agents for Investigative Journalism
Nick Hagar (Northwestern University)
Sessiossa käytiin läpi sitä, miten Claude Code muuttuu nopeasta mutta riskialttiista assistentista järjestelmälliseksi yhteistyökumppaniksi. Keskeinen viesti oli, että: arvot kuten ”ole läpinäkyvä” eivät riitä sellaisenaan, vaan ne on kyettävä muuttamaan konkreettisiksi toimintasäännöiksi. Hagarin mielestä hyvä skill sisältää seuraavat asiat (en käännä näitä suomeksi, ettei ajatus katoa käännettäessä): Purpose, Allowed work, Review gates, Preservation rules, Documentation outputs, Claim discipline ja Stop conditions.
A Decentralized Agentic-AI Editorial Board for an International Newsroom
Session osallistujat prototyyppasivat pienryhmissä AI-toimitusrakenteen, jossa eri agentit vastaavat eri osa-alueista, kuten faktantarkistuksesta tai otsikoinnista. (vähän samaan tapaan kuin AI:n johtama uutistoimitus -hanke Suomen Tampereella, mutta)
What’s Your Problem?
Paige Moody (Hacks/Hackers & Big Local News), Jake Kara (Hacks/Hackers Newsroom AI Lab)
Session lähtökohtana oli, että monissa AI-kehitysprojekteissa ratkaistava ongelma on jäänyt epämääräiseksi. Osallistujat harjoittelivat oman ongelmansa terävöittämistä ennen kuin tekoäly otetaan mukaan.
Next-Gen NotebookLM: 9 Bold and Impactful New Things Newsrooms Can Do
Jeremy Caplan (CUNY Newmark Graduate School of Journalism)
Caplan esitteli yhdeksän käyttötapaa, jotka muuttavat NotebookLM:n tiivistämistyökalusta kriittiseksi yhteistyökumppaniksi: ne haastavat lähteitä, paljastavat aukkoja ja testaavat oletuksia sen sijaan, että vain tiivistäisivät sisältöä. NotebookLM:n perusarkkitehtuuri koostuu kolmesta osiosta: Sources (lähteet), Explorer (haku luonnollisella kielellä) ja Studio (tuotosten luominen).
Iso suositus muuten Caplanin Wondertools-uutiskirjeelle!
Omat muistiinpanoni yo. sessioon:
NotebookLM on edelleen alikäytetty työkalu journalismissa. Itselleni se on tuttu, mutta aina uusimmista ominaisuuksista ei ehdi pysyä kärryillä. Caplanin esityksen perusteella on kokeiltava ainakin Data Tablesia, joka muuttaa minkä tahansa lähdemateriaalin taulukkomuotoon. ”Very powerful”, totesi Caplan.
Uusi ominaisuus on myös automaattinen lähteiden järjestäminen, eli jos olet liittänyt työkaluun vaikka 50 lähdettä, tekoäly järjestää ne nyt loogisesti halutessasi. Studio-osion tärkein vinkki oli, että yhä useampaa toimintoa voi nyt räätälöidä itse. “Älä paina nappia suoraan, vaan kustomoi kolmen pisteen takaa, kerro mitä haluat. Lopputuloksessa on iso ero.”.
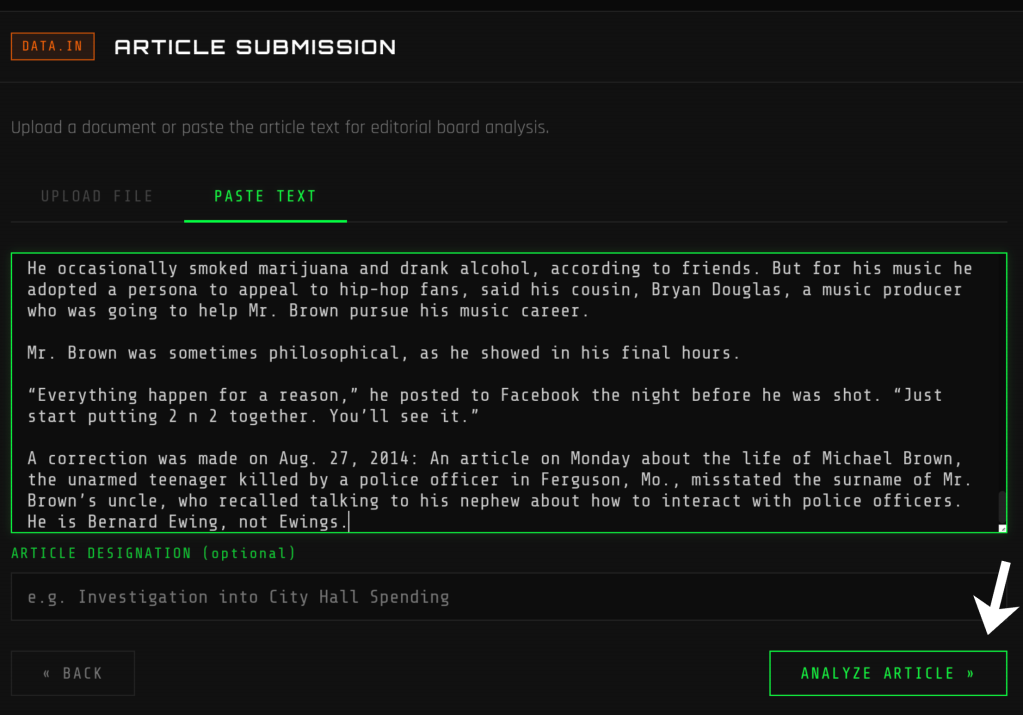
Spreadsheets, Not Chatbots: How ProPublica Investigates With AI
Aaron Brezel (ProPublica)
”Chatbots are claw machines to pull up stuffed animals. It is not ideal for investigative reporting.” Tämä oli Brezelin lähtökohta: chatbotit ovat arvauskoneita, eivätkä ideaaleja täsmällisyyttä vaativaan työhön.
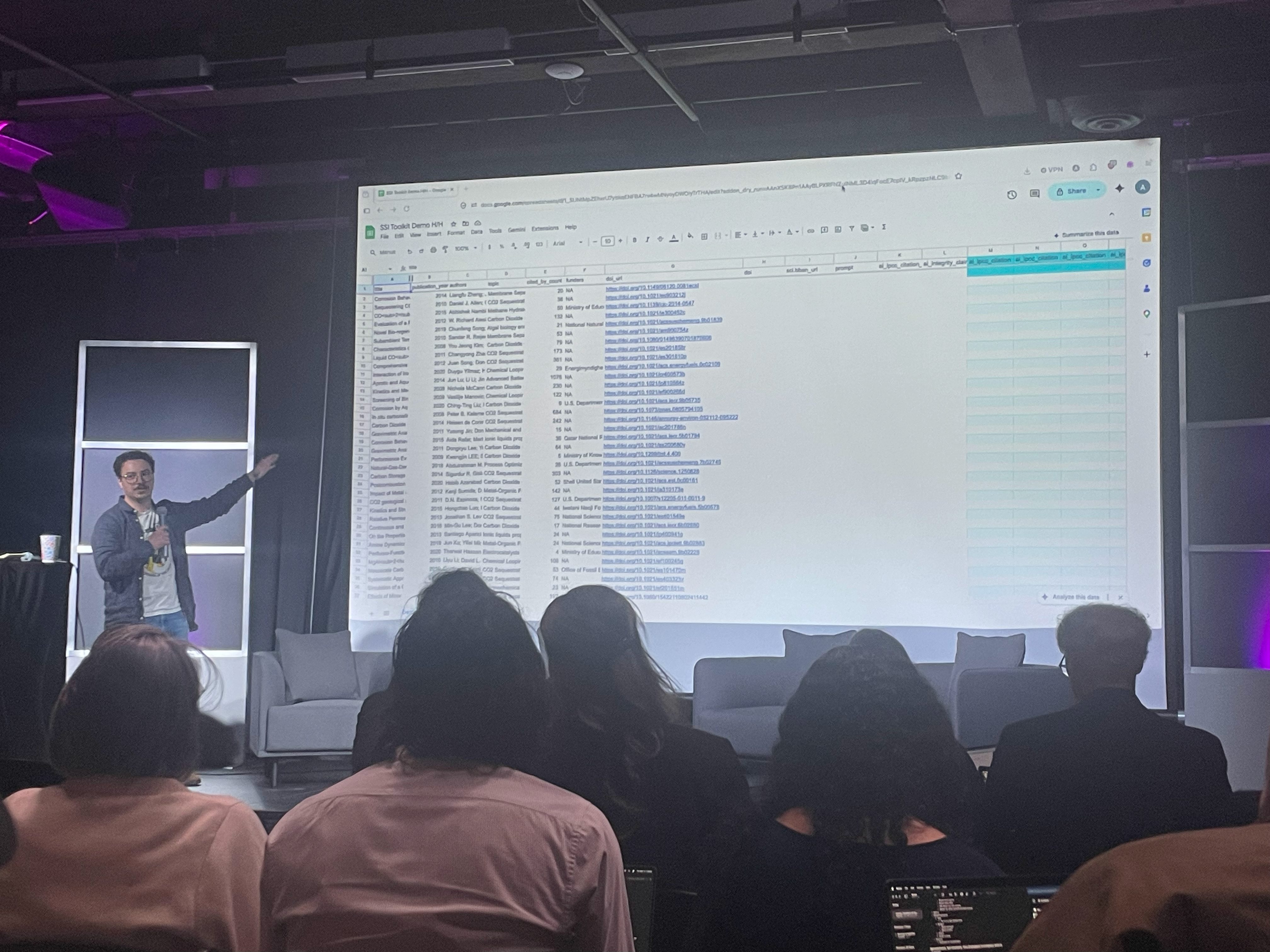
ProPublicassa tutkiva journalismi tapahtuu jo nyt usein taulukoissa (Google Sheetseissä), jollaisen luotettava käsitteleminen chatbotin kautta on hankala ratkaisu. ProPublican vastaus on Spreadsheet Inference (SSI), jossa Google Sheets kytketään Geminin REST API:iin rivi kerrallaan. Tällöin AI tekee tulkinnan ja deterministiset säännöt laskevat lopputuloksen.
Omat muistiinpanoni yo. sessioon:
Tämä oli harvoja sessioita, joissa oli vaikea pysyä kärryillä, mitä tässä oikein tapahtuukaan. En ollut tietoinen, että Sheetsiin pystyy kytkemään Geminin rajapintaa rivi riviltä. Mutta demotus oli vaikuttava. SSI Toolkit löytyy GitHubista: github.com/propublica/gas-ssi-toolkit/
Brezel heitti heti alkuun erinomaisen pointin: se mikä toimii tekoälyn hyödyntämisessä yhdessä mediassa, ei välttämättä toimi ollenkaan toisessa. Tämä johtuu siitä, että medioilla on eri kohderyhmät, eri tavoitteet ja erilaiset toimintakulttuurit. ProPublica on tutkivaan journalismiin erikoistunut voittoa tuottamaton järjestö, jonka asema mediakentässä on monella tapaa erikoinen. Se ei esimerkiksi pidä juttujaan vain omilla sivuillaan, vaan tekee paljon yhteistyötä.
AI as Your Data Desk Partner
Lauren Malkani (Seven Mile Media) & Nick Harbaugh (X-energy)
Sessiossa näytettiin, miten datasetti muuttuu juttuprototyypiksi Claude Coden avulla luonnollisella kielellä kysymällä.
Make Your Own Personal Coach
Sonya Quick (CalMatters & The Markup)
Quick kertoi, miten rakensi oman AI-valmentajan, joka haastaa hänen omaa ajatteluaan.
Using MCP to Analyze Text and Visualize Data
Hong Qu (Harvard Kennedy School)
Sessio näytti vaihe vaiheelta, miten rakenteistamaton teksti muuttuu taulukoiksi ja lopulta selkeiksi visuaalisiksi tuotoksiksi MCP:n avulla. Metodilla on potentiaalia erityisesti suurten tekstimassojen kuten poliittisten puheiden tai oikeusasiakirjojen systemaattisessa analyysissa.
MCP on eräänlainen tekoälysovellusten USB-portti.
Large Language Mathematicians: Public Records in Record Time
Tyson Bird (American City Business Journals)
American City Business Journals halusi työkalun, joka vinkkaa juttuaiheita julkisista asiakirjoista, mutta törmäsi jatkuvasti laskuvirheisiin. Sessiossa kerrottiin, miten ongelma ratkaistiin yhdistämällä kielimallin tekstinymmärrys deterministiseen laskentaan. Siinä tekoäly tunnistaa relevantit luvut ja kontekstin, mutta varsinainen matematiikka jätetään koodille.
TEEMA5: Rakentaminen ilman perinteistä ohjelmointitaustaa — vibekoodaus (tai kansalaiskoodaus)
Vibe Coding Jam Sessions
Kummankin päivän ohjelmassa oli avoin vibekoodaussessio ilman esitäytettyä esityslistaa: tuo läppäri, kerro mitä rakennat, jaa vinkit. Sessio oli avoinna kaikille, myös niille joilla ei ole perinteistä ohjelmointitaustaa.
From Concept to Code: Building Prototypes & Agents With Google AI
Etan Horowitz (Google)
Googlen sessio tutustutti osallistujat Googlen AI -ekosysteemiin, johon kuuluu mm. NotebookLM, Gemini, Stitch ja Flow. Tarkoituksena oli osoittaa, miten näitä työkaluja voidaan yhdistää uutistyöhön toisiinsa kytkettyinä komponentteina. Erityisesti Flow herätti kiinnostusta osallistujissa.
Rapid AI Prototyping Inside the Minnesota Star Tribune
Frank Bi (The Minnesota Star Tribune)
Kun Minnesota Star Tribune rakensi ensimmäisen yleisölle suunnatun AI-tuotteensa, prosessi vaati ”pirates in the navy” -asenteen. Bi kertoi, miten toimituksen sisällä piti luoda tilaa nopeille kokeiluille ilman, että jokainen askel vaati kymmentä hyväksyntää. Ydinajatus oli, että nopea prototyyppi, joka epäonnistuu, on arvokkaampi kuin pitkä suunnitteluprosessi, joka ei tuota mitään.
Pinpoint: Re-Thinking Our Product for the Age of Generative AI
Yuval Shukroon (Google)
Google Pinpoint on tutkivien toimittajien työkalu suurten dokumenttimäärien analysointiin. Sessiossa Googlen tiimi kertoi, miten he ovat miettineet Pinpointia uudelleen generatiivisen tekoälyn aikakaudella ja miten tuotetta on suunniteltu käyttäjille, joiden tekninen osaaminen vaihtelee suuresti.
Schellmann ja Tuquero esittelivät menetelmiä, joilla toimittajat voivat rakentaa kestävämpää todentamisprosessia tekoälyn ja synteettisen sisällön aikakaudella.
What About the Lawsuits? Copyright Litigation, Bot Scrapers, and the Future of the Open Web
Monika Bauerlein (Center for Investigative Reporting), Kevin Bankston (CDT), Meredith Rose (Public Knowledge)
Muutamat kustantajat ovat nostaneet kanteita tekoäly-yhtiöitä vastaan. Sessio purki, mitä oikeudenkäynneissä on tähän mennessä tapahtunut, mitkä kysymykset ovat avoimia ja miten lopputulos voi vaikuttaa siihen, mitä toimituksissa on sallittua tehdä tekoälyn kanssa.
AI Crawlers and the New Publisher Reality: Lessons From the Newspack Network
Joe Boydston (Newspack), Tracy Becker (Automattic)
Newspack-verkoston keräämä data paljasti, miltä käytännössä näyttää AI-ajan tuoma liikenne uutismedioihin: mitkä bottityypit liikkuvat, milloin ja kuinka paljon. Tieto auttaa kustantajia päättämään, miten reagoida.
Move Fast Without Breaking Trust: Challenges in AI Governance for the Future of News
Paine kokeilla tekoälyä luo jännitettä uutisorganisaatioissa. Sessio purki tätä jännitettä käytännöllisesti: miten rakennetaan prosessit, joissa voidaan liikkua nopeasti menettämättä journalistista luottamusta.
AI Without Losing the Human Touch: Sustaining Mental Muscle in AI-Assisted Journalism
Vania André (The Haitian Times)
Sessio otti esille kysymyksen, jota muut lähestyivät varovaisemmin: mitä tapahtuu kognitiivisille taidoille, kun tekoäly ottaa yhä enemmän perustehtäviä hoitaakseen? André esitteli menetelmiä sille, miten toimitukset voivat säilyttää ihmisen kriittisen ajattelun myös silloin, kun apuvälineitä on käytettävissä enemmän kuin koskaan.
Do We Really Need an AI Use Policy?
Alex Mahadevan (Poynter), Emma Cosgrove (Business Insider)
Poynterin Alex Mahadevan ja Business Insiderin Emma Cosgrove esittelivät skenaarioita, joissa käytäntöjen puuttuminen on johtanut ongelmiin, ja skenaarioita, joissa liian jäykät säännöt ovat estäneet hyödyllisten kokeilujen tekemisen.
Evaluating A.I. in the Newsroom: From Patterns to Benchmarks
Nikita Roy (Newsroom Robots Lab), Duy Nguyen (The New York Times), Teresa Mondría Terol (NPR)
Newsroom Robots Lab, NYT ja NPR esittelivät mittareita, joilla voidaan vertailla eri mallien suorituskykyä toimituksellisissa tehtävissä.
How Law Firms Manage Document-Heavy Investigations, and How Journalists Can Use These Tools
Chris Miles & Aaron Patton (Everlaw)
Tutkivat toimittajat ja asianajajat tekevät samantyyppistä työtä: suuria dokumenttimääriä, tutkimista, seuraamista. Everlaw on lakifirmoille rakennettu dokumenttien tutkimisalusta, ja sessio esitteli miten sen metodeja voidaan tuoda journalistien käyttöön.
TEEMA 7: Yleisöt, sisältö, personointijaliiketoiminta
The Survey That Asks ”One More Thing” (on Purpose)
Patrick Boehler & Madison Karas (Gazzetta)
Perinteiset kyselyt kysyvät ennalta määriteltyjä kysymyksiä. Adaptiiviset kyselyt tekevät jotain muuta: AI seuraa vastausta ja kysyy yhden lisäkysymyksen, joka on relevantti juuri sen ihmisen vastaukselle. Gazzetta on rakentanut tällaisen järjestelmän, ja sessio esitteli miten pienten vakiokysymysten ja AI-ohjatun jatkokyselyn yhdistelmä tuottaa rikkaamman kuvan yleisöstä kuin perinteinen lomake.
Using AI to Customize Content & Connect Readers
Ava Motes (Center for Media Engagement, University of Texas at Austin)
Miten AI voi auttaa toimituksia edistämään terveempää puoluerajat ylittävää vuoropuhelua, rauhoittamaan räyhääviä kommenttiosioita ja tavoittamaan paremmin monimuotoiset yleisöt? UT Austinin Media Engagement Center esitteli tutkimuspohjaisia käytännöllisiä menetelmiä.
From AI Journaling to the Mind Economy: Rethinking How Journalism Understands Human Narratives
Dexiang ”Darren” Gao (HEAUT Foundation)
HEAUT on AI-päiväkirjaalusta, joka muuttaa henkilökohtaisen kirjoittamisen strukturoiduksi tiedoksi. Sessio esitteli ”Mind Economy” -konseptin: henkilökohtaisista narratiiveista tulee tietopääomaa, jota voidaan käyttää journalismin lähdeaineistona.
AI as a Power Assist for Political Accountability Reporting
Chandran Sankaran (Gigafact), Emily Le Coz (Suncoast Searchlight), Kevin Grant (Allbritton Journalism Institute)
Poliitikkojen lausunnot ovat hajallaan ympäri nettiä: Gigafact on rakentanut alustan, joka kokoaa nämä, analysoi ne ja auttaa toimittajia.
Build the News Industry’s AI Business Plan
Richard Lui (MS NOW / CAREGenome), Andy Pergam (Knight Center, ASU)
Sessio haastoi osallistujia rakentamaan käytännöllistä liiketoimintasuunnitelmaa sille, miten uusmedia voi hyödyntää asemaansa sen sijaan, että odottaa yhtiöiden tekevän sen heidän puolestaan.
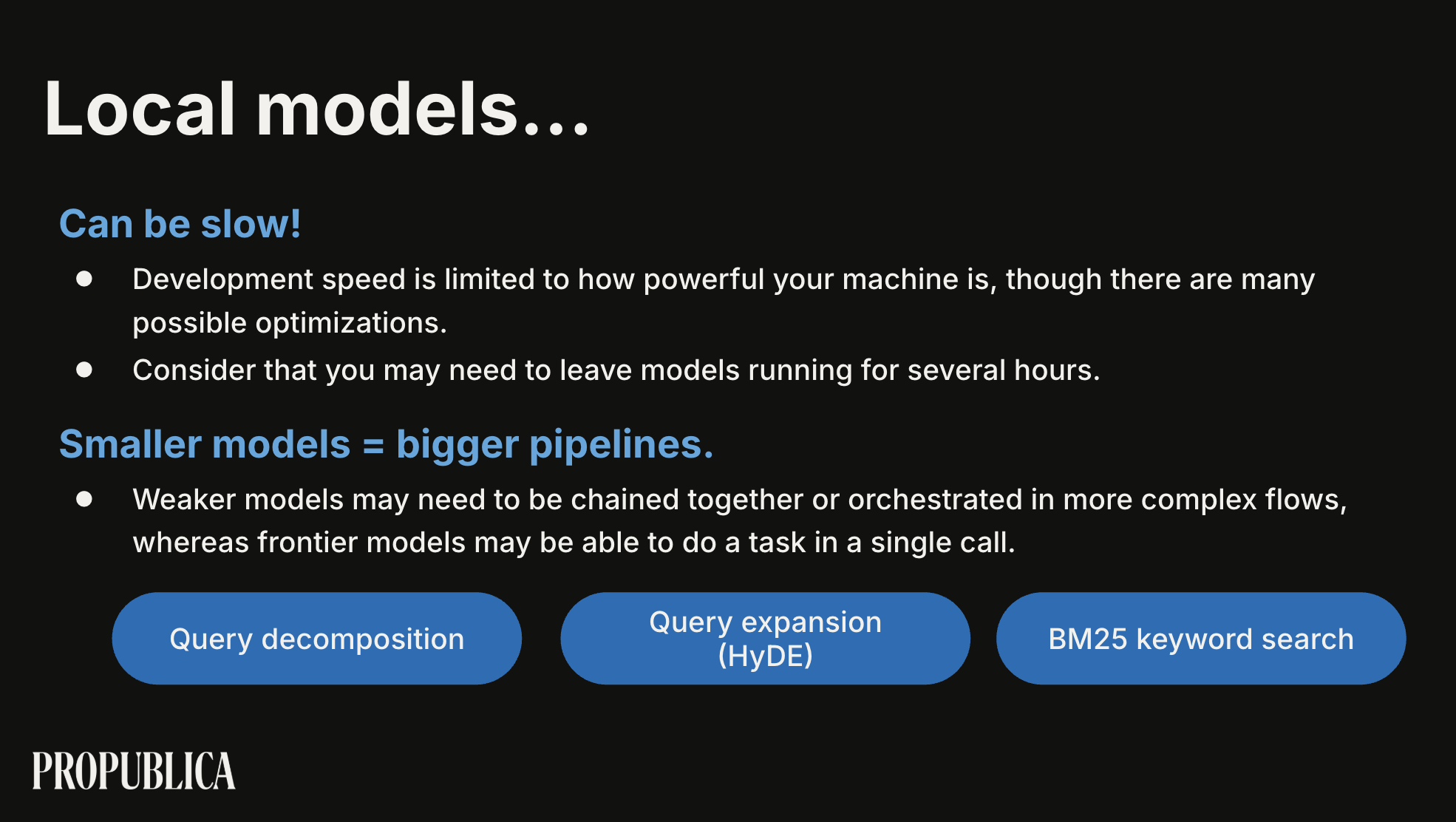
What’s Possible With Local Models? Building Secure AI Pipelines for Investigative Journalism
Ben Werdmuller & Dana Chiueh (ProPublica)
Paikallisesti pyörivät AI-mallit ratkaisevat yksityisyysongelman, mutta luovat uusia: mitkä mallit toimivat, mihin ne soveltuvat, mitä taitoja tarvitaan? ProPublican tiimi esitteli, miten he ovat rakentaneet turvallisia AI-putkistoja tutkivaan journalismiin paikallisilla malleilla.
Getting the Very, Very Best Out of Archival Audio
Mark Chonofsky (Chicago Public Media)
Chonofsky kertoi, miten he ovat litteroineet WBEZ:n koko äänarkiston tekoälyavusteisesti ja mitä teknisiä haasteita se vaati: äänen valmistelu, puhujien tunnistaminen, erikoistermit, vaihtelevat tallennusolosuhteet.
From Fear to Fluency: Building an AI-Ready Newsroom Culture
Peder Hammerskov (Center for AI at DMJX)
Hammerskov esitteli työtä, jota tanskalaisten uutistoimitusten kanssa on tehty AI-kulttuurin rakentamisessa.
Tunnelma: synkistelystä ei tietoakaan
Loppuun omia mietteitäni. Poikkeuksellisen Hacks and Hackers -tapahtumasta teki tunnelma. Synkistelyä ei ollut lainkaan. Huolipuheen puuttumisen panivat merkille myös tapahtuman järjestäjät loppupuheenvuorossaan: alan murros voidaan nähdä myös mahdollisuutena. Jotain kuvastanee myös tämä AI-kurssikaverini, uutistoimisto AP:n Head of Productin Bryan Davisin ilme=)
Vakavammin ottaen, kaksi havaintoa jäi erityisesti mieleen. Torstaiaamun ryhmäharjoituksessa asetuimme kaikki noin kolmesataa ihmistä isoon rinkiin, ja moni kertoi pyydettäessä avoimista tehtävistä organisaatioissaan. Käden sai nostaa pystyyn, jos koki että pystyy auttamaan joko itse tai vinkkaamaan sopivan rekryn. Virkistävää.
Toinen mieleen jäänyt ajatus on se, että eurooppalaista ja etenkin pohjoismaista tekoälytekemistä arvostetaan täälläkin laajalti. Mutta se täytyy tämän tapahtuman perusteella sanoa, että amerikkalaiset kirivät kovaa, etenkin uutishankinnan automatisoinnin saralla.
Järjestäjät alleviivasivat halunneensa pitää tapahtuman startup-henkisenä, mikä toteutuikin. Asian kääntöpuoli on se, että ensi vuonna tapahtumaan tuskin on saatavilla kovin paljon enemmän lippuja: kun juttelin pääjärjestäjän kanssa, hän totesi, että ei halua kasvattaa tapahtumaa kovin paljon isommaksi, koska tietynlainen ”kotikutoisuus” kärsisi.
PS. Tapahtumalla oli käytössä MCP-yhteys tapahtumaohjelmaan ja jaettuihin muistiinpanoihin, mikä helpotti kovasti omienkin muistiinpanojen täydentämistä Claude Coden avustuksella. Tapahtuman hengessä tallensin kaikki omat muikkarini omaan Obsidian-holviini, joka on koneluettavaan md-tiedostomuotoon materiaaleja pakkaava ilmainen muistiinpano-ohjelma.Näin niiden hyödyntäminen aina jatkossa kaikissa Claude-keskusteluissani on helpompaa.
Lyhyestä virsi kaunis. Nämä ovat kulkeneet mukanani vuosikaudet.
1. Notepad. Koska tietäjät tietää.
Kevyt, nopea, yksinkertainen. Kuin tekstinkäsittelyohjelmien teksti-tv. Ja mikä tärkeintä: ei muotoiluja. Tämän kautta kulkee valtava määrä tekstiä joka päivä.
2. Kuvakaappausten tallentuminen niille dedikoituun kansioon, jottei työpöytä räjähdä.
Yksinkertaisin tapa:
Paina Shift + Command + 5 Näytölle avautuu näyttökuvatyökalu Klikkaa Valinnat Valitse Tallenna kohteeseen → Muu sijainti Valitse haluamasi kansio (esim. ”Näyttökuvat, tai miksi sen haluat nimetäkään”)
Ohessa oman koneeni näkymä. Finderin suosikeihin vetämällä kansio myös löytyy heti.
3. Chrome-selaimen kirjanmerkit ja kansiot.
Kuulostaa itsestäänselvyydeltä, mutta olen huomannut, että kaikki eivät kirjanmerkkejä käytä. Itse tykkään myös järjestellä asioita kansioihin kirjanmerkeissä. Usein vähän samalla logiikalla kuin Slackissa teemajaottelu työjuttujen mukaan.
Skill, skilli, taito. Se tarkoittaa tekoälykontekstissa pysyvää ohjeistusta, joka tehdään tekoälyn taustalle. Se on periaatteessa prompti, joka on sopimus siitä, miten tiettyjä asioita tehdään. Ihan käytännössä se on tiedosto, joka tehdään itse esimerkiksi Claude Codella ja tallennetaan omalle koneelle tiettyyn kansioon, tai tekoälypalvelun web-versiossa (esim. Clauden selain- tai sovelluskäyttöliittymä), jolloin se tallentuu palveluntarjoajan pilveen.
Skillipankit – toimituksen uusi yhteinen muisti?
Ohjelmistokehityksessä on jo pitkään rakennettu ns. skillipankkeja: jaettuja tiedostoja, jotka kertovat tekoälylle miten organisaatiossa toimitaan.
Näyttäisi siltä, että olemme nyt siirtymässä aikakaudelle, jossa tällaiset itserakennetut ”keskusaivot” eivät välttämättä jää vain kehitysosastolle. Jaetut brändiohjeet, jaetut designohjeet, jaetut termipankit, jaetut tyylioppaat…tarpeita on.
Tätä puoltaa useampi kehityssuunta, ja suomalaisissa mediataloissa näitä asioita jo kokeillaan. Yksi kehityssuunta on, että taitoja on voinut jonkin aikaa luoda tekoälypalveluiden web-versioissa, mikä demokratisoi niiden luomista. Toinen on, että yhteisesti jaettu ”muisti” aidosti mahdollistaa uusien asioiden tekemisen yhdenmukaisesti, parhaimmillaan ehkä jopa sen kuuluisan hiljaisen tiedon siirtymisen laajemmin organisaation käyttöön. Kolmas on, että onhan se nyt kätevää ja monessa mielessä perusteltua, että yhteiset pelisäännöt ylipäänsä ovat samassa paikassa eivät levällään ympäri Sharepointia.
Tässä Suomesta yksi esimerkki, henkilöstöyhtiö Baronan markkinointitiimin skillipankki (Lähde: Baronan CMO:n Joni Helmisen postaus Linkedinissä):
En ihmettelisi, jos yksi tulevaisuuden keskeisistä rooleista uutismediassakin olisi tehtävä, jossa hallinnoidaan ja pidetään ajan tasalla näitä pankkeja. Ne olisivat enemmänkin organisaation muisti kuin IT-projekti, joten omistus ei välttämättä olisi edes teknologiapuolella, vaikka toki varmasti jollain tapaa yhteistyössä sen kanssa.
Avoimet mallit, automaatio ja agentit
Avoimet kielimallit ovat tekoälymalleja, joiden koodi ja joskus myös opetusdata ovat julkisesti saatavilla. Toisin kuin suljetut mallit – kuten ChatGPT tai Claude – niitä voi ajaa eli käyttää omalla koneella tai omalla palvelimella. Journalismin kannalta olennaista on, että kun malli pyörii omassa infrastruktuurissa, esimerkiksi arkaluonteinen lähdeaineisto ei kulje kolmansien osapuolten kautta. Avoimet mallit kehittyvät nopeasti, ja vaikka niiden ympärille ei ehkä voi rakentaa aivan kaikkea, niin sopivia käyttötarkoituksia löytyy yhä useammin. Jos journalistiset esimerkit kiinnostavat, niin tämä sivusto kerää esimerkkejä.
Automaatio tarkoittaa toistuvan työn siirtämistä koneelle. Idea ei ole uusi, mutta generatiivinen tekoäly on käytännössä romahduttanut kynnyksen luoda työn kulkuja. Työkalut kuten OpenAI:n Codex mahdollistavat jo automaatioiden rakentamisen ja ajamisen pilvessä ilman merkittävää teknistä osaamista. Agentit vievät tämän vielä pidemmälle, eli ne eivät vain suorita yksittäistä tehtävää, vaan ketjuttavat niitä itsenäisesti.
Tällä hetkellä automaatioita rakennetaan pitkälti puoliteknisillä alustoilla kuten n8n, Make tai Zapier. Ne ovat jo melko matalan kynnyksen työkaluja, mutta vaativat silti jonkin verran teknistä ymmärrystä – sen verran, että ei rivitoimittaja niitä ala mediataloissa käyttämään. Työkalun käyttö vaatii logiikan hahmottamista, integraatioiden rakentamista ja virheiden korjausta. Kun tulevaisuudessa automaatioiden rakentaminen onnistuu käytännössä pelkällä promptauksella, kynnys tehdä niitä madaltuu entisestään. Siinä on toki riskinsäkin. Eikä vähiten se, että kaikkea ei kannata eikä pidä automatisoida, jotta oma ajattelu pysyy vireänä (vinkit sen pitämiseen tikissä AI-aikana täällä).
Kuulostiko ylläoleva liian optimistiselta tai epärealistiselta? Voi olla sitäkin. Kollegani Elina Lappalainen pohdiskelee asiaa osuvasti Linkedinissä, jossa hän toteaa, että tehokkuusloikat syntyvät usein ihan perustyökalujen ja -työnkulkujen kuntoon laittamisesta ennen kuin hypätään agentteihin ja automaatioihin. Ja näinkin se on. Perusta ensin kuntoon.
Vielä ollaan aika kaukana siitä maailmasta, jossa iso joukko toimittajia laajassa mitassa vaikkapa vibekoodaisi itselleen ja kollegoilleen sopivanlaisia työkaluja niin sanotusti tuotantokäyttöön. Ennen kuin tämä on mahdollista, organisaation on mietittävä kuntoon prosessit ja ”hiekkalaatikot”, jollaisia pelkät kokeilut vaativat.
Meidän ihmisten on samalla hyvä pyrkiä kehittämään niitä ominaisuuksiamme, joihin tekoäly ei pysty. Journalismissa se tarkoittaa esimerkiksi asioiden syvällisten merkityksien ymmärtämistä, kontekstointia, lähdeverkoston rakentamista, haastattelutaitoja, luottamuksen rakentamista ja tietysti kriittistä ajattelua. Entistä tärkeämpää tulee epäilemättä myös kyvystä ymmärtää, mitä töitä ylipäänsä kannattaa antaa koneelle ja mitä ei.
Tekoälystä on tullut työelämän nopein lupaus. Yksi lupaus on, että ulkoista tylsät rutiinit koneelle ja saat enemmän aikaa ajattelulle.
Näin monesti onkin. Väitän kuitenkin, että todellisuus ei ole ihan mustavalkoinen, vaan osin jopa ristiriitainen. Se aika ei vapaudu automaattisesti, vaan sen eteen täytyy myös tehdä itse töitä.
Haluan alleviivata, että omasta mielestäni järkevin tapa suhtautua tekoälyyn on optimistinen kriittisyys. Ei siis täysin pidäkkeetön hypetys, eikä liioin neliraajajarrutus-tyyppinen torjunta. Optimistisella kriittisyydellä tarkoitan halua ja kykyä etsiä uusia mahdollisuuksia, mutta ymmärtäen samalla riskit ja miten niitä voi ehkäistä.
Optimistisen kriittisyyden hengessä nostan tähän blogikirjoitukseen kolme osittain toisiinsa limittyvää kiinnostavaa teemaa, joita käsitteleviin artikkeleihin olen törmännyt lyhyen ajan sisään.
1. Miten hyödyntää tekoälyä (journalistisessa) työssä siten, että oma ajattelu ei taannu? Kärjistäen: miten välttää “aivokuolema”
Vältä kirjoittamisen ulkoistamista tekoälylle. Kirjoittaminen on ajattelua. Jos ulkoistat sitä liiaksi tekoälylle, et ajattele samalla tavalla kuin kirjoittaessasi. Tietyntyyppisten asioiden luonnostelu tekoälyllä on eri asia. Se voi olla hyvinkin perusteltua ja tarpeellista, ja helpottaa työtä. Ihmisen vastuu on avainasemassa.
Varo lipsahtamasta moodiin, jossa tekoälyn kanssa keskustelemisesta tulee ajattelun korvike. Yksi merkki tästä voi olla, jos huomaat kyseleväsi tekoälyltä yksinkertaisia asioita, jotka ennen olisit ratkonut itse pohtimalla (ja kyllä, olen itsekin sortunut tähän toistuvasti, heh).
Tarkista ja tarvittaessa kyseenalaista tekoälyn vastaukset, vaikka se onkin työlästä. Tarkistaminen pitää ajattelusi terässä. Jos koet, että tekisit koko homman nopeammin ilman tekoälyä, sitten tee niin.
Vältä liiallista automatisointia, vaikka se kuinka houkuttelisi. Toistuvat rutiinit kyllä kannattaa automatisoida.
Säilytä vastuu päätöksistä itselläsi.
Harjoita aktiivisesti omaa ajatteluasi myös ilman tekoälyä. Kuulostaa itsestäänselvältä, mutta esimerkiksi kavereiden/kollegoiden kanssa kasvokkain sparrailu on mitä parasta ajattelun treenaamista.
2. Miten välttää “AI brain fry” eli kognitiivinen ylikuormitus? Toisin sanoen, että homma ei lähde lapasesta…
Lähde: Harvard Business Review’n artikkeli “When Using AI Leads to “Brain Fry”. (5.3.2026). Allaoleva lista on yhdistelmä artikkelin sisältöä ja omaa ajatteluani.
Kiinnitä tietoisesti huomiota siihen, minkä verran kuormitusta ihmiselle tai ihmisille syntyy. Älä ota käyttöön liikaa tekoälytyökaluja tai -prosesseja yhtä aikaa.
Vältä liiallista jatkuvaa valvontaa. Käytä tekoälyä niin, ettei synny liian paljon seurattavaa ja tarkistettavaa.
Hyödynnä tekoälyä etenkin rutiinitöissä. Pyri siirtämään toistuvat ja kuormittavat tehtävät tekoälylle.
Luo selkeät ja realistiset odotukset. Määrittele, mitä tekoälyn käytöllä tavoitellaan ja miten sen pitäisi vaikuttaa työn määrään. Ole suora ja rehellinen.
Keskity vaikutuksiin, älä määrään. Vältä mittaamasta onnistumista sillä, kuinka paljon tekoälyä käytetään, vaan mitä sillä saadaan aikaan.
Satsaa ongelmien jäsentämiseen, priorisointiin, kokonaisuuksien hallintaan.
Tarjoa tukea ja opastusta. Esimerkiksi esihenkilön tuki ja selkeät ohjeet vähentävät kuormitusta.
Sovi yhteiset pelisäännöt ja käytännöt.
Suojele keskittymistä. Vältä tilannetta, jossa työ pirstaloituu jatkuviin keskeytyksiin ja esimerkiksi työkalujen välillä hyppimiseen.
3. Mitä tehdä tilanteessa, jossa tekoäly ei vähennäkään työtä, vaan tekee siitä intensiivisempää?
Lähde: Harvard Business Review’n artikkeli “AI Doesn’t Reduce Work—It Intensifies It”. (9.2.2026). Allaoleva lista on yhdistelmä artikkelin sisältöä ja omaa ajatteluani.
Rajaa tekoälyllä tehtävän työn laajuutta tietoisesti. Älä ota uusia tehtäviä vain siksi, että tekoäly tekee ne mahdollisiksi.
Vältä tekoälyn käytön valumista ainakaan liiallisesti taukoihin ja pieniin vapaa-ajan hetkiin.
Vältä ”multipaskingia” (sic, heh). Keskity yhteen kokonaisuuteen kerrallaan, älä yritä tehdä montaa tekoälyasiaa yhtä aikaa.
Etene vaiheittain. Tee työ selkeissä jaksoissa tai osioissa sen sijaan, että reagoit jatkuvasti uusiin ärsykkeisiin.
Pidä säännöllisiä harkintataukoja. Pysähdy arvioimaan suuntaa.
Säilytä selkeät rajat työn ja vapaa-ajan välillä siinä määrin, kun se sinulle sopii (esim. itse en ole koskaan kaivannut selkeää rajaa näiden välille, mutta rajansa varmaan kaikella). Huolehdi palautumisesta.
Tee työtä myös yhdessä ihmisten kanssa. Keskustelu ja yhteistyö tasapainottavat yksin työskentelyä.
Tunnista kuormituksen kasvu ajoissa. Jos työ lisääntyy huomaamatta, pysähdy ja tarkista tapasi toimia.
Ei kannata säikähtää! Tämä on helpompaa kuin luulet.
Olet ehkä huomannut, että erilaisten uutiskoosteiden pyytäminen tekoälypalveluilta suoraan ei aina johda laadullisesti kummoisiin lopputuloksiin (vaikka esimerkiksi ChatGPT:n agenttitila & ajastus -kombo on tässä parhaimmillaan hyödyllinen). Lopputulos tuppaa horjumaan etenkin silloin, jos halutaan seurata juuri tiettyjä lähteitä juuri tietyin väliajoin juuri tietyllä tavalla.
Automaatioiden rakentamiseen on monenlaisia varta vasten suunniteltuja työkaluja, kuten Zapier, N8N tai Power Automate, mutta aina sellaisia ei tarvita, eikä välttämättä generatiivista tekoälyäkään.
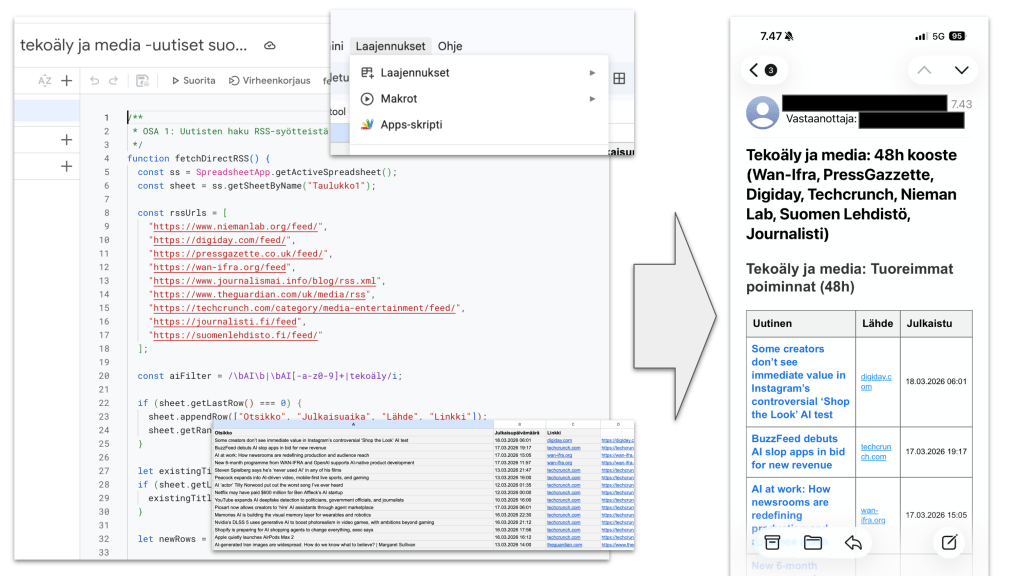
Esittelen tässä kirjoituksessa yhden yksinkertaisen tavan luoda itselleen uutisseurannan automaatio Googlen työskentely-ympäristössä.
Se hyödyntää Google Sheets -taulukkolaskentaohjelmaa sekä Google Apps Scriptiä. Apps Script on pilvipohjainen JavaScript-alusta (JavaScript on ohjelmointikieli), jolla voi automatisoida tehtäviä, luoda omia työkaluja ja yhdistää Googlen eri palveluita toisiinsa. Se on ilmainen eli kuuluu tavalliseen Google-tiliin ja etuna on, että siinä kirjoitetaan ja ajetaan koodia suoraan selaimessa. JavaScript-koodia sinun ei tarvitse osata riviäkään, vaan voit pyytää sellaista tekoälyltä (kannattaa kuitenkin pyrkiä varmistamaan tekoälyn kanssa keskustellessa, että toimit fiksusti ja tietoturvallisesti. Varmista kaverilta, jos pohdituttaa).
Oma esimerkkityönkulkuni koostuu kiteytettynä seuraavista vaiheista:
Lähteet: Valitaan seurattavat sivustot, jotka tarjoavat jatkuvaa uutisvirtaa koneellisesti luettavassa muodossa (omaan työnkulkuuni hain uutisia yhdeksän eri median RSS-syötteistä).
Suodatus: Luodaan säännöt, joilla ei-haluttu sisältö karsitaan pois. (omaan työnkulkuni koodiin lisättiin hakuehto, joka poimii vain ne otsikot, joissa esiintyi sana tekoäly jossain muodossa).
Tallennus: Tallennetaan haetut uutiset paikkaan, jossa ne säilyvät (omassa työnkulussaniuutiset tallennetaan taulukkoon, ja lisäksi koodi varmistaa otsikon perusteella, ettei samaa juttua lisätä listalle kahdesti).
Ajastus: Asetetaan järjestelmä toimimaan itsenäisesti tiettyinä aikoina (omassa työnkulussani uutisia haetaan taulukkoon kuuden tunnin välein).
Lähetys: Toimitetaan valmis tieto halutussa muodossa haluttuun paikkaan (omassa työnkulussani saan sähköpostiini joka aamu klo 7–8 välillä viimeisen 48 aikana kertyneet uutiset. Vaihdan tämän todennäköisesti pian toimimaan joka toinen päivä, siksi 48 tunnin aikaväli tässä vaiheessa, vaikka maili tulee päivittäin).
Tämä työnkulku on vielä perinteistä automaatiota, joka toimii antamillasi ohjeilla. Tekoälyä (Geminiä) käytetään tässä välillisesti koodin kirjoittamiseen.
Tärkeä huomio Apps Scriptistä: Kun tallennat skriptiä tai annat sille käyttöoikeuksia, Google saattaa näyttää varoituksen ”varmistamattomasta sovelluksesta”. Tästä ei kannata hätääntyä. Kyseessä on Googlen normaali turvatoimi itse luoduille työkaluille. Kun teet työkalun itse, se on turvallista, mutta voit aina varmistaa asiantuntijalta, jos jokin mietityttää.
Jos haluaisit viedä homman pidemmälle: Voit lisätä skriptiin Geminin API-avaimen (henkilökohtainen tunniste, jota on säilytettävä tietoturvallisesti eli älä jaa sitä muille). Silloin kielimalli voisi esimerkiksi analysoida taulukon uutiset puolestasi ja tiivistää ne ennen sähköpostin lähetystä.
SXSW eli South by Southwest -tapahtuma on jälleen meneillään Austinissa Yhdysvaltain Texasissa. Tämä omaleimainen tapahtuma on usein myös uusimpien mediainnovaatioiden ja kiinnostavien mediakeskustelujen näyttämö. Esimerkiksi tekoälyominaisuuksistaan tunnettu amerikkalainen uutissovellus Particle ensijulkaistiin kolme vuotta sitten juuri Austinissa. Tässä tuore juttu sovelluksen uudesta “podcastinpurkaja”-toiminnosta.
SXSW-tapahtuman pääteemat ovat teknologia ja musiikki sekä televisio ja elokuva.
SXSW 2026:n nettisivujen aikatauluhausta täältä pystyt helposti hakemaan tapahtumia esimerkiksi media-hakusanalla. Joitain sisältöjä voi katsella ilmaiseksi Youtubesta täältä.
Mediaan liittyvää keskustelua ja havainnointia on SXSW:ssä kuitenkin paljon myös muualla kuin suoraan media-alaan dedikoiduissa tapahtumissa. Hyvänä esimerkkinä on amerikkalaisfuturisti Amy Webbin perinteinen tulevaisuuskatsaus, jonka hän julkaisee aina Austinissa. Tällä kertaa Webb oli paketoinut katsauksensa täysin uusiksi, ehkäpä myös siksi, että viime vuosina se ehti paisua yli 1000-sivuiseksi “tekkiraamatuksi”, jota ei lue kertaistumalta erkkikään. Uudistuneen raportin nimi on reilu 300-sivuinen Convergence Outlook 2026, ja se sisältää huomioita myös mediasta.
Ensiksi Webb taustoittaa, että 1990-luvun lopun digitaalinen murros syrjäytti vanhoja liiketoimintamalleja myös mediassa: “legacy media” oli yksi toimialoista, joita internetin, hakukoneiden, verkkokaupan ja digitaalisten maksujen yhdistelmä ravisteli.
Toiseksi hän muistuttaa, että luottamus mediaan instituutiona heikkenee nyt samaan aikaan, kun luottamus hallintoon, tieteeseen ja yrityksiin.
Webb väittää, että olemme siirtymässä “post-truth”-tilasta (jossa kiistellään faktoista) kohti “post-reality”-tilaa (jossa kiistellään siitä, mikä on todellista). Jälkimmäisessä synteettinen media, personoitu AI-kuratoitu sisältö ja eriytynyt luottamus hajottavat yhteisen todellisuuspohjan. Tällä on suora merkitys uutismedialle, jonka rooli yhteisen todellisuuden rakentajana vaikeutuu.
Webb toteaa, että “post-reality”-ajan seuraukset voivat olla erittäin vakavia. Hän muistuttaa, että jo vuonna 2024 Yhdysvalloissa nähtiin vakava vaaratilanne, kun hurrikaani Helenen aikana levisi väärennettyjä tutkakuvia, joiden väitettiin todistavan hallituksen manipuloivan säätä. Kuvissa näkyi keinotekoisia myrskymuotoja esimerkiksi Detroitin, Chicagon ja St. Louisin yllä. Tämä johti Pohjois-Carolinassa siihen, että osa ihmisistä torjui Yhdysvaltain hätätilaviraston FEMA:n avun pitkittäen tilannetta.
Lisäksi raportti liittää median muutoksen “post-search”-internetiin. Kun AI-assistentit ja agentit alkavat toimia käyttöliittymänä verkkoon, käyttäjä ei enää mene uutis- tai sisältösivulle itse, vaan agentti tiivistää, valikoi ja ohjaa. Raportti jopa ennakoi, että verkko voi muuttua malliin, jossa sisällöstä aletaan periä maksuja agenteilta”. Tähän kohtaan täytyy itse muistuttaa, että Suomessa tämänkaltainen kehitys ei ole vielä läheskään yhtä pitkällä kuin joillain muilla markkinoilla.
“Convergence” on Webbin raportin ydintermi. Se ei viittaa ensisijaisesti “mediakonvergenssiin” eli siihen, että eri mediaformaatit ja -kanavat sulautuisivat yhteen. Modernimpi termi olisi varmaankin nestemäinen sisältö, liquid content. Webb tarkoittaa paljon laajemmin useiden trendien, voimien ja epävarmuuksien risteymää eli sitä, kun teknologia, talous, geopoliittiset jännitteet, ilmasto, sääntely ja ihmisten käyttäytyminen alkavat vaikuttaa samanaikaisesti toisiinsa. Webbin mukaan yhteisvaikutus on suurempi ja erilainen kuin yksittäisten muutosten summa. Raportin oma määritelmä toteaa, että convergence on tilanne, jossa useat trendit ja voimat “intersect and interact” ja synnyttävät uudenlaisen vaikutuksen.