1) Luottamus uutisia kohtaan laskee, mutta Suomi on yhä maailman kärjessä. Laitavasemmistoon tai oikeistoon itsensä mieltävissä laskua.
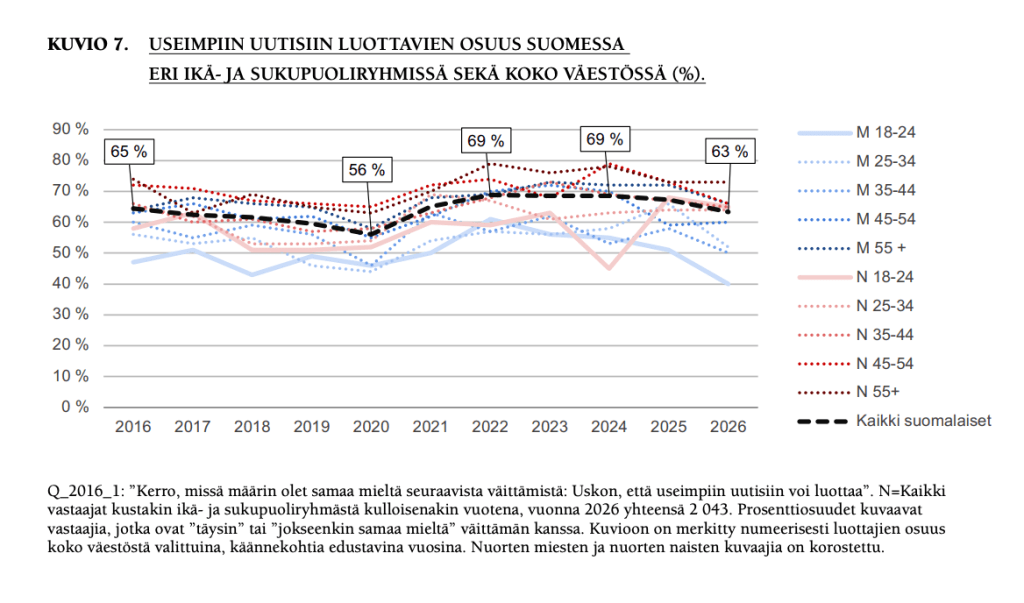
63 prosenttia suomalaisista ilmoittaa luottavansa useimpiin uutisiin, laskua edellisvuoteen neljä prosenttiyksikköä. Raportissa ennakoidaan, että myös perinteisten uutisbrändien on syytä varautua luottamuksen laskuun, vaikka tilanne on hyvä.
Nuoret luottavat vähemmän kuin iäkkäämmät. Naiset luottavat merkittävästi enemmän kuin miehet, mikä eroaa kansainvälisestä vertailusta, jossa sukupuolieroa ei ole.
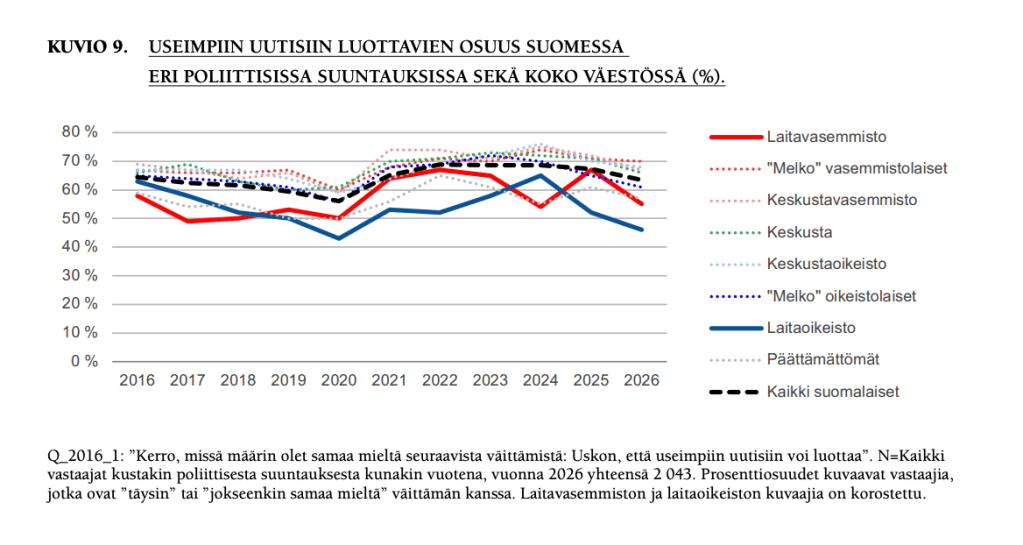
Kun katsotaan aatteellisesta kulmasta, luottamuksen lasku on suhteellisesti suurinta itsensä joko laitavasemmistoon tai laitaoikeistoon mieltävissä.
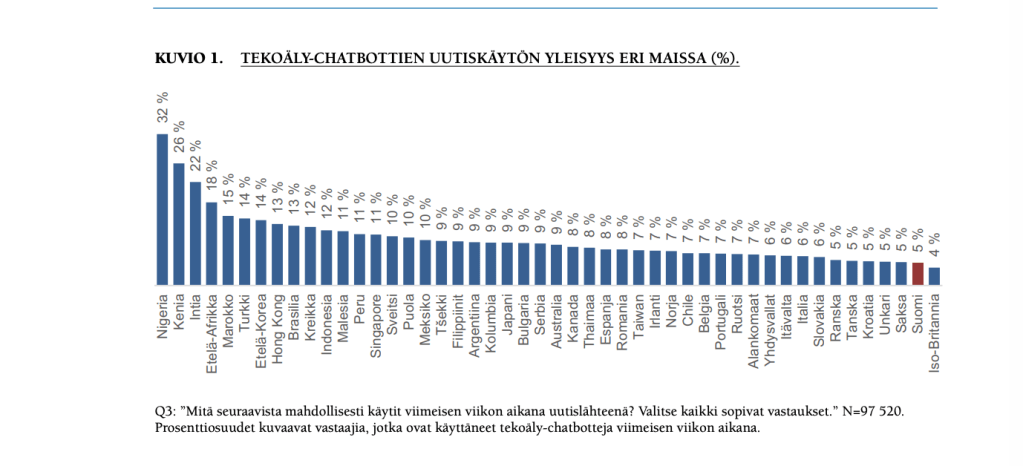
2)Suomessa tekoälypalveluiden käyttö uutislähteenä on kasvanut hieman, mutta yhä pientä ja pienempää kuin monessa muussa maassa (n. 5 % on käyttänyt niitä uutisten etsimiseen edeltävän viikon aikana, edellisvuoden luku oli 3 %). Niiden käyttö uutislähteenä on yleisintä alle 35-vuotiaissa miehissä.
Huomionarvoista on, että suomalaiset tekoälykäyttäjät maksavat verkkouutisista lähes kaksinkertaisesti muuhun väestöön verrattuna.
Kiinnostavaa on myös, että suomalaiset klikkaavat (tai ainakin kysyttäessä kokevat klikkaavansa) tekoälyn tarjoamia linkkejä alkuperäisiin uutislähteisiin kansainvälisesti vertailtuna harvoin. Raportin mukaan uhkakuvana on, että jos tekoälyn uutiskäyttö yleistyy, uhkaa uutismedian verkkoliikenne vähentyä enemmän kuin monessa muussa maassa.
Raportissa arvioidaan, että uutisten kulutus tekoälypalveluiden tulee myös Suomessa kasvamaan varsinkin, jos niistä tulee luotettavampia. Intiassa ne ovat jo ohittaneet radiolähetykset tärkeimpänä uutislähteenä.
Tekoälyä suomalaiset käyttävät kuitenkin muuten laajasti.
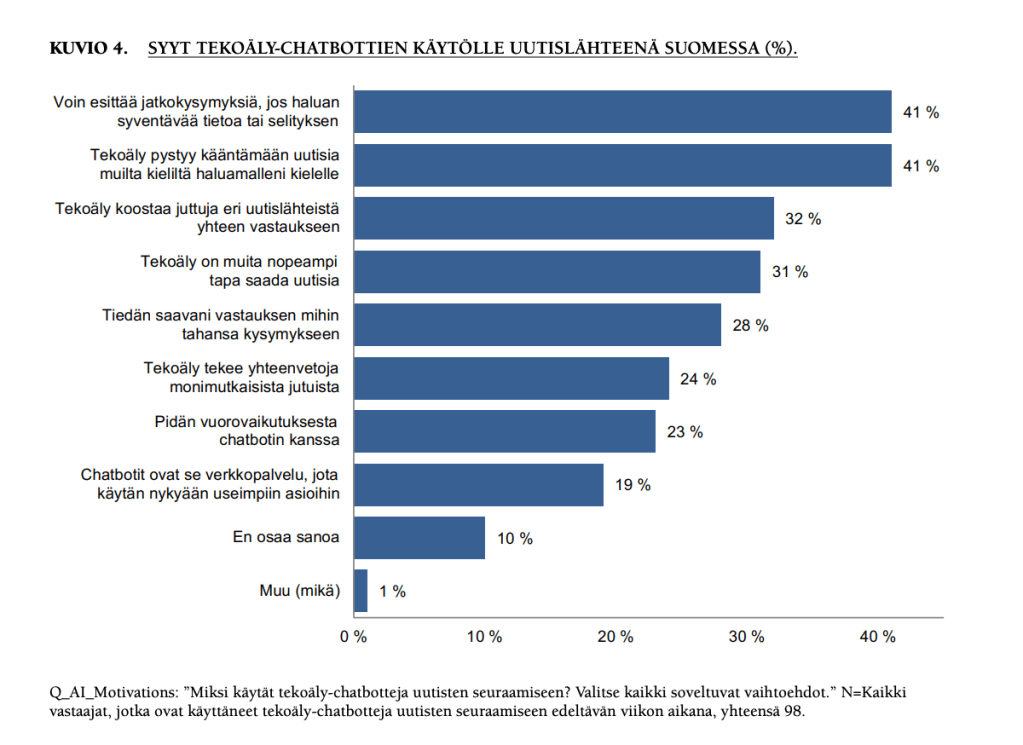
Yleisimmät syyt tekoälypalveluiden käytölle uutislähteenä on suomalaisten mielestä mahdollisuus esittää jatkokysymyksiä, kääntäminen sekä mahdollisuus koosteen saamiseksi yhteen vastaukseen.
Isossa kuvassa Suomessa tekoälypalveluiden uutiskäyttö on toiseksi vähäisintä tutkimuksen yli 40 maasta.
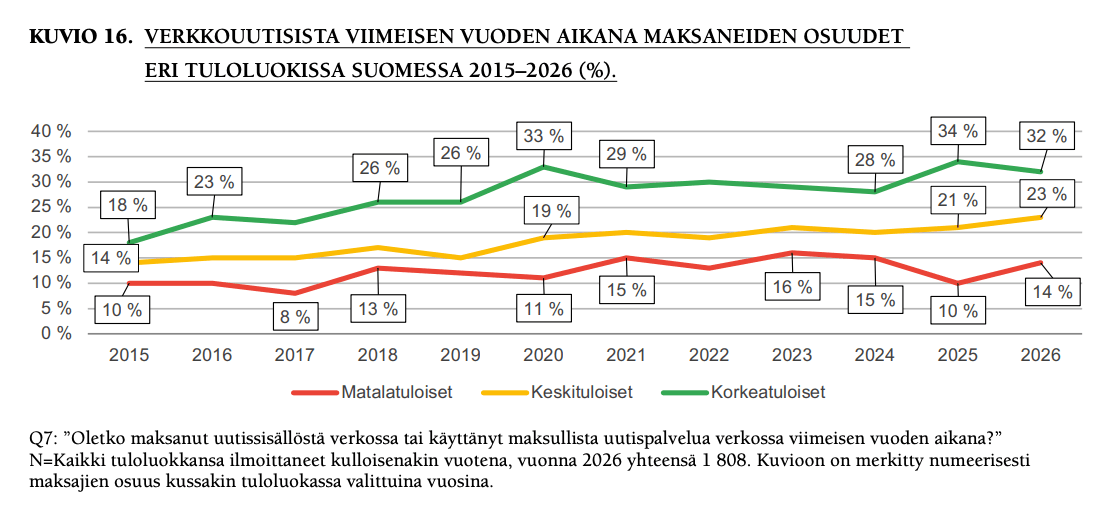
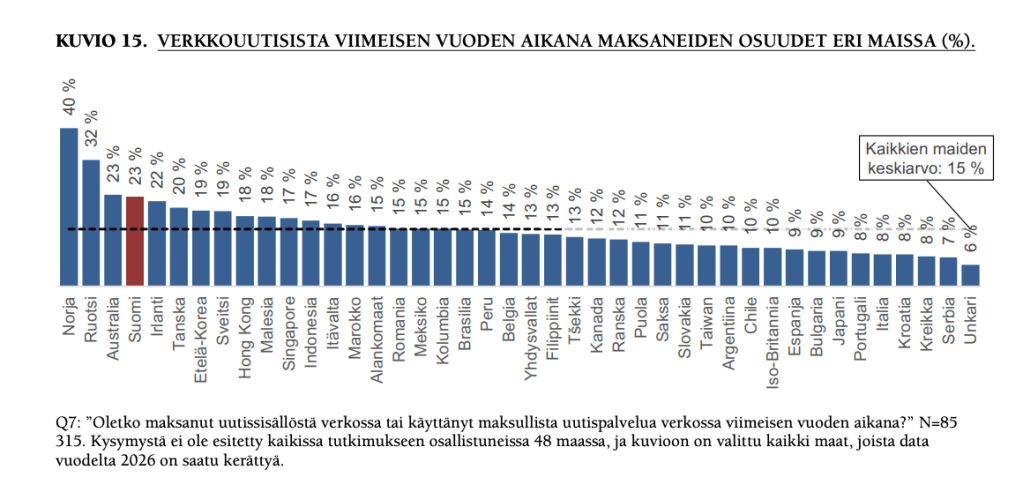
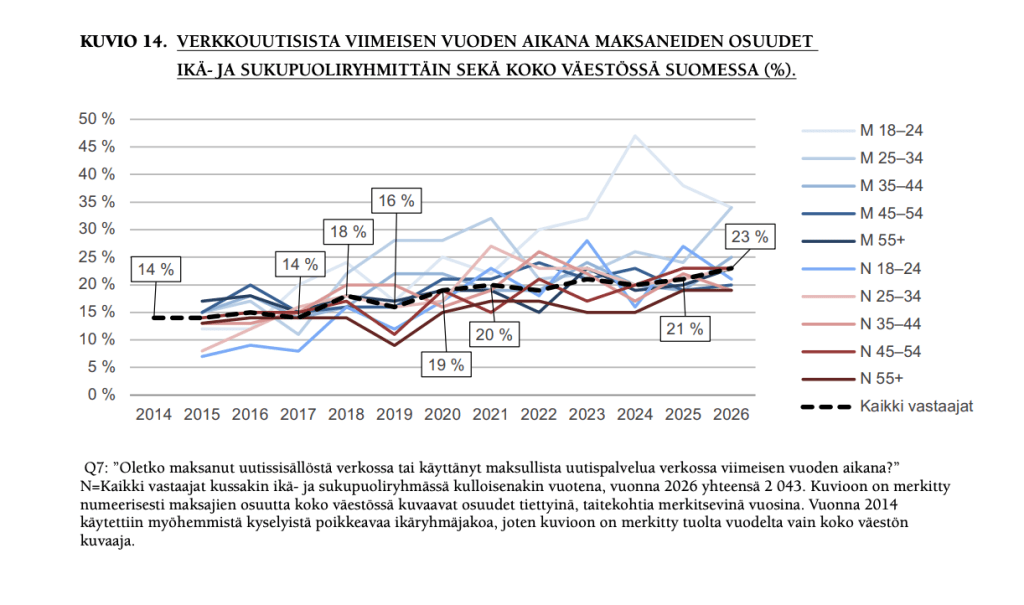
3) Verkkouutisista maksaneiden osuus kasvaa(vähän, mutta kasvaa). 23 prosenttia kertoo maksaneensa verkkouutisista viimeisen vuoden aikana (edeltävänä vuonna 21).
Suomalaisten maksuhalukkuus on tutkituista maista kolmanneksi korkein, eli voisi ajatella, että potentiaaliakin vielä riittää.
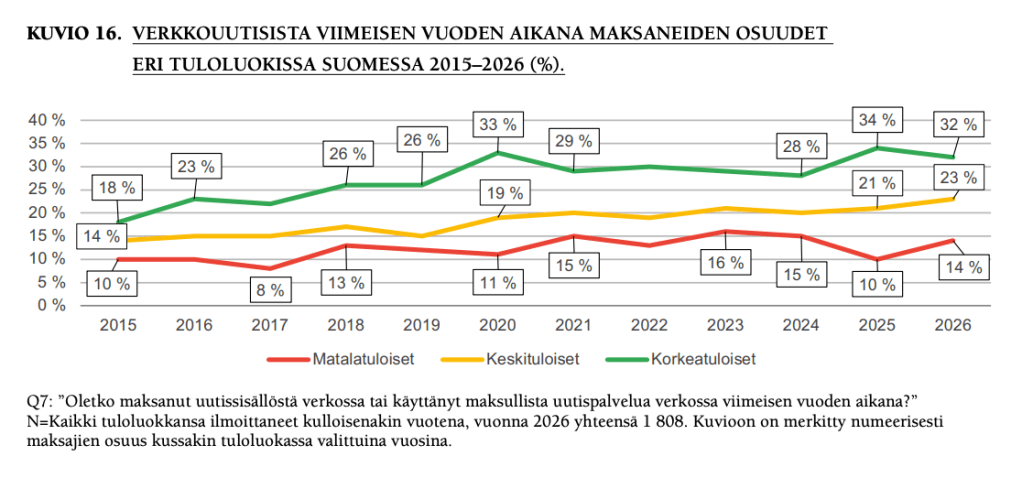
Omaan silmään kiinnostava detalji on, että matalatuloisten verkkouutisista maksamisessa on tapahtunut neljän prosenttiyksikön hyppäys ylöspäin vuodessa, toki vuosi 2025 näytti olevan jonkinlainen poikkeus (10), kun edellisvuosina taso on ollut 11-16 prosentin luokkaa.
Iso kuva näyttää siltä, että verkkouutisista maksamisesta alkaa Suomessa tulla ”valtavirtainen tapa kuluttaa uutisia”, kuten raportissa todetaan.
Raportin mukaan alle 35-vuotiaiden joukossa ”identiteettiin ja yhteiskunnalliseen vaikuttamiseen liittyvät syyt ovat yleisempiä kuin vanhempien parissa: he maksavat uutisista, koska samastuvat uutisten tuottajaan ja koska haluavat tukea journalismia ja sen saatavuutta yhteiskunnassa”.
4)Vaikka verkkouutisista maksaminen on kasvanut, kiinnostus uutisia kohtaan yleisesti laskee, uutisten aktiivinen välttely yleistyy ja yhä useampi etsii uutisensa muualta kuin perinteisestä mediasta.
Uutisia usein välttelevien osuus on Suomessa seitsemän prosenttia. Se on kaksinkertaistunut vuodesta 2017. 31 prosenttia välttelee vähintään joskus (nousua neljä prosenttiyksikköä). Raportti summaa, että syyt tauon tarpeeseen voivat olla joko kognitiivisia (uutisväsymys) tai emotionaalisia (uutisten aiheuttamat negatiiviset tunteet). Raportissa todetaan, että uutismedian yksi suurimmista tulevaisuuden haasteista on juuri kasvava uutisväsymys.
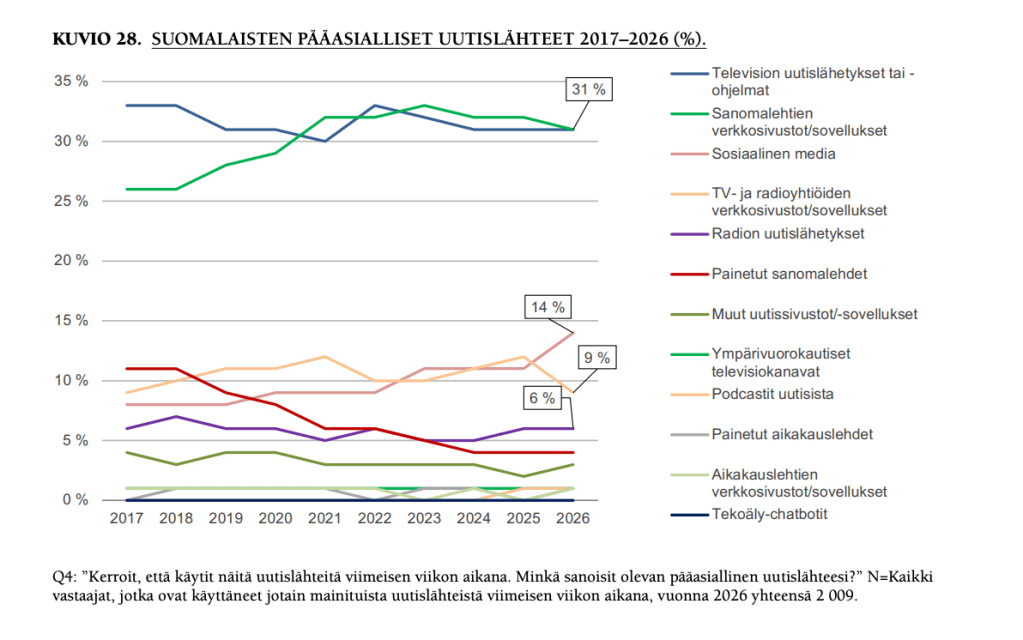
Sosiaalisen median rooli suomalaisten pääasiallisena uutislähteenä pompsahti taas ylöspäin (10 % -> 14 %). Podcastien rooli pääasiallisena uutislähteenä puolestaan tuli samaa luokkaa alaspäin.
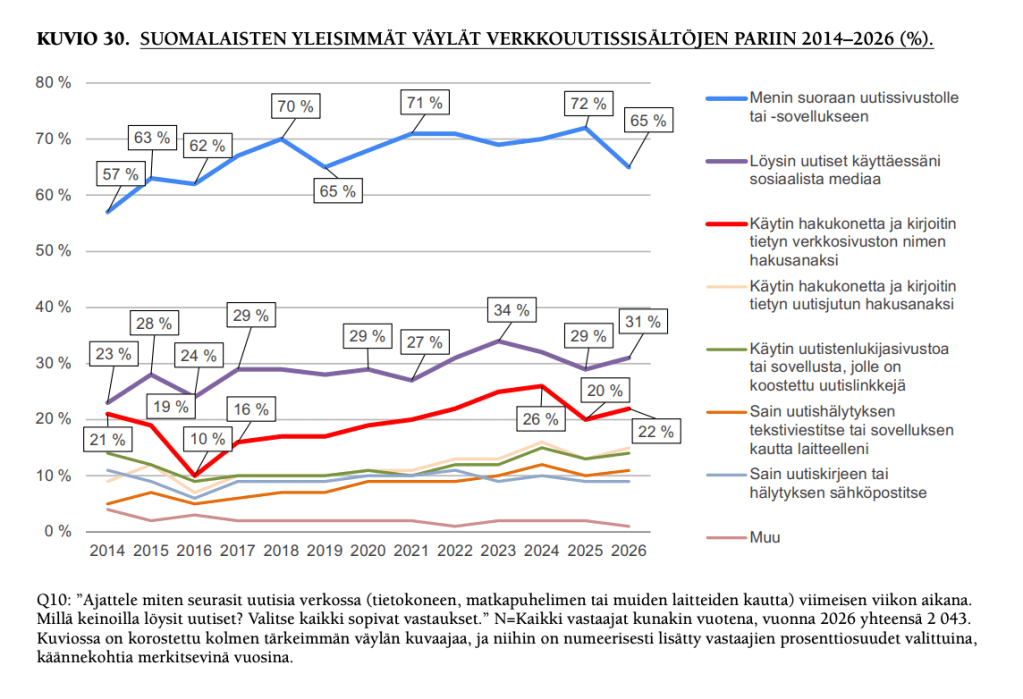
Maailmanlaajuinen trendi on, että suora liikenne uutissivustoille laskee. Tämä näkyy myös kyselytutkimuksessa: niiden suomalaisten osuus, jotka kertovat viimeisen viikon aikana menneensä suoraan uutissivustolle tai sovellukseen, on laskenut 65 prosenttiin 72:sta.
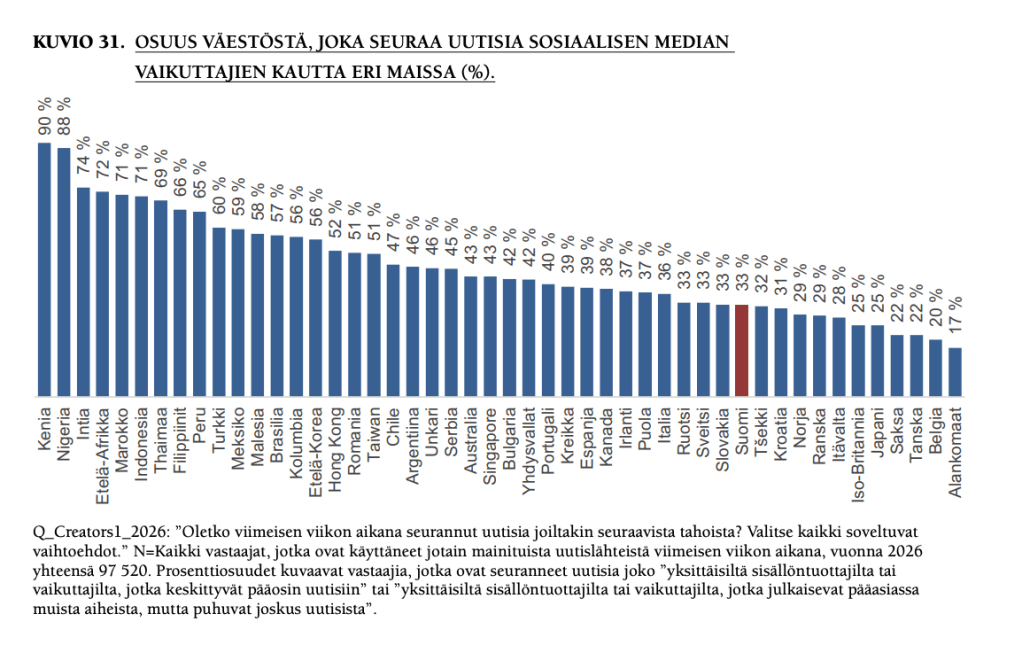
5)Suomessa joka kolmas seuraa uutisia sosiaalisen median vaikuttajien kautta. Tämä on kiinnostava tulos. Harva suomalainen kuitenkin kokee vaikuttajasisältöjen yksin riittävän tyydyttämään heidän tiedontarpeitaan (vain 8 %).
Vaikuttajasisältöjen kuluttajista enemmistö on sitä mieltä, että ne ovat jokaisella tarjotulla mittarilla samantasoista tai parempaa kuin perinteisen uutismedian sisältö. ”Selkein etumatka on aitouden, viihdyttävyyden, ymmärrettävyyden ja samastuttavuuden saralla.”
Alle 35-vuotiaista miehistä vaikuttajien kautta seuraa uutisia peräti 69 prosenttia ja samanikäisistä naisistakin enemmistö (53 %).
Raportin mukaan vaikuttajauutisilla on alle 35-vuotiaiden keskuudessa Suomessa parempi viikkotavoittavuus kuin millään perinteisellä medialla.
Vaikuttajia koskevat osuus oli kyselytutkimuksessa nyt uusi, eli aiheesta ei ole kysytty aikaisemmin. Kansainvälisesti vertailtuna Suomessa kulutetaan uutisia vaikuttajien kautta vielä melko vähän.
Oma kysymyksensä on, minkä asian kukakin kysyttäessä mieltää ”uutiseksi”.
Reuters-instituutin Digital News Report -tutkimus vertasi uutisten käyttöä 48 maassa. Suomessa kyselyyn vastasi noin kaksituhatta henkilöä alkuvuodesta 2026.Maaraportin löydät siis täältä.
Koosteitani edellisvuosien vastaavista raporteista voit lukea täältä.
Tapahtuman sessioiden nimiä (kuvitus: Gemini). Olen jäsentänyt 41 sessiota tässä kirjoituksessa seitsemän teeman alle lukemisen helpottamiseksi.
Kolme ihmistä rakentaa journalistista organisaatiota, jolla on heidän lisäkseen kolme nimettyä Claude-agenttia “co-founderina” — kukin omalla roolillaan ja vastuualueellaan (Ryan, Justin, Liz).
Lehti, joka kehitti kolmessa kuukaudessa yli sataa lähdettä automaattisesti seuraavan työkalun toimittajille: RSS-syötteistä somen kautta erilaisiin hallinnon asiakirjoihin. Filosofia työkalun taustalla on “vibe engineering”.
Poliisiradion kaikki keskustelut kulkevat Raspberry Pi -tietokoneen kautta ja systeemi hälyttää Slackiin, jos jotain uutisarvoista tapahtuu.
Voittoa tavoittelemattoman organisaation tutkivat toimittajat löysivät parhaan tekoälytyökalunsa, ja se ei ole tekoälychat, vaan Google Sheets.
Milloin rakentaa tekoälytyökalu itse, milloin ostaa se ulkoa ja milloin olla tekemättä mitään? Tähän löytyy useampikin malli uutismediasta.
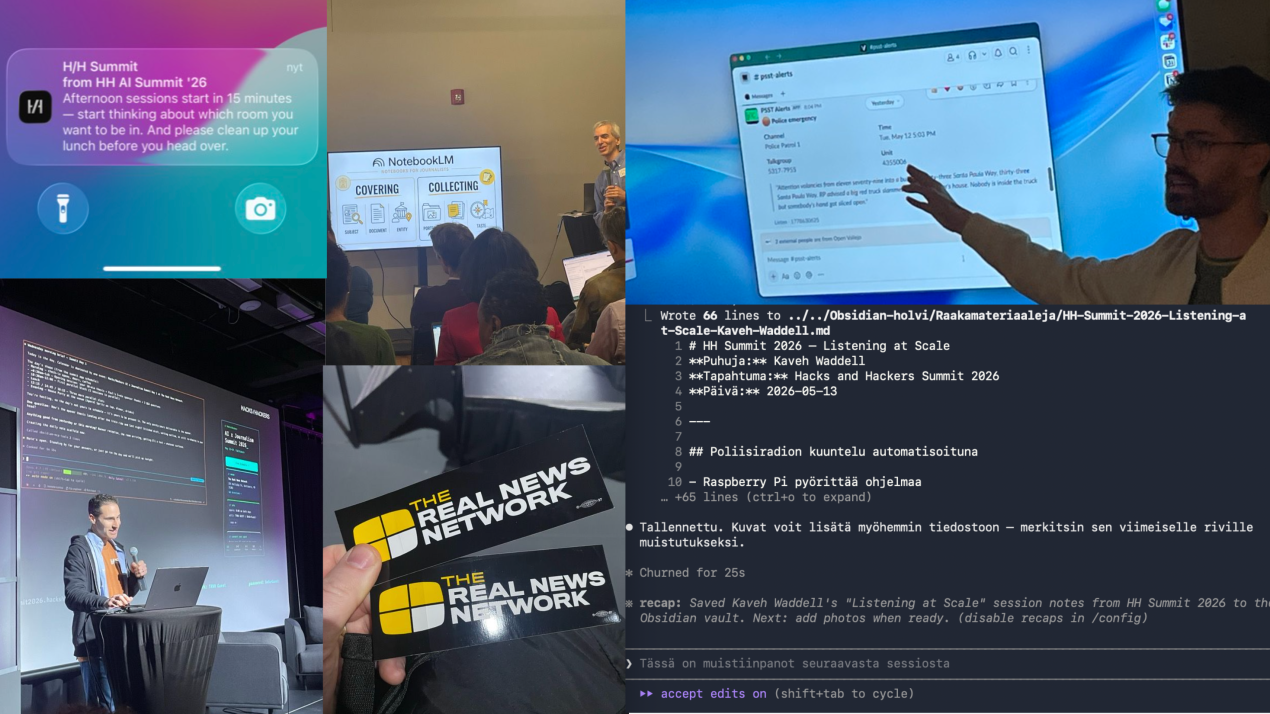
Muun muassa nämä esimerkit tulivat vastaan kahden päivän aikana Hacks and Hackers AI × Journalism Summit -tapahtumassa Baltimoressa 13.-14. toukokuuta 2026.
Tapahtuman anti oli sen verran konkreettinen, että päätin purkaa kaikki yli 40 sessiota lyhyesti tähän kirjoitukseen. Ne joissa olin itse mukana tekemässä muistiinpanoja, olen avannut laajemmin. Otsikkoteemoitus on minun, jotta kokonaisuutta olisi helpompi hahmottaa.
Tapahtumaan kokoontui kaikkiaan kolmesataa journalistia, kehittäjää ja median ammattilaista.
TEEMA 1: Milloin ostaa, milloin tehdä itse ja milloin luopua koko ideasta?
SESSIO: Build, Buy, or Ignore: A Framework for Prioritizing AI in News Organizations
Shira Center (Boston Globe Media), Aimee Rinehart (Frontier Collective), Chase Davis (Local Angle), Paris Brown (Baltimore Times)
”Voisiko AI auttaa tässä?”. Jokainen on kuullut tämän kysymyksen organisaatiossaan. Session pointti oli, että kaikille ei voi vastata kyllä, eikä pidäkään. Sessio tarjosi mm. kolmivaiheisen mallin, jonka avulla uutisorganisaatio voi päättää, kannattaako jokin AI-hanke toteuttaa itse, ostaa valmiina tuotteena vai jättää kokonaan väliin. Mallin kolme vaihetta ovat Impact (edistääkö se tavoitteitasi), Risk (miten huonosti käy jos kaikki menisi pieleen) ja Commonality (ovatko muutkin tässä samassa tilanteessa). Hyvä esimerkki medioiden haasteista käytännössä: Boston Globe rakensi 2023 itse Slack-botin otsikkoehdotuksia varten, 2024 markkinoille tuli valmistuotteita jotka tekivät saman asian, ja 2025 Globen julkaisujärjestelmän sisälsi kaikki samat ominaisuudet valmiina.
Omat muistiinpanoni yo. sessioon:
Konkreettisin esimerkki tuli Baltimoresta: piskuinen kolmen hengen paikallislehti rakensi AI-työkalun, joka auttaa toimittajaa etsimään uutisaiheita ja tuottaa artikkeliluonnoksen suoraan julkaisujärjestelmään. Koko työkalu maksoi alle 2 000 dollaria ja ostettiin ulkoiselta kumppanilta, koska se oli käytännössä ainoa vaihtoehto. Kaikki meni hyvin. Panelisti Paris Brownin vinkki oli hyvä: “Testaa jokainen työkalu sillä metodilla, että mikä on pahinta mitä voi tapahtua, jos kaikki menee pieleen. Useimmiten ei kovinkaan pahaa.”
SESSIO: Building Better Products With AI
Aldana Vales (CUNY), Scott Klein, Julia Moak (Greenpointers), Kalle Pirhonen
Olin itse mukana tässä paneelissa osana AI Builders -kurssini lopputyötä sivuavaa keskustelua. Sessio käsitteli sitä, miten tekoälyä voidaan käyttää tuotteiden rakentamiseen tavalla, joka on aidosti hyödyllinen, luotettava ja yleisöjen tarpeisiin vastaava.
SESSIO: Smart, Confident, and Wrong: Designing Responsible A.I. Tools in the Newsroom
Dylan Freedman & James O’Toole (The New York Times)
New York Timesin tuotekehitystiimi purki ongelman, joka on tuttu kaikille tekoälyn kanssa työskenteleville: AI-järjestelmät kuulostavat vakuuttavilta myös silloin, kun ne ovat väärässä. Sessiossa kerrottiin, miten vastuullinen tuote- ja käyttöliittymäsuunnittelu voi auttaa. Käytännön esimerkit tulivat NYT:n omista sisäisistä työkaluista, kuten Cheatsheetistä, jolla käsitellään laajoja datamassoja strukturoidusti.
SESSIO: Are U.S. Journalists Getting Lapped in the AI Race?
Amy Mitchell (Center for News, Technology & Innovation), Akintunde Babatunde (Centre for Journalism Innovation and Development), Gordon Saft (Rest of World)
Sessiossa käsiteltiin tutkimusta, joka vertailee tekoälyn käyttöönottoa uutisorganisaatioissa eri maissa.
SESSIO: The Blueprint for Success: How to Get Buy-In and Build AI Systems That Actually Work
Ryan Struyk (CNN), Heather Ciras McCarthy (Boston Globe), Rubina Fillion (The New York Times), Ole Reissmann (SPIEGEL-Group)
Monet toimitukset kokeilevat tekoälyä, mutta harvat onnistuvat muuttamaan kokeilut järjestelmiksi, joita toimittajat käyttävät paljon ja säännöllisesti. Paneeli käsitteli sitä, miten toimittajat, insinöörit ja tuotejohtajat saadaan samalle aaltopituudelle. Yhteinen teema oli se, ettei pelkkä tekninen toteutus riitä: muutosjohtaminen, luottamuksen rakentaminen ja yhteiset käytännöt ovat yhtä tärkeitä kuin itse työkalut.
TEEMA2: Tekoäly silmäparina — signaaliseuranta ja uutisten löytäminen
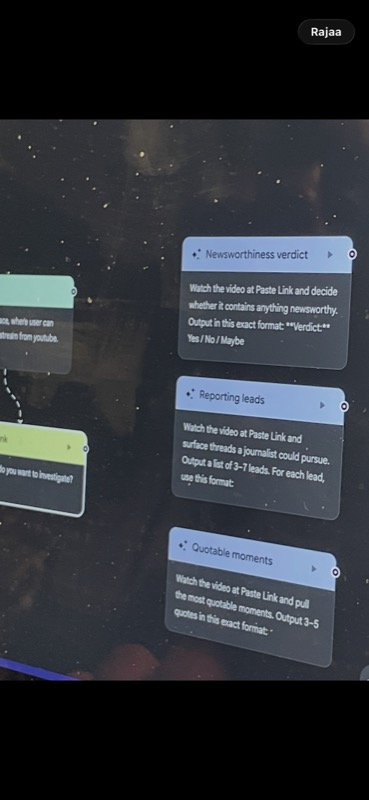
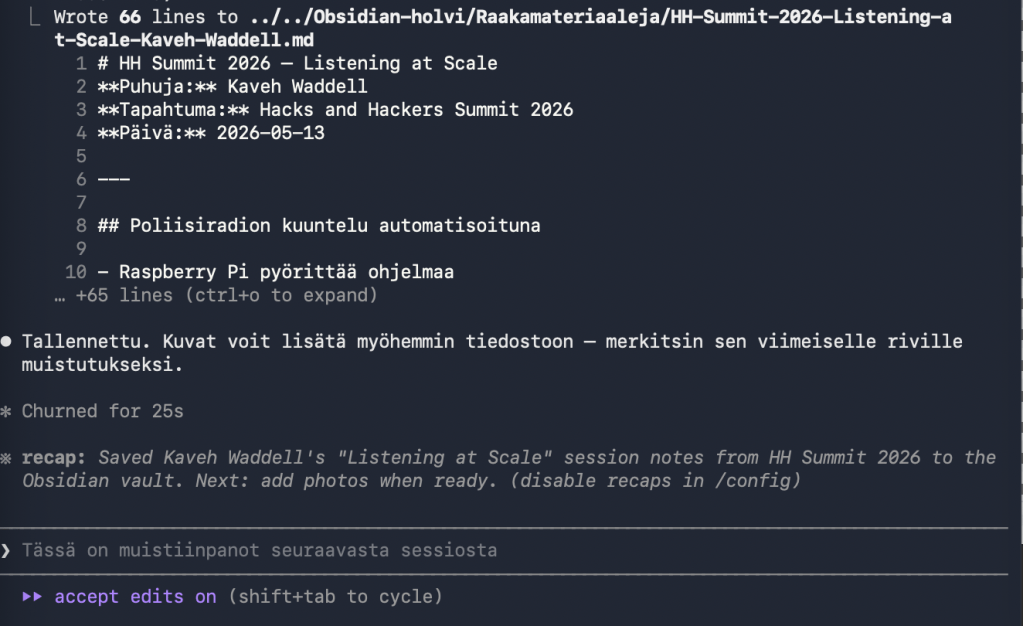
Listening at Scale: Building AI Tools for Audio and Video Monitoring
Kaveh Waddell (Verso)
Toimittajat hukkuvat audioon ja videoon, jota he eivät pysty seuraamaan: kaupunginhallitusten kokoukset, poliisiradiot (Yhdysvalloissa), podcastit ja suoratoistosisällöt. Waddell esitteli, miten AI-järjestelmät pystyvät kuuntelemaan ja katsomaan puolestasi. Käytännön esimerkkejä oli kaksi: ensimmäisessä poliisiradiota seurataan Raspberry Pi:llä pyörivällä järjestelmällä, joka litteroi jokaisen puhelun automaattisesti ja lähettää hälytyksen Slack-kanavalle vain silloin, kun jotain uutisarvoista tapahtuu. Toinen esimerkki oli työkalu, joka litteroi kaikki Joe Roganin podcastit tekstuaalisesti etsittävään ja vertailtavaan muotoon.
Omat muistiinpanoni yo. sessioon:
Audio ja video ovat yhä alihyödynnetty kulma media-alalla suhteessa tekoälyyn, mistä puhuttiin myös tässä sessiossa.
Waddell korosti, että poliisiradiotyökalu ei ole täydellinen, mutta se on tarpeeksi hyvä säästämään valtavasti aikaa. Waddell nosti esiin neljä keskeistä kysymystä ennen kuin alkaa rakentamaan tällaista monitorointijärjestelmää: reactive vs. proactive (milloin hälytät), human in the loop (missä kohdassa ihminen on mukana), alert vs. synthesis (yksittäisiä hälytyksiä vai yhteenvetoja) ja transcription vs. native input (käytätkö litteroitua tekstiä vai audiota suoraan syötteenä).
Kiinnostavaa tässä sessiossa: pääsimme kokeilemaan Googlen Opalia, jolla voi agenttisesti luoda sovelluksia. Käyttöliittymä muistuttaa hieman n8n- tai Make-automaatioalustoja. Opalia ei toistaiseksi voi käyttää Suomessa:
Google Opal
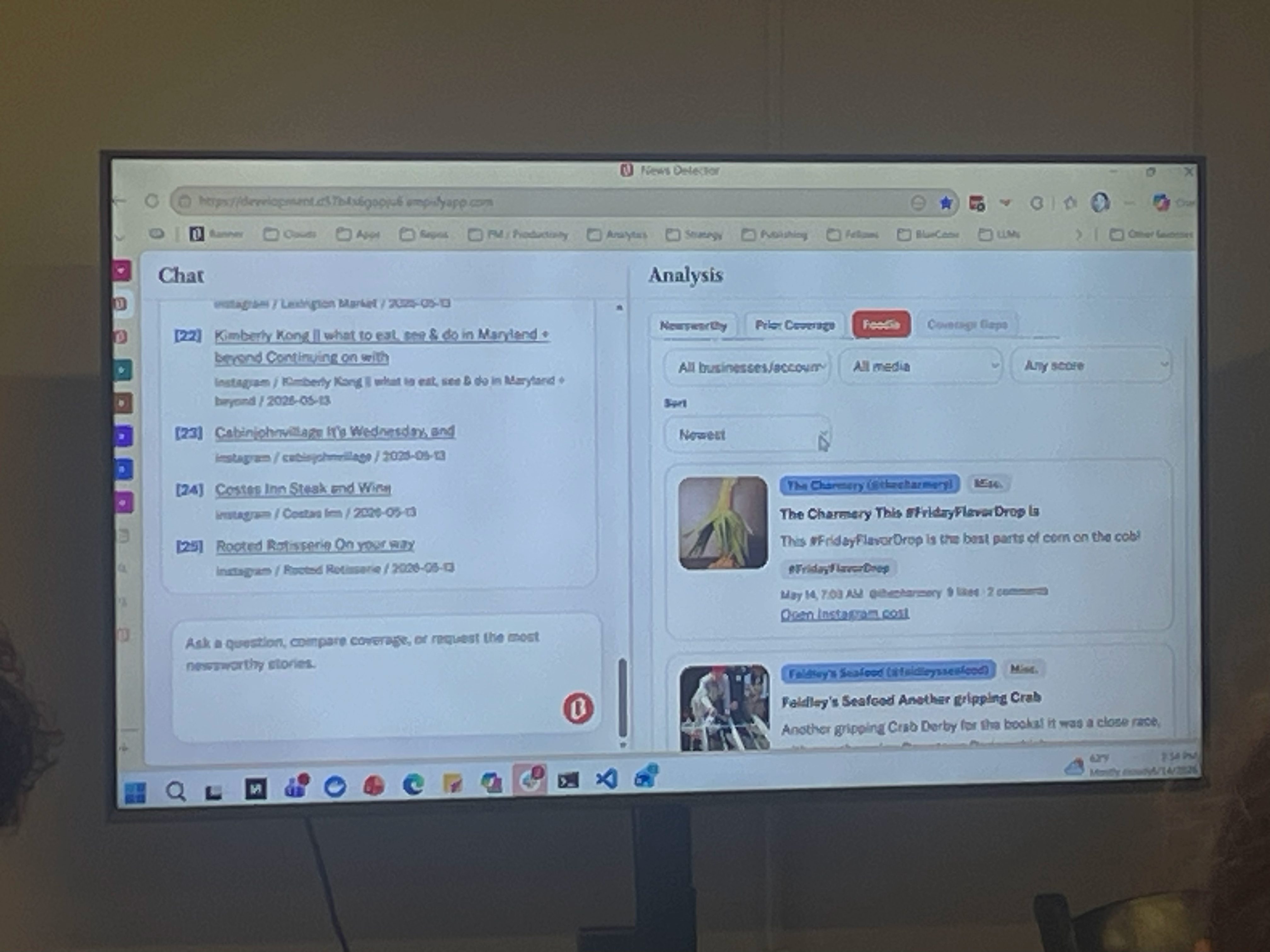
Building an AI Tool That Finds News Amid the Noise
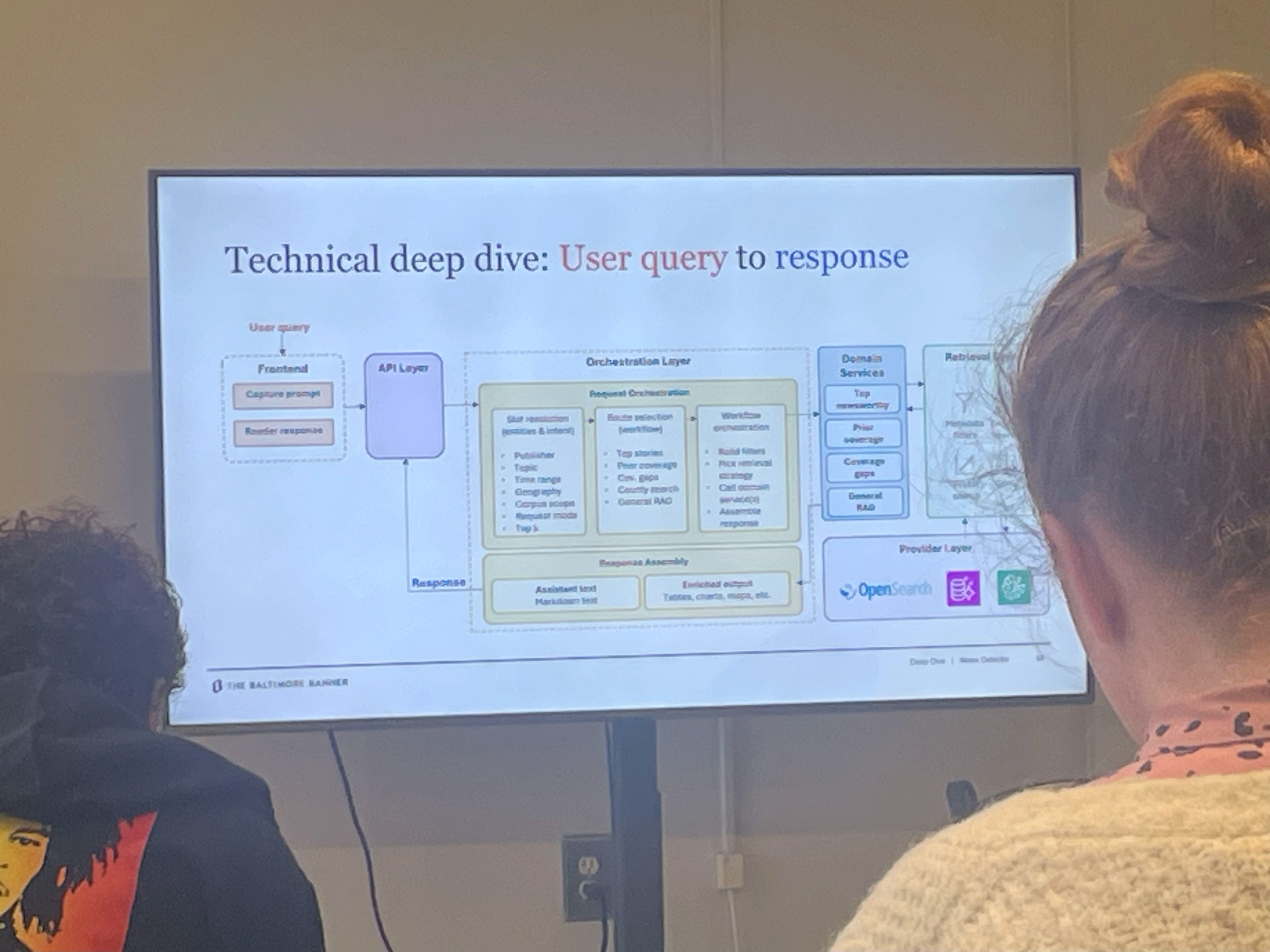
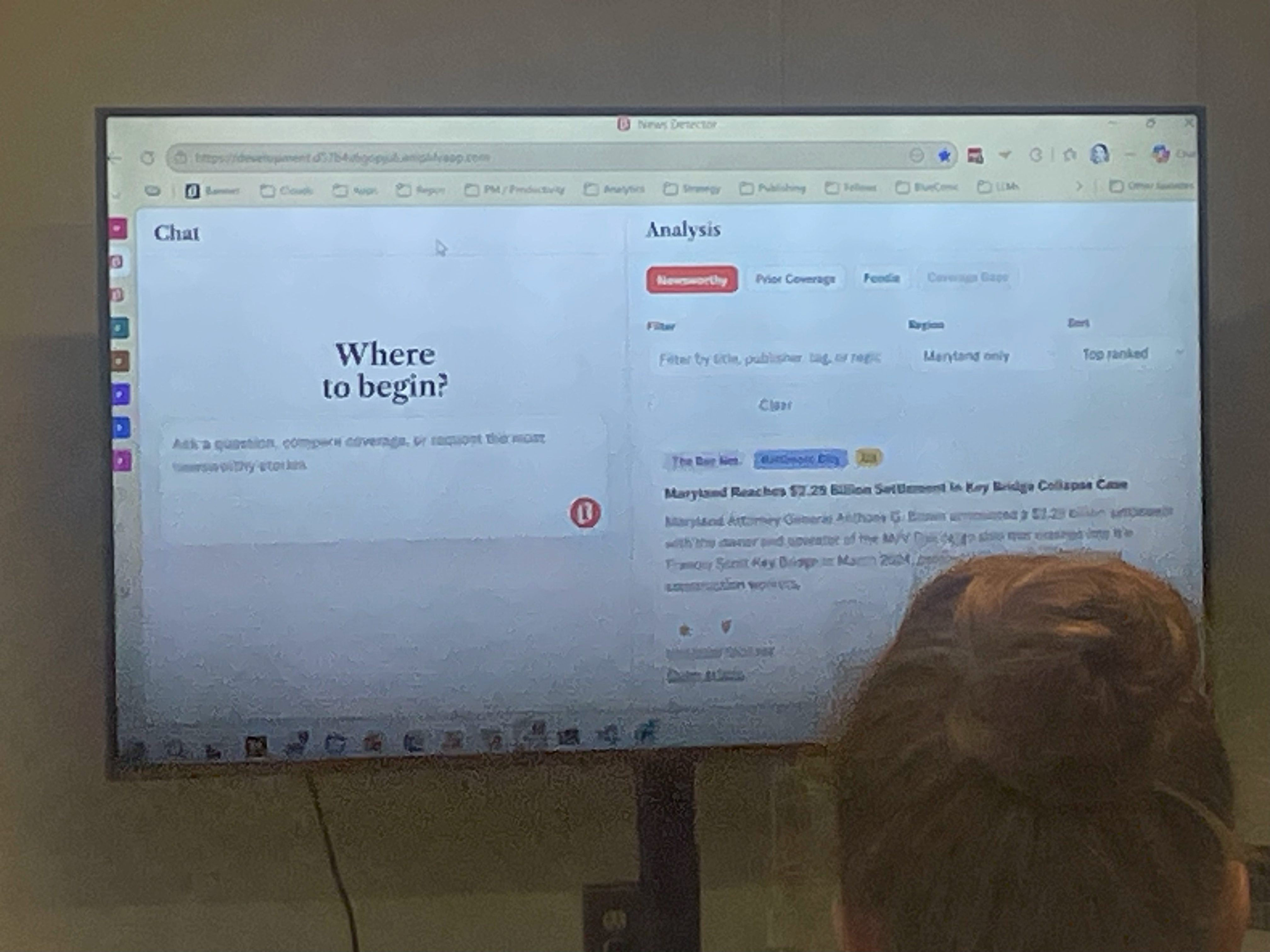
Peter Rasmussen & Biswajit Ganguly (The Baltimore Banner)
Baltimore Bannerin News Detector -työkalu syntyi käytännön tarpeesta: toimittajat kävivät päivittäin manuaalisesti läpi kymmeniä ulkoisia lähteitä, ja laajentuminen uusille alueille teki siitä pullonkaulan. Ensimmäinen versio oli karsittu: se skreippasi paikallisia sivustoja, pisteytti aiheet ja lähetti ne toimitukselle Excel-tiedostona sähköpostilla.
Omat muistiinpanoni yo. sessioon:
Amerikkalainen Baltimore Banner rakensi kolmessa kuukaudessa vaikuttavan näköisen uutissignaalien seurantatyökalun, jossa on yli sata lähdettä RSS-syötteistä someen ja skreipattuihin sivustoihin. Sen ytimessä on uutisarvopisteytys, joka pohjautuu ihmisten määrittelemiin uutisarvokategorioihin, joiden täsmäävyyttä päivitetään koko ajan tuoreiden esimerkkien pohjalta. Päivitys tarkoittaa käytännössä sitä, että toimittajat antavat säännöllisesti palautetta työkalun arviointikyvystä (peukku ylös tai alas), mikä parantaa sitä vähitellen.
Rautalankaistettuna työnkulku on tällainen:
1. Kerääminen
Kone käy jatkuvasti läpi yli sataa lähdettä — uutissivustoja, somea (somessa hyödynnetään Apifyta), hallinnon asiakirjoja. Se siivoaa datan yhtenäiseen muotoon.
2. Pisteytys
Jokainen artikkeli tai sisältö menee tekoälyn läpi, joka arvioi, onko siinä vaikuttavuutta, konfliktia tai paikallisuutta ja missä määrin. Tekoäly tekee tulkinnan, mutta varsinainen numero lasketaan sääntöpohjaisella koodilla.
3. Haku ja vastaus
Kun toimittaja kysyy jotakin (kuten ”Mitä tärkeää tapahtui tällä viikolla Baltimoressa?”), järjestelmä hakee relevantin materiaalin kolmella tavalla: hakusanoilla, vektorihaulla ja metadatasuodatuksilla. Sitten se kokoaa vastauksen ja näyttää sen chatissa sekä rikastettuna listauksena vieressä.
Omat ajatukseni:
Sivustojen skreippaamisen eettinen puoli ei näytä Yhdysvalloissa lainkaan vaivaavan mediatoimijoita, tuntuu siltä että kaikki tekevät sitä. Tämä yllätti. Somen osalta Baltimore Bannerin työkalu käyttää Apifytä, jonka kanssa ainakin Euroopassa liikuttaisiin vähintäänkin harmaalla alueella. Asian toinen puoli on se, että usea yhdysvaltalaisemedia näyttää ottaneen uutisseurannan automatisoinnissa isoja harppauksia viimeisen vuoden aikana. Sanoisin, että alkavat olla jo paikoin edellä eurooppalaisia.
Baltimore Bannerin työkalun pääkehittäjä avasi teknistä filosofiaansa toteamalla, että heidän työkalunsa on vibekoodauksen hengessä rakennettu, mutta insinöörityön kurilla strukturoitu järjestelmä. Hän käytti termiä “vibe engineering”. Käytännössä pääkehittäjä vibekoodasi itse esimerkiksi käyttöliittymän työkalulle, vaikka korosti, että ei ole mikään ohjelmointimaailman moniottelija.
Why You Should Use AI to Monitor Local Meetings
Stephen Stirling & Kevin Hoffman (Philadelphia Inquirer)
Yhdysvalloissa on 90 000 paikallishallinnon yksikköä, ja uutismedia seuraa niistä yhä pienempää osaa. Stirling ja Hoffman esittelivät, miten raaka-audio tai -video kaupunginhallituksen kokouksesta muuttuu toimittajan kannalta hyödylliseksi tiedoksi.
Building Sparks: What We Learned Turning 1.2 Million Story Pickups Into an AI-Powered Recommendation Engine
Ken Romano & Cole Carter (Stacker)
Sessiossa kerrottiin, miten Stackerin 1,2 miljoonan jutun arkistoaineistosta rakennettiin AI-pohjainen suosittelumoottori journalisteille.
Building Beat Books From News Archives
Derek Willis (University of Maryland)
Useimpien uutismedioiden arkistot sisältävät paljon sellaista tietoa, jota harva toimittaja koskaan lukee. Willis Marylandin yliopistosta esitteli metodin, jolla tätä tietoa hyödynnetään. ”Beat book” on toimittajakohtainen tietopohja omasta vastuualueesta, koottu AI-avusteisesti arkistosta. Käytäntö toimii myös uusien toimittajien perehdyttämisessä.
TEEMA3: AI yhteistyökumppanina — agentit ja muisti
How a Three-Person Startup Added AI as the Fourth Co-Founder
Justin Bank & Ryan Kellett (The Independent Journalism Atlas)
Independent Journalism Atlas on verifioitu tietokanta yli 1 200 vaikuttaja-journalistista (paremman suomenkielisen vastineen puutteessa käytän tätä), jotka tekevät journalismia perinteisten medioiden ulkopuolella. Startupilla on kolme perustajaa, ja lisäksi kolme muuta “founderia”, jotka ovat Claude-agentteja. Yhtiö julkaisee live-datatuotteita, interaktiivisia visualisointeja ja uutiskirjeitä, joista kaikki hoituvat ihmisen ja tekoälyn yhteistyönä.
Omat muistiinpanoni yo. sessioon:
Tämä sessio oli tapahtuman kiinnostavimmasta päästä. Heillä on kolme nimettyä agenttia: Ryan hoitaa datan puhdistuksen ja metodologian, Justin kehityksen ja visualisoinnit, Liz strategian ja kumppanuudet. Jokainen agentti on saanut roolin, kontekstin ja muistin.
Muistiongelman he ratkaisivat kahdella Markdown-tiedostolla: CURRENT_STATE.md (mitä on tehty, mikä on rikki, mitkä ovat seuraavat askeleet) ja MEMORY.md (miksi tämä on olemassa, mitä päätöksiä on tehty, miltä ”hyvä” näyttää).
Tämä käytäntö herätti kysymyksiä: yrityksen jokainen palaveri, myös 1:1-keskustelut, nauhoitetaan ja litteroidaan Granola-nimisellä ohjelmalla ja viedään tekoälylle .md-tiedostona. ”Me voimme tehdä näin — emme ole suuri media.”
He kertoivat myös suoraan, missä tällainen agenttinen co-founder-malli epäonnistuu: Claude hylkäsi aluksi ruokajournalistit soveltaen ”accountability”-kriteeriä liian kapeasti. Pitkissä sessioissa tulee joskus ongelmia. Kerran Claude ehdotti yrityskauppaa lukemalla “rivien välistä” palaverimuistiinpanoista. Tärkein opetus oli, että tekoälylle on annettava selkeä rooli, ei vain käyttötapauksia referenssiksi.
AI Coding Agents for Investigative Journalism
Nick Hagar (Northwestern University)
Sessiossa käytiin läpi sitä, miten Claude Code muuttuu nopeasta mutta riskialttiista assistentista järjestelmälliseksi yhteistyökumppaniksi. Keskeinen viesti oli, että: arvot kuten ”ole läpinäkyvä” eivät riitä sellaisenaan, vaan ne on kyettävä muuttamaan konkreettisiksi toimintasäännöiksi. Hagarin mielestä hyvä skill sisältää seuraavat asiat (en käännä näitä suomeksi, ettei ajatus katoa käännettäessä): Purpose, Allowed work, Review gates, Preservation rules, Documentation outputs, Claim discipline ja Stop conditions.
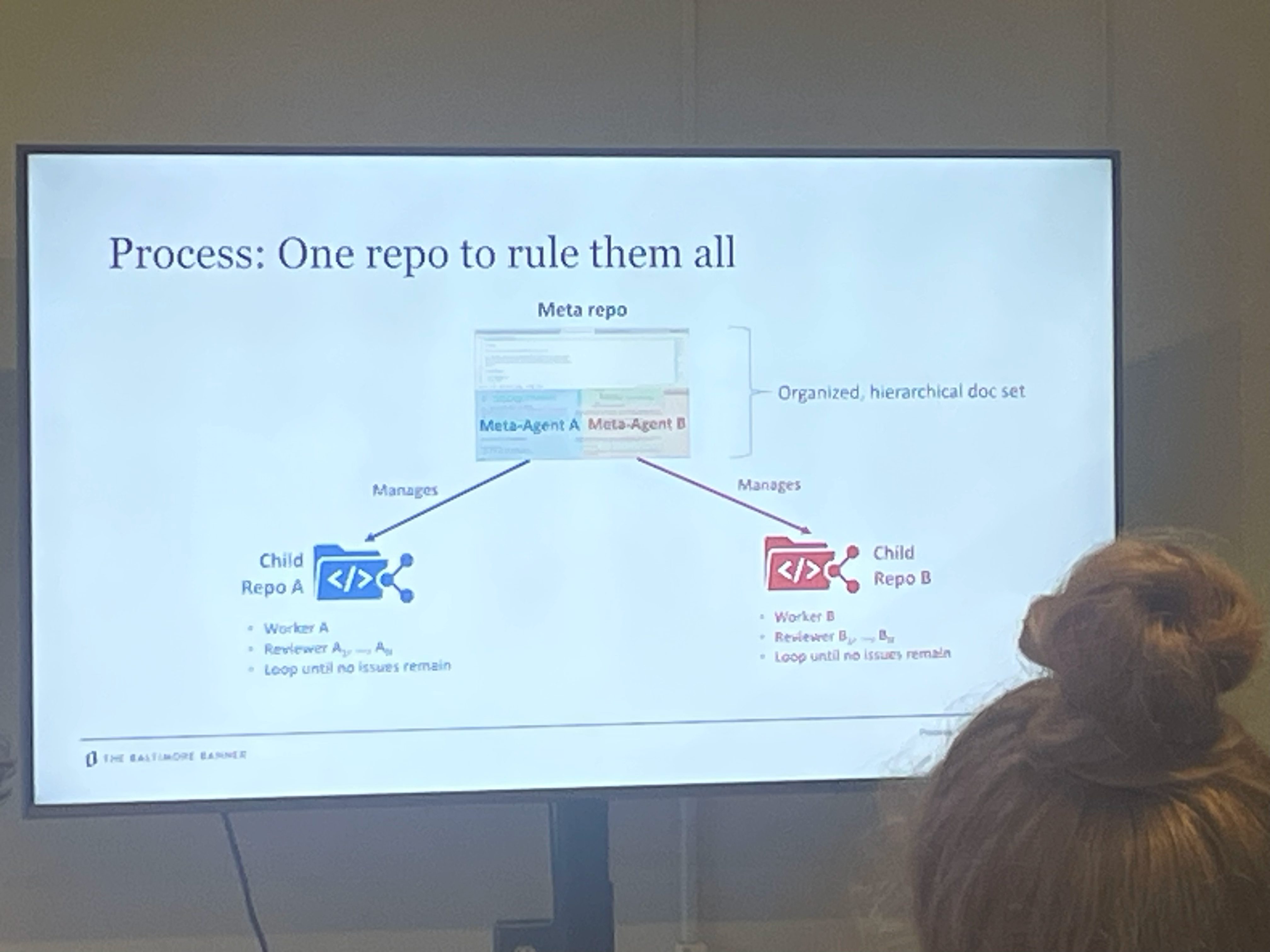
A Decentralized Agentic-AI Editorial Board for an International Newsroom
Session osallistujat prototyyppasivat pienryhmissä AI-toimitusrakenteen, jossa eri agentit vastaavat eri osa-alueista, kuten faktantarkistuksesta tai otsikoinnista. (vähän samaan tapaan kuin AI:n johtama uutistoimitus -hanke Suomen Tampereella, mutta)
What’s Your Problem?
Paige Moody (Hacks/Hackers & Big Local News), Jake Kara (Hacks/Hackers Newsroom AI Lab)
Session lähtökohtana oli, että monissa AI-kehitysprojekteissa ratkaistava ongelma on jäänyt epämääräiseksi. Osallistujat harjoittelivat oman ongelmansa terävöittämistä ennen kuin tekoäly otetaan mukaan.
Next-Gen NotebookLM: 9 Bold and Impactful New Things Newsrooms Can Do
Jeremy Caplan (CUNY Newmark Graduate School of Journalism)
Caplan esitteli yhdeksän käyttötapaa, jotka muuttavat NotebookLM:n tiivistämistyökalusta kriittiseksi yhteistyökumppaniksi: ne haastavat lähteitä, paljastavat aukkoja ja testaavat oletuksia sen sijaan, että vain tiivistäisivät sisältöä. NotebookLM:n perusarkkitehtuuri koostuu kolmesta osiosta: Sources (lähteet), Explorer (haku luonnollisella kielellä) ja Studio (tuotosten luominen).
Iso suositus muuten Caplanin Wondertools-uutiskirjeelle!
Omat muistiinpanoni yo. sessioon:
NotebookLM on edelleen alikäytetty työkalu journalismissa. Itselleni se on tuttu, mutta aina uusimmista ominaisuuksista ei ehdi pysyä kärryillä. Caplanin esityksen perusteella on kokeiltava ainakin Data Tablesia, joka muuttaa minkä tahansa lähdemateriaalin taulukkomuotoon. ”Very powerful”, totesi Caplan.
Uusi ominaisuus on myös automaattinen lähteiden järjestäminen, eli jos olet liittänyt työkaluun vaikka 50 lähdettä, tekoäly järjestää ne nyt loogisesti halutessasi. Studio-osion tärkein vinkki oli, että yhä useampaa toimintoa voi nyt räätälöidä itse. “Älä paina nappia suoraan, vaan kustomoi kolmen pisteen takaa, kerro mitä haluat. Lopputuloksessa on iso ero.”.
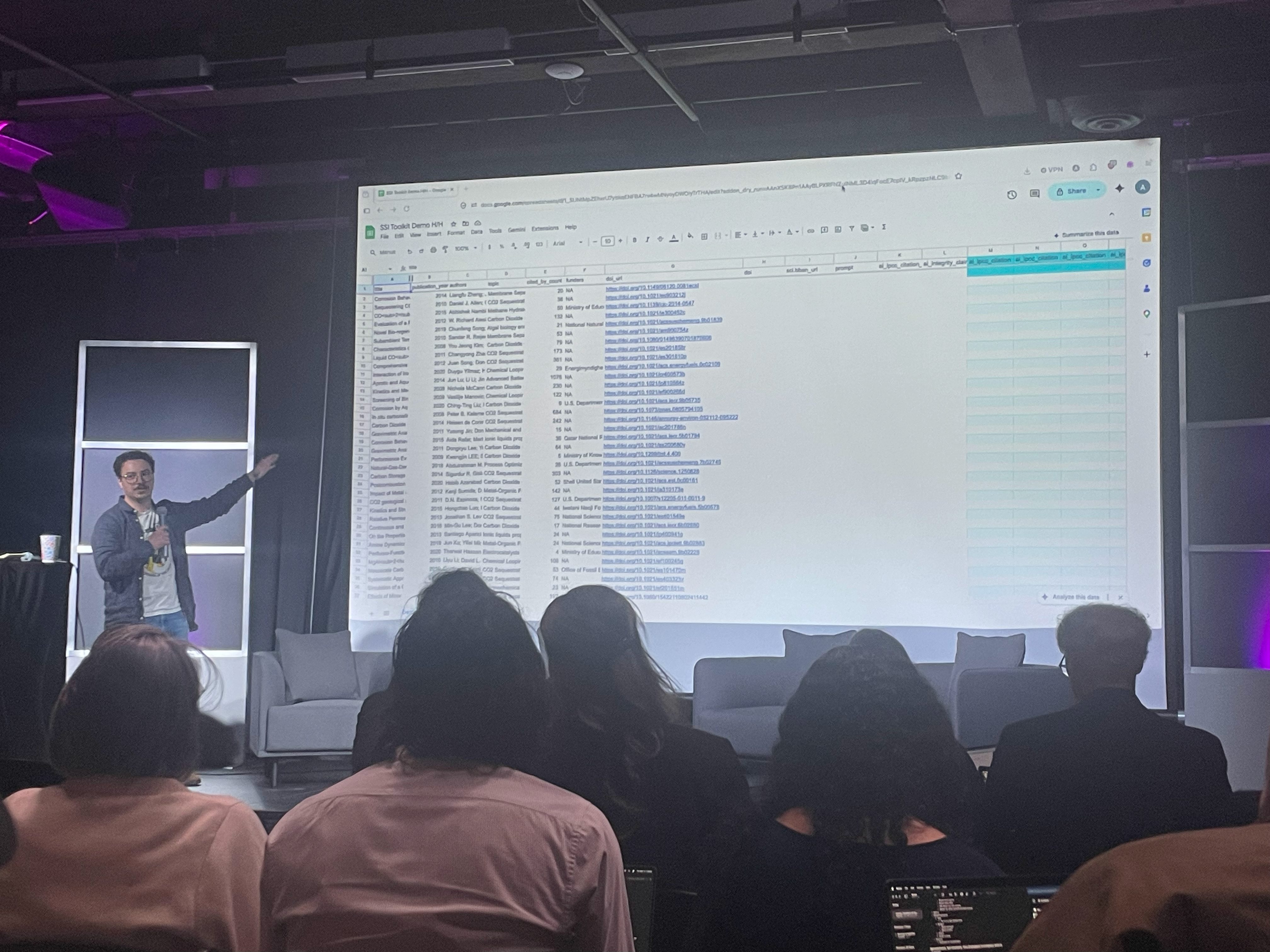
Spreadsheets, Not Chatbots: How ProPublica Investigates With AI
Aaron Brezel (ProPublica)
”Chatbots are claw machines to pull up stuffed animals. It is not ideal for investigative reporting.” Tämä oli Brezelin lähtökohta: chatbotit ovat arvauskoneita, eivätkä ideaaleja täsmällisyyttä vaativaan työhön.
ProPublicassa tutkiva journalismi tapahtuu jo nyt usein taulukoissa (Google Sheetseissä), jollaisen luotettava käsitteleminen chatbotin kautta on hankala ratkaisu. ProPublican vastaus on Spreadsheet Inference (SSI), jossa Google Sheets kytketään Geminin REST API:iin rivi kerrallaan. Tällöin AI tekee tulkinnan ja deterministiset säännöt laskevat lopputuloksen.
Omat muistiinpanoni yo. sessioon:
Tämä oli harvoja sessioita, joissa oli vaikea pysyä kärryillä, mitä tässä oikein tapahtuukaan. En ollut tietoinen, että Sheetsiin pystyy kytkemään Geminin rajapintaa rivi riviltä. Mutta demotus oli vaikuttava. SSI Toolkit löytyy GitHubista: github.com/propublica/gas-ssi-toolkit/
Brezel heitti heti alkuun erinomaisen pointin: se mikä toimii tekoälyn hyödyntämisessä yhdessä mediassa, ei välttämättä toimi ollenkaan toisessa. Tämä johtuu siitä, että medioilla on eri kohderyhmät, eri tavoitteet ja erilaiset toimintakulttuurit. ProPublica on tutkivaan journalismiin erikoistunut voittoa tuottamaton järjestö, jonka asema mediakentässä on monella tapaa erikoinen. Se ei esimerkiksi pidä juttujaan vain omilla sivuillaan, vaan tekee paljon yhteistyötä.
AI as Your Data Desk Partner
Lauren Malkani (Seven Mile Media) & Nick Harbaugh (X-energy)
Sessiossa näytettiin, miten datasetti muuttuu juttuprototyypiksi Claude Coden avulla luonnollisella kielellä kysymällä.
Make Your Own Personal Coach
Sonya Quick (CalMatters & The Markup)
Quick kertoi, miten rakensi oman AI-valmentajan, joka haastaa hänen omaa ajatteluaan.
Using MCP to Analyze Text and Visualize Data
Hong Qu (Harvard Kennedy School)
Sessio näytti vaihe vaiheelta, miten rakenteistamaton teksti muuttuu taulukoiksi ja lopulta selkeiksi visuaalisiksi tuotoksiksi MCP:n avulla. Metodilla on potentiaalia erityisesti suurten tekstimassojen kuten poliittisten puheiden tai oikeusasiakirjojen systemaattisessa analyysissa.
MCP on eräänlainen tekoälysovellusten USB-portti.
Large Language Mathematicians: Public Records in Record Time
Tyson Bird (American City Business Journals)
American City Business Journals halusi työkalun, joka vinkkaa juttuaiheita julkisista asiakirjoista, mutta törmäsi jatkuvasti laskuvirheisiin. Sessiossa kerrottiin, miten ongelma ratkaistiin yhdistämällä kielimallin tekstinymmärrys deterministiseen laskentaan. Siinä tekoäly tunnistaa relevantit luvut ja kontekstin, mutta varsinainen matematiikka jätetään koodille.
TEEMA5: Rakentaminen ilman perinteistä ohjelmointitaustaa — vibekoodaus (tai kansalaiskoodaus)
Vibe Coding Jam Sessions
Kummankin päivän ohjelmassa oli avoin vibekoodaussessio ilman esitäytettyä esityslistaa: tuo läppäri, kerro mitä rakennat, jaa vinkit. Sessio oli avoinna kaikille, myös niille joilla ei ole perinteistä ohjelmointitaustaa.
From Concept to Code: Building Prototypes & Agents With Google AI
Etan Horowitz (Google)
Googlen sessio tutustutti osallistujat Googlen AI -ekosysteemiin, johon kuuluu mm. NotebookLM, Gemini, Stitch ja Flow. Tarkoituksena oli osoittaa, miten näitä työkaluja voidaan yhdistää uutistyöhön toisiinsa kytkettyinä komponentteina. Erityisesti Flow herätti kiinnostusta osallistujissa.
Rapid AI Prototyping Inside the Minnesota Star Tribune
Frank Bi (The Minnesota Star Tribune)
Kun Minnesota Star Tribune rakensi ensimmäisen yleisölle suunnatun AI-tuotteensa, prosessi vaati ”pirates in the navy” -asenteen. Bi kertoi, miten toimituksen sisällä piti luoda tilaa nopeille kokeiluille ilman, että jokainen askel vaati kymmentä hyväksyntää. Ydinajatus oli, että nopea prototyyppi, joka epäonnistuu, on arvokkaampi kuin pitkä suunnitteluprosessi, joka ei tuota mitään.
Pinpoint: Re-Thinking Our Product for the Age of Generative AI
Yuval Shukroon (Google)
Google Pinpoint on tutkivien toimittajien työkalu suurten dokumenttimäärien analysointiin. Sessiossa Googlen tiimi kertoi, miten he ovat miettineet Pinpointia uudelleen generatiivisen tekoälyn aikakaudella ja miten tuotetta on suunniteltu käyttäjille, joiden tekninen osaaminen vaihtelee suuresti.
Schellmann ja Tuquero esittelivät menetelmiä, joilla toimittajat voivat rakentaa kestävämpää todentamisprosessia tekoälyn ja synteettisen sisällön aikakaudella.
What About the Lawsuits? Copyright Litigation, Bot Scrapers, and the Future of the Open Web
Monika Bauerlein (Center for Investigative Reporting), Kevin Bankston (CDT), Meredith Rose (Public Knowledge)
Muutamat kustantajat ovat nostaneet kanteita tekoäly-yhtiöitä vastaan. Sessio purki, mitä oikeudenkäynneissä on tähän mennessä tapahtunut, mitkä kysymykset ovat avoimia ja miten lopputulos voi vaikuttaa siihen, mitä toimituksissa on sallittua tehdä tekoälyn kanssa.
AI Crawlers and the New Publisher Reality: Lessons From the Newspack Network
Joe Boydston (Newspack), Tracy Becker (Automattic)
Newspack-verkoston keräämä data paljasti, miltä käytännössä näyttää AI-ajan tuoma liikenne uutismedioihin: mitkä bottityypit liikkuvat, milloin ja kuinka paljon. Tieto auttaa kustantajia päättämään, miten reagoida.
Move Fast Without Breaking Trust: Challenges in AI Governance for the Future of News
Paine kokeilla tekoälyä luo jännitettä uutisorganisaatioissa. Sessio purki tätä jännitettä käytännöllisesti: miten rakennetaan prosessit, joissa voidaan liikkua nopeasti menettämättä journalistista luottamusta.
AI Without Losing the Human Touch: Sustaining Mental Muscle in AI-Assisted Journalism
Vania André (The Haitian Times)
Sessio otti esille kysymyksen, jota muut lähestyivät varovaisemmin: mitä tapahtuu kognitiivisille taidoille, kun tekoäly ottaa yhä enemmän perustehtäviä hoitaakseen? André esitteli menetelmiä sille, miten toimitukset voivat säilyttää ihmisen kriittisen ajattelun myös silloin, kun apuvälineitä on käytettävissä enemmän kuin koskaan.
Do We Really Need an AI Use Policy?
Alex Mahadevan (Poynter), Emma Cosgrove (Business Insider)
Poynterin Alex Mahadevan ja Business Insiderin Emma Cosgrove esittelivät skenaarioita, joissa käytäntöjen puuttuminen on johtanut ongelmiin, ja skenaarioita, joissa liian jäykät säännöt ovat estäneet hyödyllisten kokeilujen tekemisen.
Evaluating A.I. in the Newsroom: From Patterns to Benchmarks
Nikita Roy (Newsroom Robots Lab), Duy Nguyen (The New York Times), Teresa Mondría Terol (NPR)
Newsroom Robots Lab, NYT ja NPR esittelivät mittareita, joilla voidaan vertailla eri mallien suorituskykyä toimituksellisissa tehtävissä.
How Law Firms Manage Document-Heavy Investigations, and How Journalists Can Use These Tools
Chris Miles & Aaron Patton (Everlaw)
Tutkivat toimittajat ja asianajajat tekevät samantyyppistä työtä: suuria dokumenttimääriä, tutkimista, seuraamista. Everlaw on lakifirmoille rakennettu dokumenttien tutkimisalusta, ja sessio esitteli miten sen metodeja voidaan tuoda journalistien käyttöön.
TEEMA 7: Yleisöt, sisältö, personointijaliiketoiminta
The Survey That Asks ”One More Thing” (on Purpose)
Patrick Boehler & Madison Karas (Gazzetta)
Perinteiset kyselyt kysyvät ennalta määriteltyjä kysymyksiä. Adaptiiviset kyselyt tekevät jotain muuta: AI seuraa vastausta ja kysyy yhden lisäkysymyksen, joka on relevantti juuri sen ihmisen vastaukselle. Gazzetta on rakentanut tällaisen järjestelmän, ja sessio esitteli miten pienten vakiokysymysten ja AI-ohjatun jatkokyselyn yhdistelmä tuottaa rikkaamman kuvan yleisöstä kuin perinteinen lomake.
Using AI to Customize Content & Connect Readers
Ava Motes (Center for Media Engagement, University of Texas at Austin)
Miten AI voi auttaa toimituksia edistämään terveempää puoluerajat ylittävää vuoropuhelua, rauhoittamaan räyhääviä kommenttiosioita ja tavoittamaan paremmin monimuotoiset yleisöt? UT Austinin Media Engagement Center esitteli tutkimuspohjaisia käytännöllisiä menetelmiä.
From AI Journaling to the Mind Economy: Rethinking How Journalism Understands Human Narratives
Dexiang ”Darren” Gao (HEAUT Foundation)
HEAUT on AI-päiväkirjaalusta, joka muuttaa henkilökohtaisen kirjoittamisen strukturoiduksi tiedoksi. Sessio esitteli ”Mind Economy” -konseptin: henkilökohtaisista narratiiveista tulee tietopääomaa, jota voidaan käyttää journalismin lähdeaineistona.
AI as a Power Assist for Political Accountability Reporting
Chandran Sankaran (Gigafact), Emily Le Coz (Suncoast Searchlight), Kevin Grant (Allbritton Journalism Institute)
Poliitikkojen lausunnot ovat hajallaan ympäri nettiä: Gigafact on rakentanut alustan, joka kokoaa nämä, analysoi ne ja auttaa toimittajia.
Build the News Industry’s AI Business Plan
Richard Lui (MS NOW / CAREGenome), Andy Pergam (Knight Center, ASU)
Sessio haastoi osallistujia rakentamaan käytännöllistä liiketoimintasuunnitelmaa sille, miten uusmedia voi hyödyntää asemaansa sen sijaan, että odottaa yhtiöiden tekevän sen heidän puolestaan.
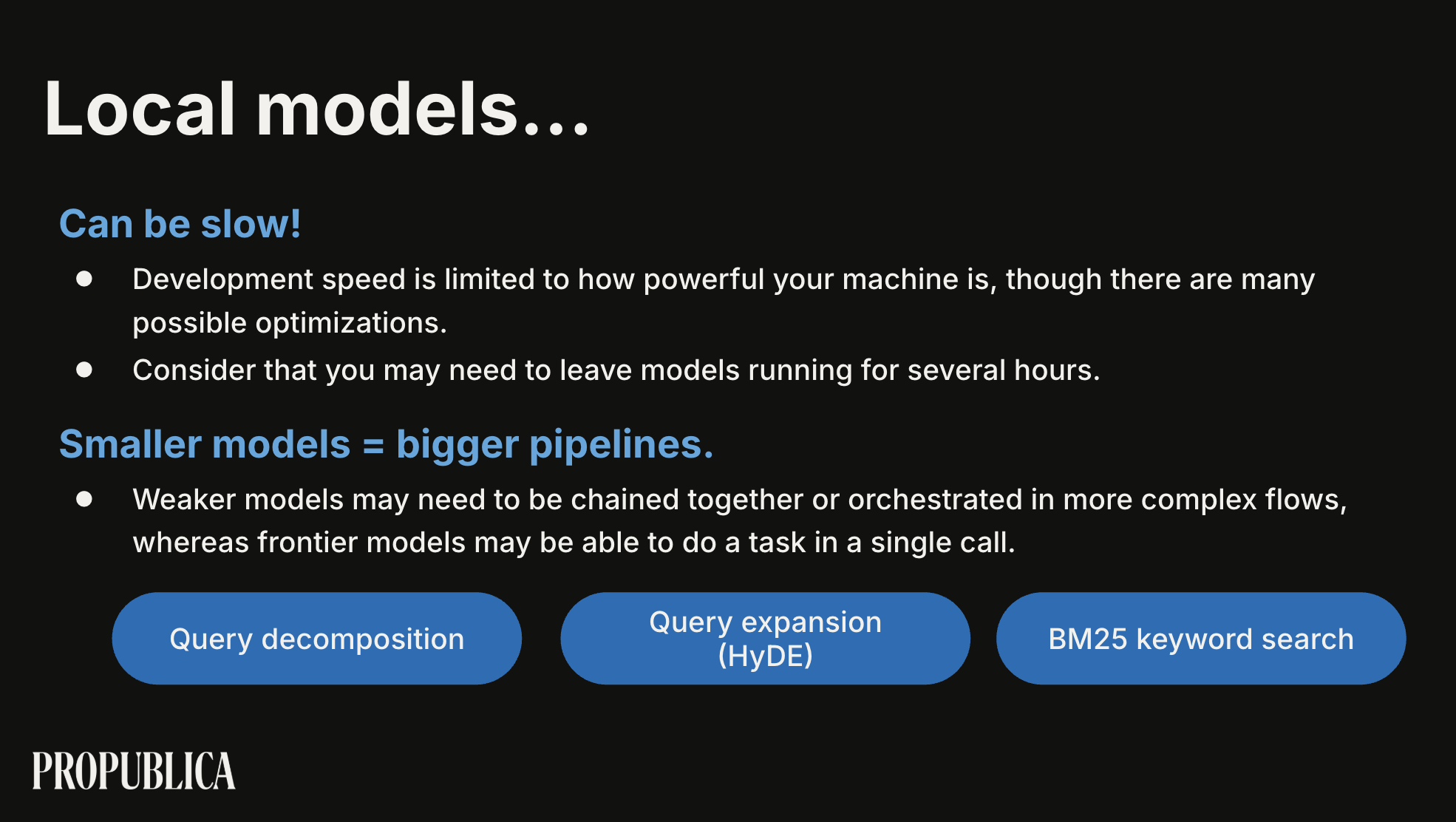
What’s Possible With Local Models? Building Secure AI Pipelines for Investigative Journalism
Ben Werdmuller & Dana Chiueh (ProPublica)
Paikallisesti pyörivät AI-mallit ratkaisevat yksityisyysongelman, mutta luovat uusia: mitkä mallit toimivat, mihin ne soveltuvat, mitä taitoja tarvitaan? ProPublican tiimi esitteli, miten he ovat rakentaneet turvallisia AI-putkistoja tutkivaan journalismiin paikallisilla malleilla.
Getting the Very, Very Best Out of Archival Audio
Mark Chonofsky (Chicago Public Media)
Chonofsky kertoi, miten he ovat litteroineet WBEZ:n koko äänarkiston tekoälyavusteisesti ja mitä teknisiä haasteita se vaati: äänen valmistelu, puhujien tunnistaminen, erikoistermit, vaihtelevat tallennusolosuhteet.
From Fear to Fluency: Building an AI-Ready Newsroom Culture
Peder Hammerskov (Center for AI at DMJX)
Hammerskov esitteli työtä, jota tanskalaisten uutistoimitusten kanssa on tehty AI-kulttuurin rakentamisessa.
Tunnelma: synkistelystä ei tietoakaan
Loppuun omia mietteitäni. Poikkeuksellisen Hacks and Hackers -tapahtumasta teki tunnelma. Synkistelyä ei ollut lainkaan. Huolipuheen puuttumisen panivat merkille myös tapahtuman järjestäjät loppupuheenvuorossaan: alan murros voidaan nähdä myös mahdollisuutena. Jotain kuvastanee myös tämä AI-kurssikaverini, uutistoimisto AP:n Head of Productin Bryan Davisin ilme=)
Vakavammin ottaen, kaksi havaintoa jäi erityisesti mieleen. Torstaiaamun ryhmäharjoituksessa asetuimme kaikki noin kolmesataa ihmistä isoon rinkiin, ja moni kertoi pyydettäessä avoimista tehtävistä organisaatioissaan. Käden sai nostaa pystyyn, jos koki että pystyy auttamaan joko itse tai vinkkaamaan sopivan rekryn. Virkistävää.
Toinen mieleen jäänyt ajatus on se, että eurooppalaista ja etenkin pohjoismaista tekoälytekemistä arvostetaan täälläkin laajalti. Mutta se täytyy tämän tapahtuman perusteella sanoa, että amerikkalaiset kirivät kovaa, etenkin uutishankinnan automatisoinnin saralla.
Järjestäjät alleviivasivat halunneensa pitää tapahtuman startup-henkisenä, mikä toteutuikin. Asian kääntöpuoli on se, että ensi vuonna tapahtumaan tuskin on saatavilla kovin paljon enemmän lippuja: kun juttelin pääjärjestäjän kanssa, hän totesi, että ei halua kasvattaa tapahtumaa kovin paljon isommaksi, koska tietynlainen ”kotikutoisuus” kärsisi.
PS. Tapahtumalla oli käytössä MCP-yhteys tapahtumaohjelmaan ja jaettuihin muistiinpanoihin, mikä helpotti kovasti omienkin muistiinpanojen täydentämistä Claude Coden avustuksella. Tapahtuman hengessä tallensin kaikki omat muikkarini omaan Obsidian-holviini, joka on koneluettavaan md-tiedostomuotoon materiaaleja pakkaava ilmainen muistiinpano-ohjelma.Näin niiden hyödyntäminen aina jatkossa kaikissa Claude-keskusteluissani on helpompaa.
Ei kannata säikähtää! Tämä on helpompaa kuin luulet.
Olet ehkä huomannut, että erilaisten uutiskoosteiden pyytäminen tekoälypalveluilta suoraan ei aina johda laadullisesti kummoisiin lopputuloksiin (vaikka esimerkiksi ChatGPT:n agenttitila & ajastus -kombo on tässä parhaimmillaan hyödyllinen). Lopputulos tuppaa horjumaan etenkin silloin, jos halutaan seurata juuri tiettyjä lähteitä juuri tietyin väliajoin juuri tietyllä tavalla.
Automaatioiden rakentamiseen on monenlaisia varta vasten suunniteltuja työkaluja, kuten Zapier, N8N tai Power Automate, mutta aina sellaisia ei tarvita, eikä välttämättä generatiivista tekoälyäkään.
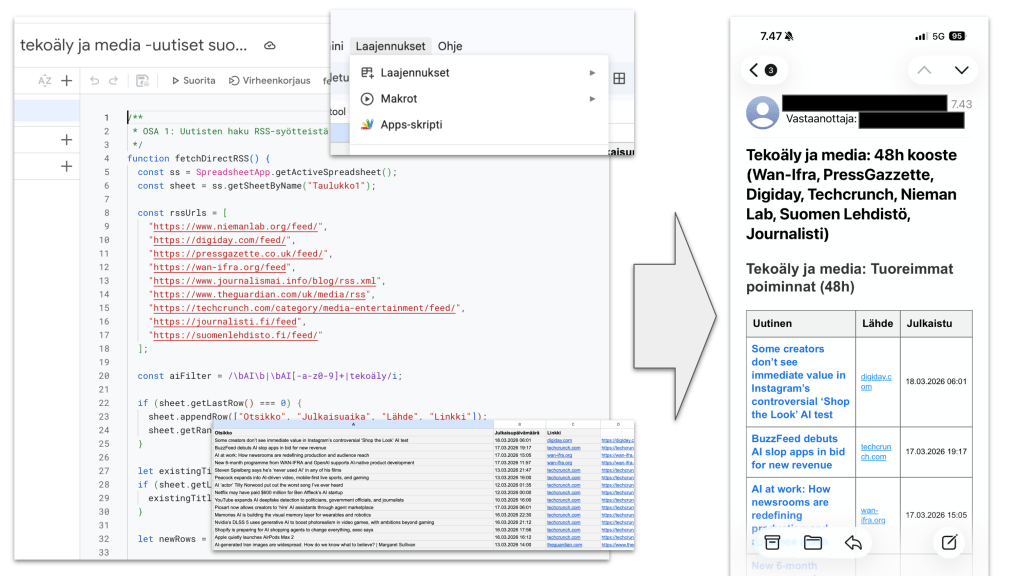
Esittelen tässä kirjoituksessa yhden yksinkertaisen tavan luoda itselleen uutisseurannan automaatio Googlen työskentely-ympäristössä.
Se hyödyntää Google Sheets -taulukkolaskentaohjelmaa sekä Google Apps Scriptiä. Apps Script on pilvipohjainen JavaScript-alusta (JavaScript on ohjelmointikieli), jolla voi automatisoida tehtäviä, luoda omia työkaluja ja yhdistää Googlen eri palveluita toisiinsa. Se on ilmainen eli kuuluu tavalliseen Google-tiliin ja etuna on, että siinä kirjoitetaan ja ajetaan koodia suoraan selaimessa. JavaScript-koodia sinun ei tarvitse osata riviäkään, vaan voit pyytää sellaista tekoälyltä (kannattaa kuitenkin pyrkiä varmistamaan tekoälyn kanssa keskustellessa, että toimit fiksusti ja tietoturvallisesti. Varmista kaverilta, jos pohdituttaa).
Oma esimerkkityönkulkuni koostuu kiteytettynä seuraavista vaiheista:
Lähteet: Valitaan seurattavat sivustot, jotka tarjoavat jatkuvaa uutisvirtaa koneellisesti luettavassa muodossa (omaan työnkulkuuni hain uutisia yhdeksän eri median RSS-syötteistä).
Suodatus: Luodaan säännöt, joilla ei-haluttu sisältö karsitaan pois. (omaan työnkulkuni koodiin lisättiin hakuehto, joka poimii vain ne otsikot, joissa esiintyi sana tekoäly jossain muodossa).
Tallennus: Tallennetaan haetut uutiset paikkaan, jossa ne säilyvät (omassa työnkulussaniuutiset tallennetaan taulukkoon, ja lisäksi koodi varmistaa otsikon perusteella, ettei samaa juttua lisätä listalle kahdesti).
Ajastus: Asetetaan järjestelmä toimimaan itsenäisesti tiettyinä aikoina (omassa työnkulussani uutisia haetaan taulukkoon kuuden tunnin välein).
Lähetys: Toimitetaan valmis tieto halutussa muodossa haluttuun paikkaan (omassa työnkulussani saan sähköpostiini joka aamu klo 7–8 välillä viimeisen 48 aikana kertyneet uutiset. Vaihdan tämän todennäköisesti pian toimimaan joka toinen päivä, siksi 48 tunnin aikaväli tässä vaiheessa, vaikka maili tulee päivittäin).
Tämä työnkulku on vielä perinteistä automaatiota, joka toimii antamillasi ohjeilla. Tekoälyä (Geminiä) käytetään tässä välillisesti koodin kirjoittamiseen.
Tärkeä huomio Apps Scriptistä: Kun tallennat skriptiä tai annat sille käyttöoikeuksia, Google saattaa näyttää varoituksen ”varmistamattomasta sovelluksesta”. Tästä ei kannata hätääntyä. Kyseessä on Googlen normaali turvatoimi itse luoduille työkaluille. Kun teet työkalun itse, se on turvallista, mutta voit aina varmistaa asiantuntijalta, jos jokin mietityttää.
Jos haluaisit viedä homman pidemmälle: Voit lisätä skriptiin Geminin API-avaimen (henkilökohtainen tunniste, jota on säilytettävä tietoturvallisesti eli älä jaa sitä muille). Silloin kielimalli voisi esimerkiksi analysoida taulukon uutiset puolestasi ja tiivistää ne ennen sähköpostin lähetystä.
Tämä journalistista vibekoodauskerhoa mainostava kuva on otettu helmikuussa City University of New Yorkin Craig Newmark Graduate School of Journalismin tiloissa.
Vibekoodaus tai fiiliskoodaus tarkoittaa ohjelmointia ilman syvää teknistä ymmärrystä – mennään ”fiiliksen mukaan” siten, että esimerkiksi sovellusta rakennetaan kuvailemalla haluttuja toimintoja luonnollisella kielellä. Kyse ei kuitenkaan ole vain teknisestä ilmiöstä, vaan voidaan ajatella, että esimerkiksi uutismedioissa se avaa mahdollisuuksia laajempaan työtapojen ja työkulttuurin muutokseen. Koetan tässä kirjoituksessa avata, miten.
Tapoja fiiliskoodaukseen on monia, niin kuin on palveluitakin. Tunnetuimmasta päästä suuren yleisön silmissä lienee ruotsalainen kasvuraketti Lovable. Sillä voit halutessasi pyöräyttää vaikkapa arkipyhävapaalaskurin ja jakaa sen kaverille:
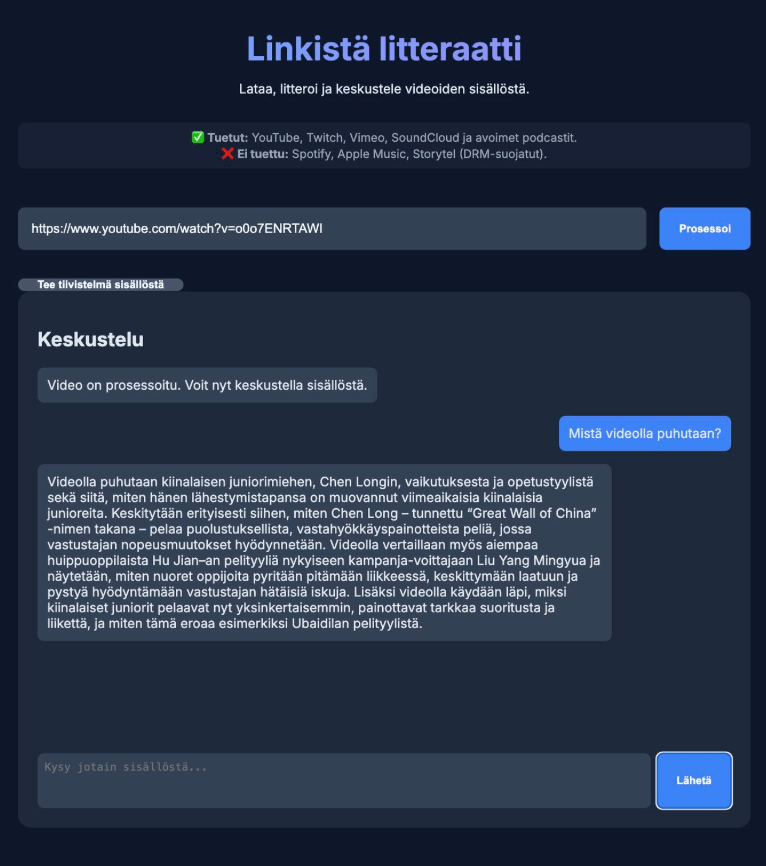
Luonnollisella kielellä tähän tapaan toimivia työkaluja ovat myös esimerkiksi ChatGPT Codex, Cursor, Claude Code tai Replit. Itse käytän eniten Codexia sekä Googlen Antigravityä, jolle annetaan hallitusti pääsy koneesi tiedostoihin, jolloin ohjelmia voi rakentaa helposti myös lokaalisti eli omalle koneelle sen sijaan että ne sijaitsevat pilvessä kuten Lovablen tapauksessa. Lokaaliuden etuna on esimerkiksi se, että omalle koneelle ladatun avoimen lähdekoodin kielimallin käyttö ei maksa mitään. Tällä logiikalla voi rakentaa vaikkapa Youtube-videoiden litteroijan, joka toimii näin:
Syötä linkki esim. Youtube-videoon tai podcastiin.
Sisältö latautuu omalle koneelle automaattisesti yleensä audiona.
Ääni muuttuu transkriptioksi ja latautuu txt-tiedostona omaan kansioonsa.
Kielimalli antaa käyttäjän kysymyksiin vastauksia transkription pohjalta.
Runko on tehty Python-ohjelmointikielellä, lataus hoituu yt-dlp:llä (avoimen lähdekoodin komentorivityökalu), litterointi OpenAI:n puheentunnistusmalli Whisperillä ja kielimallin käyttö avoimen lähdekoodin ohjelmiston Ollaman kautta. Käyttöliittymä on selaimessa.
Tämä sanottua, on hyvä tiedostaa, että tällaisissa on aina vaarana ns. demoefekti: wau, vaikuttaapa näppärältä, tuotannollistetaan tämä. Siinä on sitten kuitenkin aina edessä mm. panos–tuotos-arvio. Joka sisältää esimerkiksi sen, paljonko työkalun käyttö ja ylläpito maksaisi ihan oikeasti. Tässä piileekin ”vibekoodaussuuntauksen” suurin pullonkaula organisaatioissa: syntyy valtava määrä ideoita ja prototyyppejä – joista osa varmasti erittäin hyviä – joiden putki tuotantoon on kuitenkin joko erittäin hidas tai kokonaan tukossa. Yksi oppi tässä on minusta se, että varo hurmaantumasta liian hienoista demoesityksistä. Demo on ihan eri asia kuin tuotantoon viety versio.
Omalta osaltani haluan korostaa, että en osaa koodata, enkä ole koskaan pitänyt itseäni erityisen teknisenä ihmisenä. Jos minäkin pystyn tähän, pystyt sinäkin! Siinä sivussa opit koodista itse asiassa aika paljon, vaikka et koodaamaan varsinaisesti opikaan.
Jos aloitat aivan nollasta, suosittelen menemään osoitteeseen lovable.dev, kirjautumaan sinne Googlen tunnuksilla (pari klikkausta), jolloin käytössäsi on pieni määrä krediittejä, joilla voit kokeilla tehdä asioita ilmaiseksi.
Mahdollisuudet: nopeus, ketteryys ja uudenlaiset tavat tehdä töitä
Vibekoodaus madaltaa siis kynnystä rakentaa omia työkaluja. Kun idean ja prototyypin väliin ei tarvita raskasta kehitysprosessia, toimittaja voi esimerkiksi:
Tehdä datan puhdistus- ja analyysityökaluja omaan käyttöönsä
Kun kaikki ei ole enää riippuvaista keskitetystä kehitystiimistä tai keskitetystä budjetista, se voi tehdä toimituksesta ketterämmän.
Uhat: demoefekti, tekninen velka ja hallitsematon työkaluräjähdys
Demoefekti on mielestäni suurimpia uhkia, kuten aiemmin jo lyhyesti kuvasin. Prototyyppi näyttää toimivalta, mutta:
Kuka ylläpitää sitä?
Kuka vastaa tietoturvasta?
Mitä tapahtuu, kun API-hinnat (API = rajapinta) muuttuvat?
Entä jos palvelu katoaa?
Toimituksissa voi syntyä kymmeniä pieniä työkaluja, joilla ei ole omistajaa eli tahoa, joka oikeasti katsoisi työkalun perään. Tämä on omiaan synnyttämään teknistä velkaa.
Koska vibekoodaus tuntuu “ilmaiselta”, kustannuksia ei aina nähdä: kun volyymi kasvaa, kasvavat myös kulut. Jos toimitus rakentaa työkaluja vibekoodaamalla, pullonkauloiksi voivat myös muodostua ainakin seuraavat asiat:
Ymmärtääkö tekijä, miten malli tekee päätelmiä?
Miten varmistetaan datan käsittelyn eettisyys?
Dokumentoidaanko työkalun toimintalogiikka?
Erityisen herkkä kysymys on lähdesuoja. Jos toimittaja syöttää arkaluonteista materiaalia pilvipalveluun, se on erityisen iso riski.
Minne data tallentuu?
Käytetäänkö sitä mallien koulutukseen?
Täyttääkö ratkaisu organisaation tietoturvavaatimukset?
Lokaalit eli omalla koneella toimivat ratkaisut voivat olla turvallisempia, mutta nekin vaativat ymmärrystä riskeistä.
Parhaimmillaan vibekoodaus voi siis demokratisoida kehittämistä, nopeuttaa innovointia ja tehdä ainakin osasta toimittajia nykyistä enemmän palveluiden rakentajia. Toisaalta vibekoodaus voi johtaa hallitsemattomaan työkalujen sillisalaattiin, josta ei ole kokonaiskäsitystä kenelläkään. Tämän myötä vastuut hämärtyvät ja voi myös syntyä kitkaa sisältöpuolen ja kehityspuolen välille. Yksi ydinkysymys on, mikä on se prosessi, jolla parhaat ideat suppiloidaan tuotantoon. Jos tämä ei toimi, syntyy helposti tyytymättömyyttä.
Haluaisin itse ajatella jotenkin niin, että ajatuksena ei todellakaan ole, että kaikista tulee koodareita, vaan siitä, että jonkintasoisesta ohjelmoinnista tulee yksi uusi taito kirjoittamisen rinnalle. Yksi konkreettinen käyttötapa on ihan vain sekin, että teet ajattelemastasi konseptista prototyypin, jonka näytät sitten haluamillesi sidosryhmille. Näin nämä saavat hyvän käsityksen siitä, mitä ajat takaa.
Lähteitä, joita olen hyödyntänyt tässä kirjoituksessa:
Aloitin viime vuonna blogisarjan, jossa summaan tasaisin väliajoin isoja kehityskulkuja niitä taustoittavine lähteineen blogikirjoituksiksi. Viime kesän 12 nostoa löytyvät täältä ja loppuvuoden 14 havaintoa täältä. Tähän kirjoitukseen olen koonnut toimintaympäristöhavaintoja tammi-helmikuulta 2026. Painotus on uutismediassa ja tekoälyssä.
Iso kuva – viisi kysymystä
Alkuvuonna julkaistut tutkimukset, analyysit, uutiset ja muut signaalit media-alalta kertovat, että isot kysymykset pyörivät ainakin näiden viiden teeman ympärillä (selvyyden vuoksi: tulkinta on omani, ei tekoälyn):
Millaiseksi ihmisen ja koneen työnjaon pitäisi oikeastaan muodostua? Onko tekoäly “vain työkalu muiden joukossa” vai onko tämä aikansa elänyt väite, eli onko tästä työnjaosta tulossa jotain muuta?
Miten ihmisten journalistista perusosaamista – hoksaamisesta haastattelutaitoihin – vahvistetaan tekoälyn aikakaudella käytännössä? Mitä muuta se tarkoittaa kuin lisäkoulutusta?
Miten erottuvuutta mietitään medioissa ihan konkreettisesti? Tässä on syytä erottaa toisistaan ainakin sisältöjen kerronta itsessään sekä niin sanottu koneluettava tai rakenteistettu data.
Miten pidetään huolta siitä, että ihmisillä olisi paitsi aikaa myös kykyä kriittiseen ajatteluun tilanteessa, jossa ympärillä on käynnissä valtava muutos?
Tuleeko kokemus tekoälystä jakautumaan jatkossakin epätasaisesti, sekä yleisesti että myös työpaikoilla? Joidenkin mielestä tekoälykehitys on jo nyt AGI-vaiheessa, jossa tekoäly kykenee ymmärtämään, oppimaan ja suorittamaan mitä tahansa älyllistä tehtävää ihmisen tasoisesti tai paremmin. Toiset taas ihmettelevät, kun tekoälyt horisevat yhä vain joutavanpäiväisiä. On epäolennainen kysymys, voivatko molemmat olla totta samaan aikaan. Tärkeää on, pysyykö ihmisten kokemusten epäsuhta aina tällaisena ja mitä asialle on tehtävissä.
Jos nämä kaikki vedetään yhteen, huomataan ainakin se, että ihmisen rooli on jokaisessa kohdassa vielä auki. Tekoäly pakottaa määrittelemään uudelleen, mitä ihminen tekee, missä kohtaa arvoketjua ja miksi.
Edellä mainittuihin viiteen teemaan liittyviä lukuvinkkejä tammi-helmikuulta 2026:
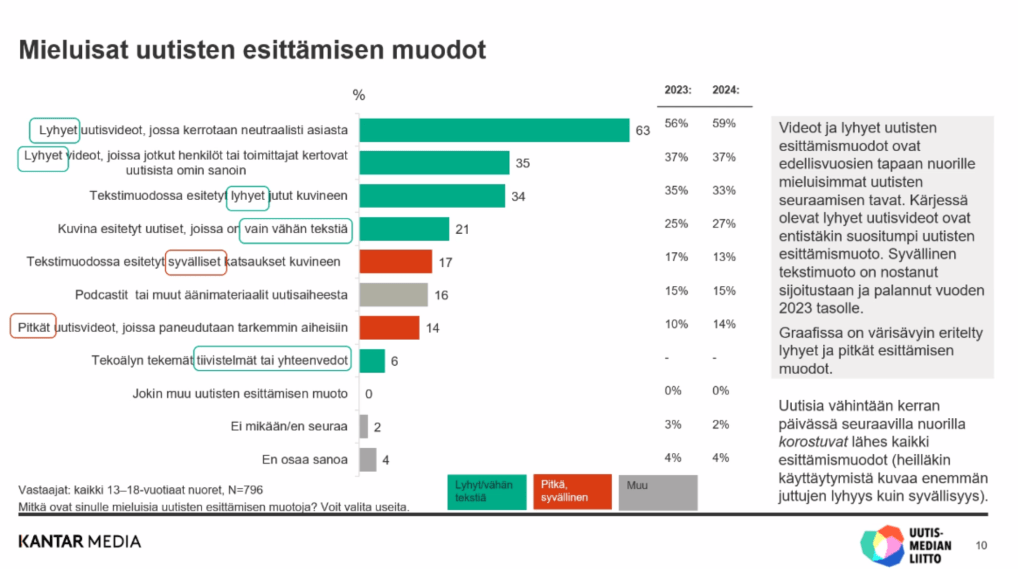
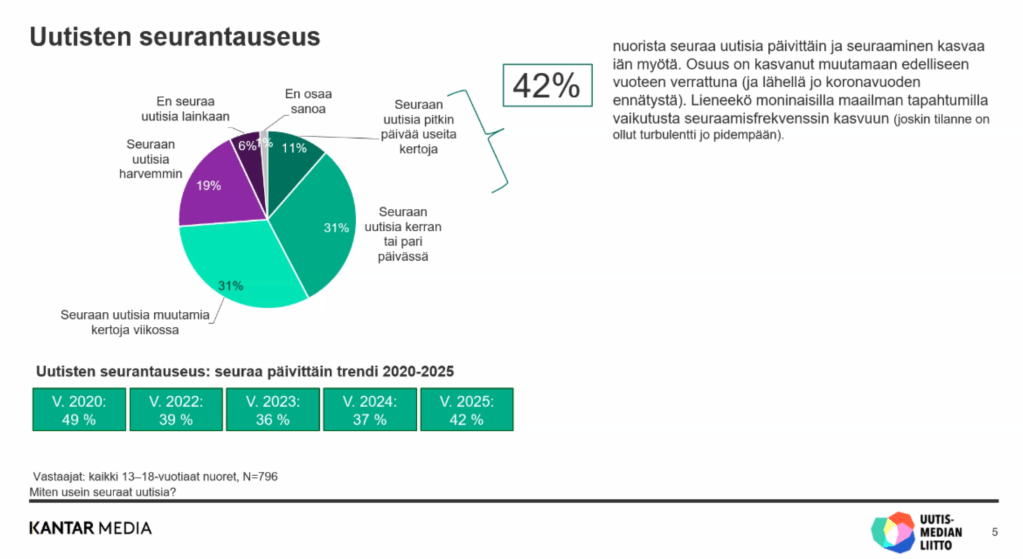
Uutismedian liiton vuotuinen kyselytutkimus 13–18-vuotiaille suomalaisille (n=796) kertoo, että videot ja lyhyet uutisten esittämismuodot (’lyhyt/vähän tekstiä’) ovat edellisvuosien tapaan mieluisimmat uutisten seuraamisen tavat. Tutkimuksesta selviää myös, että aiempaa useampi nuori seuraa aktiivisesti uutisia – mutta samalla uutisten välttely on lisääntynyt.
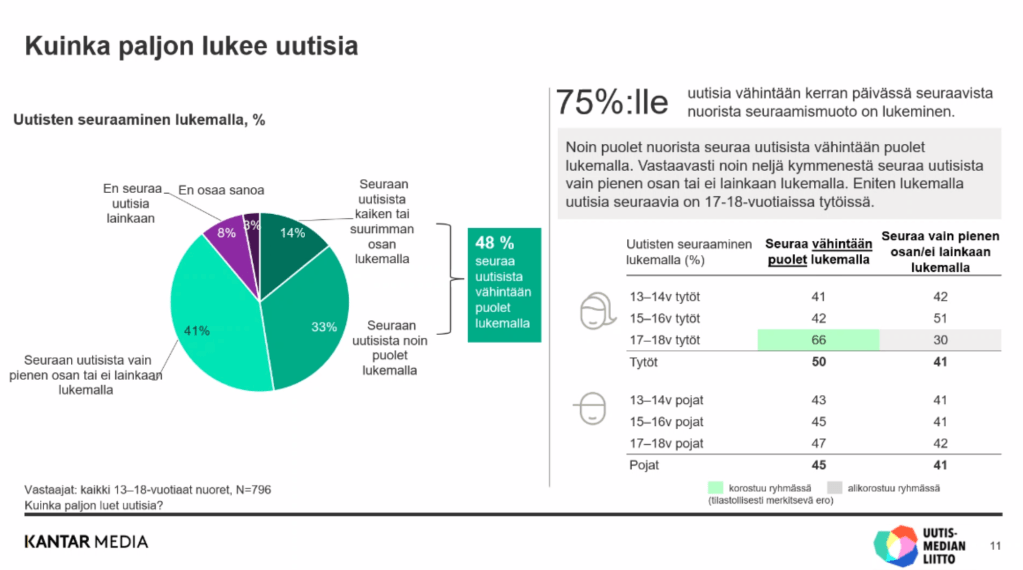
Tutkimuksen kiinnostavinta antia on kuitenkin uusi osuus, jossa selvitettiin kuinka paljon nuoret lukevat uutisia. Noin puolet nuorista (48%) kertoo seuraavansa seuraamistaan uutisista vähintään puolet lukemalla (se mistä ja miten lukee, jää vastaajan tulkinnan varaan – oheisissa kuvissa on kuitenkin täsmällisiä muotoiluja, joilla asiaa on kysytty). Tätä voi mielestäni pitää suhteellisen suurena lukuna, kun ottaa huomioon, että kyse on 13–18-vuotiaista, jotka ovat jo aika pitkälti sosiaalisen videon algoritmien armoilla.
Eniten lukemalla uutisia seuraavia on 17–18-vuotiaissa tytöissä. Uutisten lukeminen kasvaa varhaisteinistä sitä mukaa kuin ikää tulee lisää kohti täysi-ikäisyyttä – mutta käytännössä vain tytöissä, ei juuri pojissa.
Muita keskeisiä havaintoja: tärkein uutislähde, tekoäly, uutisvälttely, kiinnostavimmat aiheet…
Tekoälyjen tekemät tiivistelmät eivät tässä tutkimuksessa nouse lähellekään mieluisimpia tapoja kuluttaa uutisia. Sekä niiden mieluisuus että käyttö on tutkimuksen mukaan marginaalista.
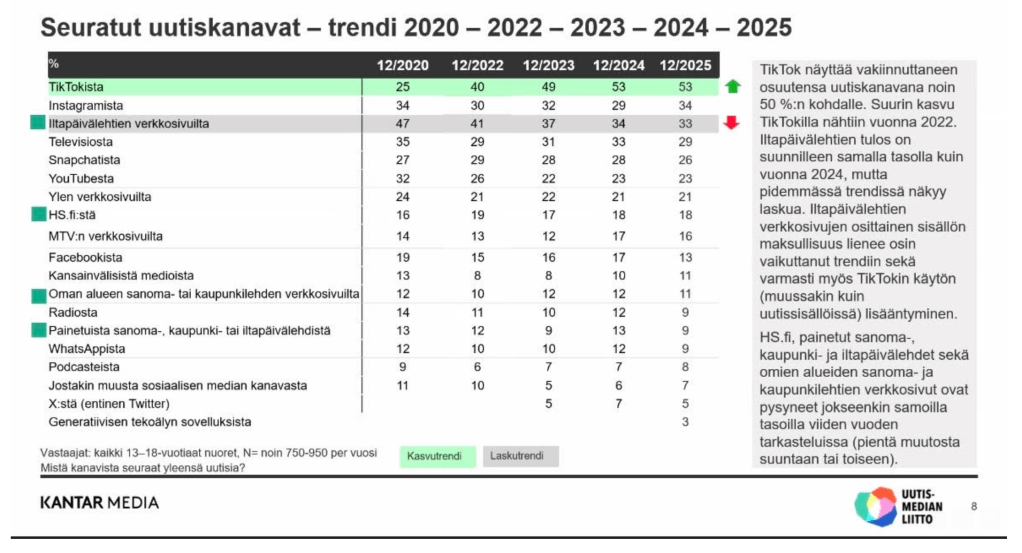
Ikäryhmän tärkein uutislähde on tänäkin vuonna Tiktok, mutta sen kasvu on pysähtynyt. Iltapäivälehdet ovat (kysytty tutkimuksessa könttänä) nyt kolmanneksi tärkein uutislähde. Instagram nousi niiden ohi hiuksenhienosti. Tutkimusraportissa arvellaan, että Tiktokin lisäksi iltapäivälehtien hienoiseen laskutrendiin vaikuttaa niiden muuttuminen osittain maksulliseksi.
Tutkimuksesta selviää myös, että ”joitakin uutisaiheita” välttelemien määrä ikäryhmässä on kasvanut vuodesta 2023 eteenpäin. Välteltävät uutiset liittyvät useimmiten sotaan, väkivaltaan ja negatiivisuuteen.
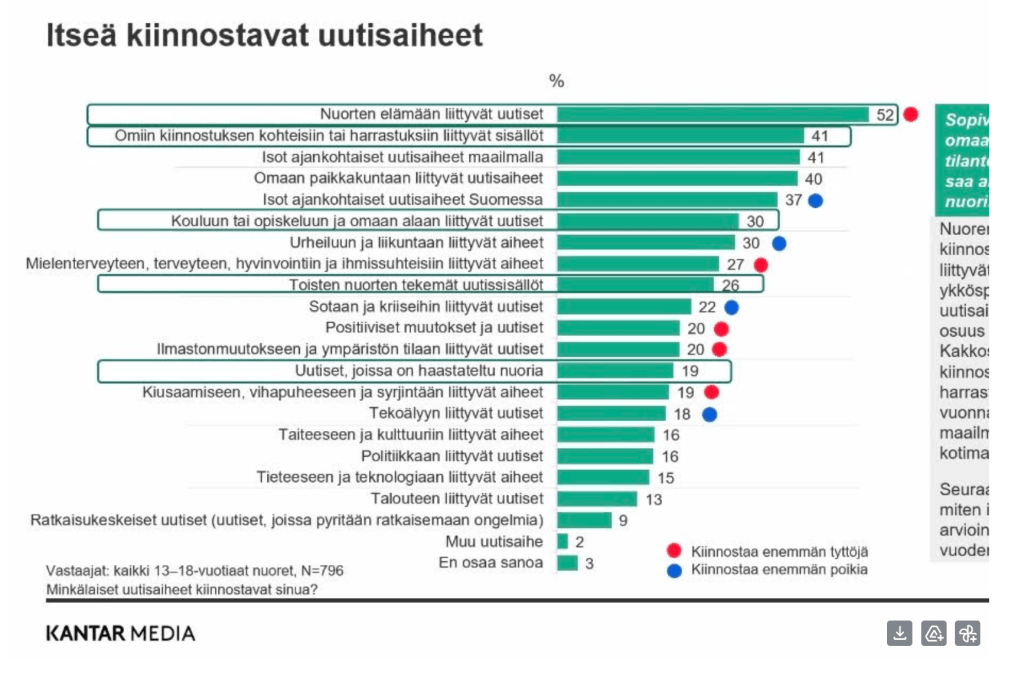
Tutkimuksessa kysyttiin myös uutisaiheista, jotka kiinnostavat eniten (oma kommenttini: tällaisen selvittäminen yksinomaan kysymällä on mielestäni hyvin haastavaa). Esimerkiksi mielenterveyteen, terveyteen, hyvinvointiin ja ihmissuhteisiin liittyvät aiheet kiinnostavat enemmän tyttöjä kuin poikia, kun taas vaikkapa tekoälyyn liittyvät aiheet kiinnostavat enemmän poikia kuin tyttöjä. Poikia kiinnostaa tyttöjä enemmän myös mm. isot ajankohtaiset uutisaiheet Suomessa sekä urheiluun ja liikuntaan liittyvät aiheet.
Tutkimuksen mukaan 13–18-vuotiaista nuorista uutisia ylipäänsä seuraa päivittäin 42 prosenttia. Osuus on kasvanut muutamaan edellisvuoteen verrattuna. Tutkimusraportissa arvellaan, että yksi syy on yksinkertaisesti se, että maailmalla tapahtuu paljon ja isoja asioita.
Tutkimus päivittyy Uutismedian liiton sivuille tämän päivän aikana.
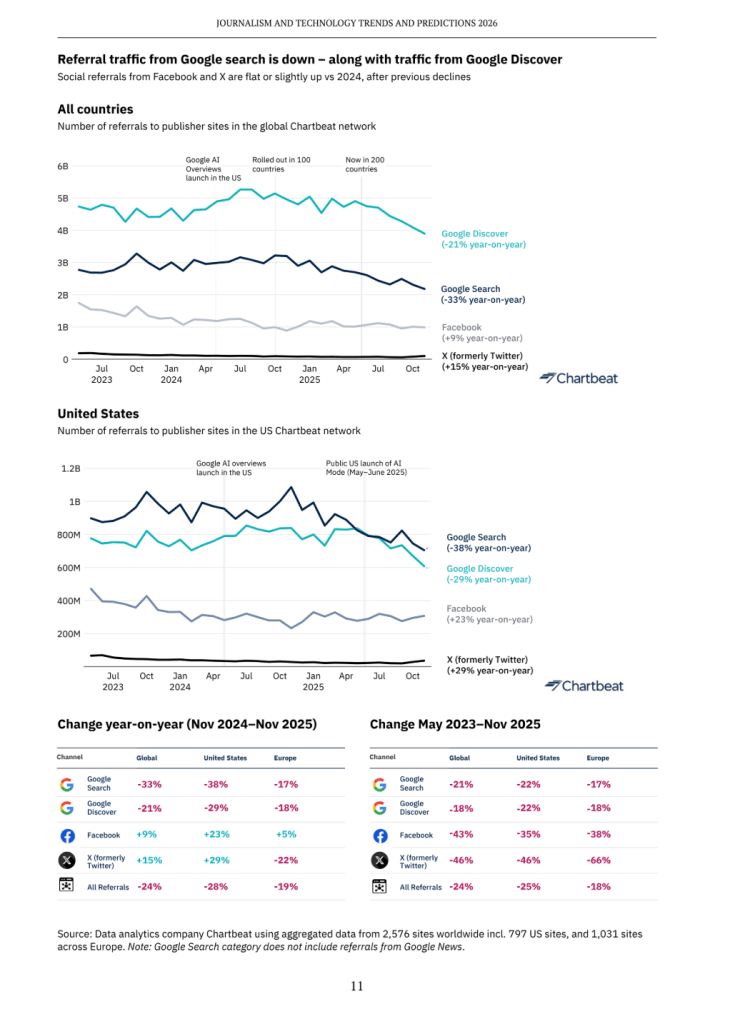
Oxfordin yliopiston Reuters-instituutin Journalism and Technology Trends and Predictions 2026 -raportti julkaistiin tänään. Raportti sisältää laajalti sekä dataa (esim. Chartbeatin pitkät trendit uutismedian Google Discover ja Google Search -liikenteen laskusta) että perinteisesti osumatarkan kyselytutkimuksen kolmellesadalle mediajohtajalle yli 50 maasta, myös Suomesta.
1. Googlen hakukone- ja Discover-liikenne uutismediaan laskussa, Facebook nousussa
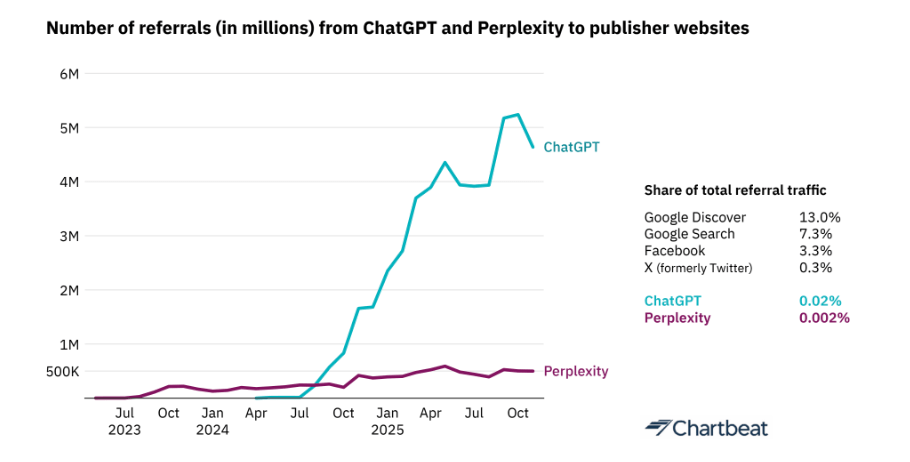
2. ChatGPT-liikenne kovassa kasvussa, mutta yhä marginaalista
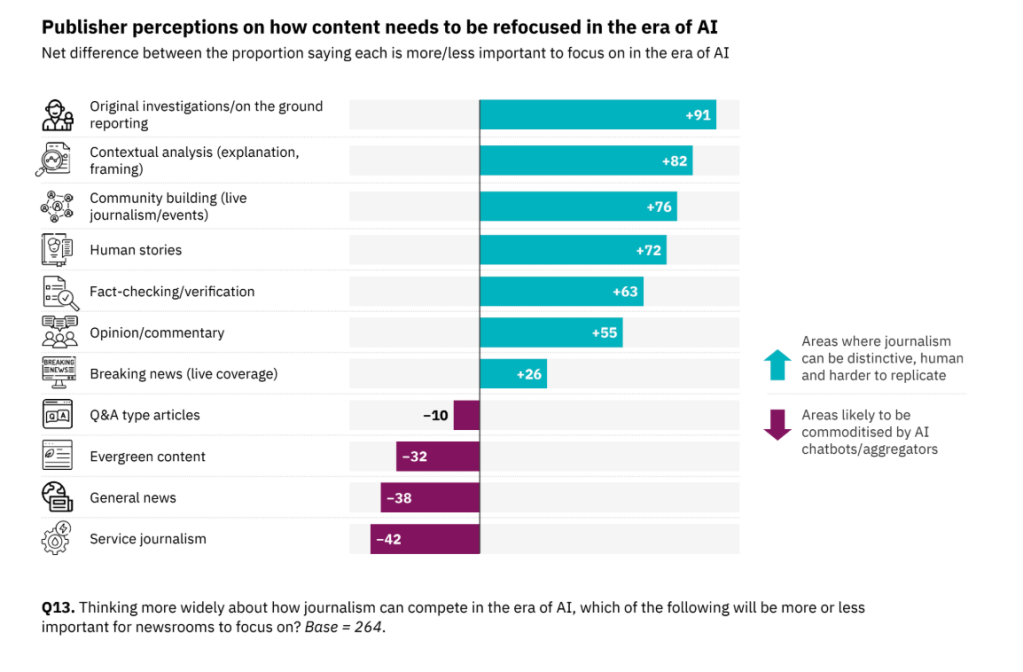
3. Näin ajattelevat mediapomot: tällaista sisältöä lisää AI-aikana, tällaista vähemmän
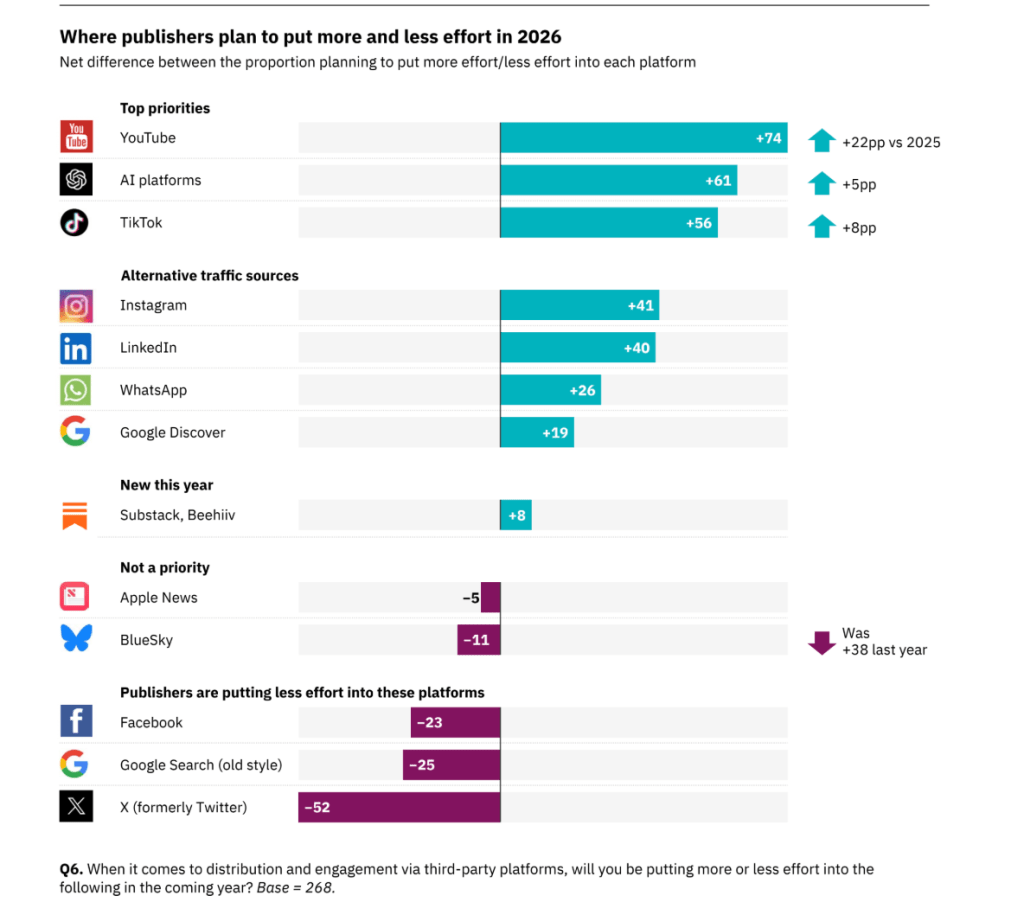
4. Näihin alustoihin uutismediat aikovat satsata enemmän, näihin vähemmän
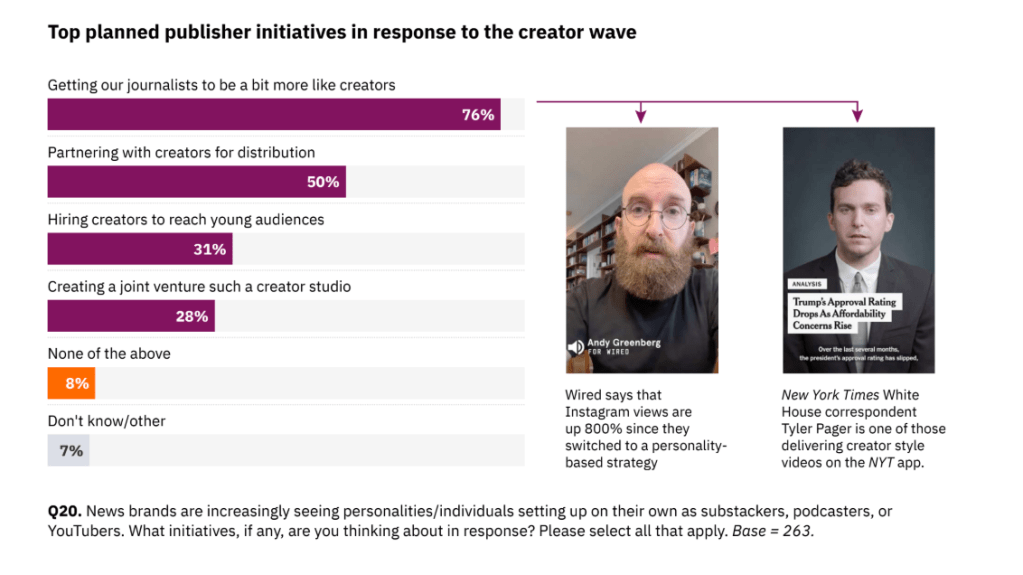
5. Vaikuttajien rooli pohdituttaa – näin uutismediat aikovat toimia
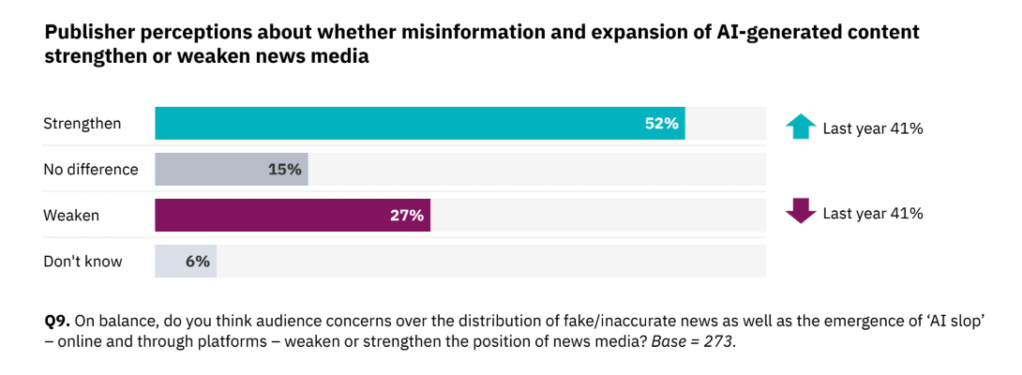
6. AI-tauhka vahvistaa journalismia – vaikka samalla heikentääkin
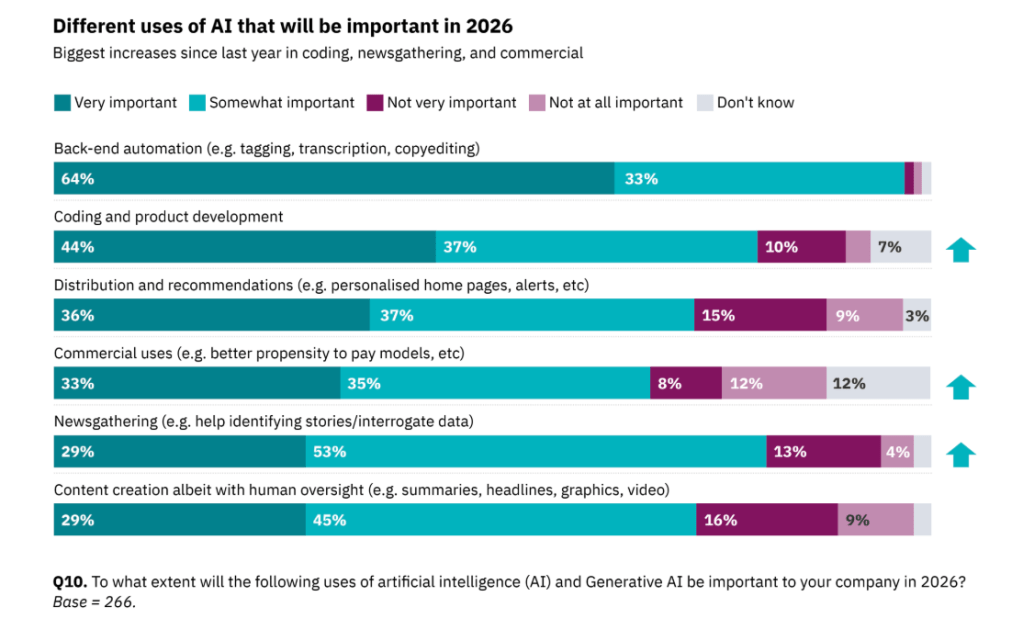
7. Nämä AI:n käyttökohteet ovat uutismedialle tärkeimpiä 2026
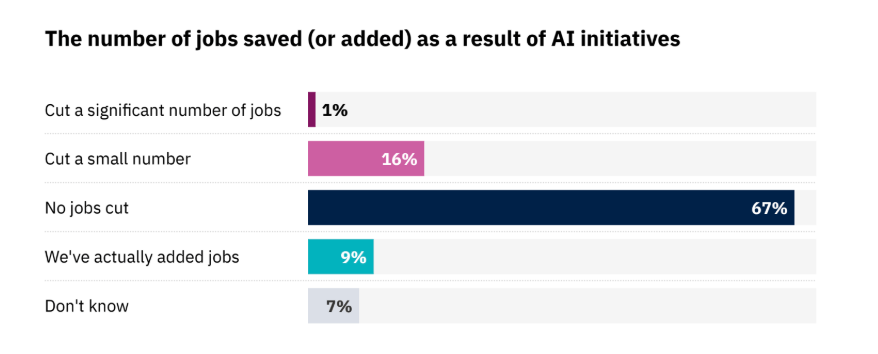
8. Uutismedian AI-hankkeet vähentäneet ihmistyövoimaa harvoin, osassa lisätty
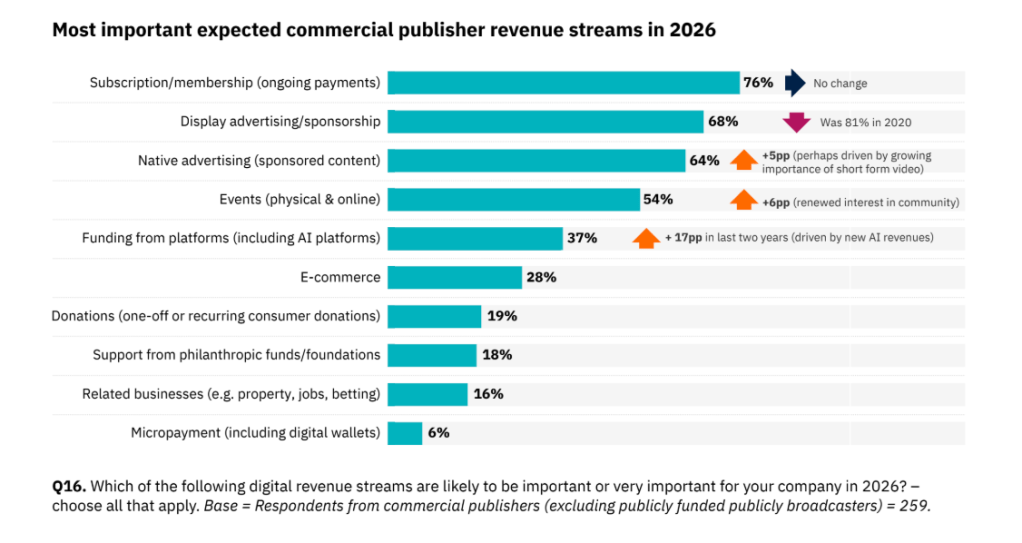
9. Ansaintamallien tärkeys 2026
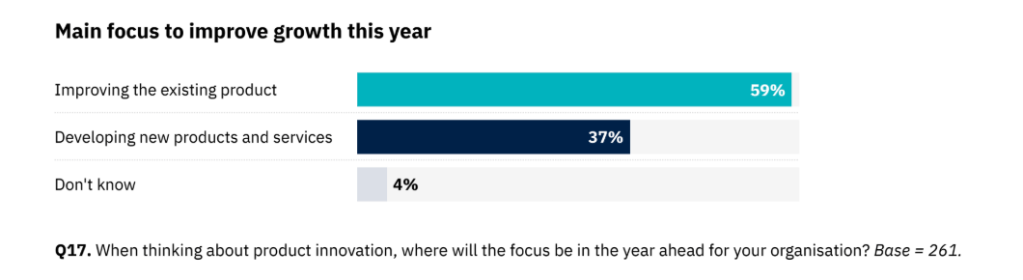
10. Kehityksen fokus uutismediassa: nykyiset tuotteet vs. uudet tuotteet
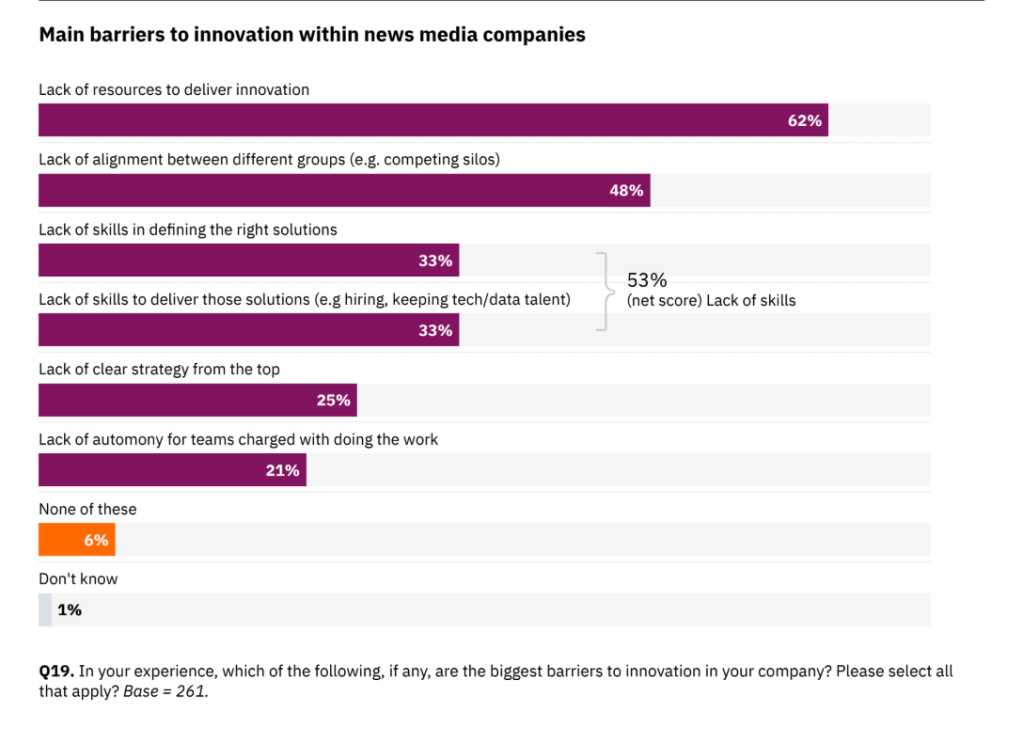
11. Kehityksen isoimmat esteet uutismediassa
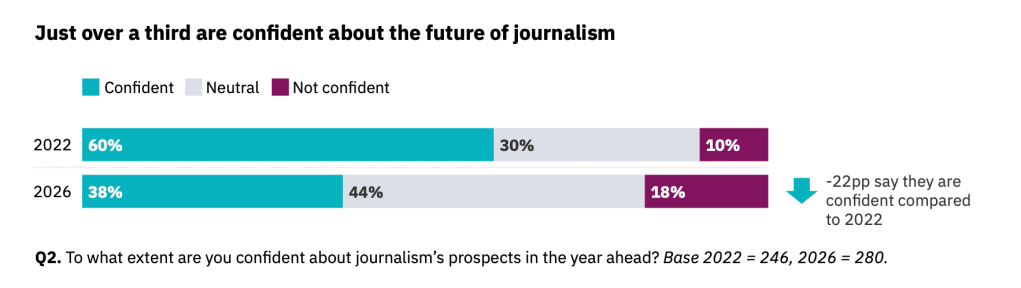
12. Mediapomot: Usko journalismin tulevaisuuteen on kovalla koetuksella tekoälyn aikakaudella – luottoa paljon vähemmän kuin 2022
Miltä näyttää median vuosi 2026? Nyt eletään taas trendiraporttien kulta-aikaa. Tässä ovat omat poimintani. Lopussa otan kriittisen näkökulman: mikä ei toteudu?
Ison kuvan hahmottamiseksi suosittelen tutustumaan Sitran megatrendeihin, joiden uusin versio julkaistaan 2026 alussa. Tuttuja asioita ne varmasti jatkossakin sisältävät: geopoliittiset jännitteet, väestön ikääntyminen, talouskasvun hidastuminen, ekologinen kestävyyskriisi, teknologinen murros ja niin edelleen.
Keskityn tässä kirjoituksessa megatrendejä alemman lentokorkeuden asioihin. Painotus on uutismediassa, sosiaalisessa mediassa ja suoratoistomarkkinassa. Nostan yhdeksän trendiä vuodelle 2026 ja miten ne muuttavat media-alaa.
TEEMA: Sisältö
TRENDI 1: Erottuvuudesta alkaa tulla elinehto, mutta mitä kaikkea se tarkoittaa?
Millaista esimerkiksi on journalismi, jota tekoälyjen on vaikeinta tiivistää ja kopioida? Tätä määrittelytyötä tehdään uutismediassa eri otsikoiden alla – unique journalism, distinctive journalism, signature journalism (lähde: uutismediajärjestö Wan-Ifran Newsroom Summit 2025 -tilaisuuden esitykset), mutta yhtä vastausta asiaan ei ole. Eikä kyse ole vain sisällöstä, vaan myös sen tarjoilusta eli personoinnista. Yksi vastaus on, että niin sanottu perusmuotoinen ensiuutisointi pyritään osin automatisoimaan tekoälyn keinoin, ihmisen tarkistamana – jotta aikaa omaleimaisen journalismin tekemiseen jäisi enemmän. Omaleimaisuudelle yksi nimittäjä on, että sisällöissä kuuluu ihmisen ääni, mikä taas edellyttää enemmän läsnäoloa kentällä ja verkostoissa, toimittajan tiedonhankintataitojen korostumista ja niin edelleen, unohtamatta henkilöbrändin kasvavaa merkitystä.
Selvää on, että ainakaan toistaiseksi täysin tekoälyllä tehdyllä sisällöllä ei massasta erotuta (vilkaiskaapa tätä norjalaista Viasportia). Mutta kokeiluja tällä kentällä tapahtuu. Tanskassa seuraava yrittäjä on ”projekti Y”, joka on tekoälyllä pyörivä konservatiivimedia. Oikeampi kysymys voi olla ei se, erottuuko tekoälyllä tehty sisältö muista, vaan onko se kaikesta huolimatta joillekin tarpeeksi hyvää.
TRENDI 2: Tekstiartikkeli ei kuole vieläkään
Voi kiistatta sanoa, että video on internetin hallitseva muoto. Sosiaalinen video jyrää ja audiokin muuttaa muotoaan. Mutta kysyttäessä ihmiset edelleen myös lukevat uutisia todella mielellään tekstinä – Yhdysvalloissa tässä on jopa hienoista kasvua, kun verrataan Pew-tutkimuslaitoksen kyselytutkimusvastauksia vuosilta 2016 ja 2025. Nuorissa audio ja video tietysti erityisesti korostuvat, mutta sellainen hypoteesi, että ihmiset eivät enää haluaisi uutisiaan tekstimuodossa (joka voi toki olla hybridikin tekstiä, audiota, videota), ei yksinkertaisesti näytä pitävän paikkaansa. Ja käytetäänhän tekoälychatejäkin aika paljon, niin, tekstinä. Jos tekstiartikkeli joskus kuolee, niin vuonna 2026 sitä ei vielä ainakaan tapahdu.
TRENDI 3: Lyhytvideon evoluutio jatkuu – esimerkki: mikrodraamat tulevat
Nettiin mahtuu sekä lyhyttä että pitkää, mutta lyhyen pystyvideon kasvu ei näytä hidastuvan. Tämä näkyy myös siinä, että useimmat uutistoimijat ovat tuoneet sovelluksiinsa pystyvideosyötteet, suurista viimeisimpänä New York Times marraskuussa.
Kiinnostava esimerkki lyhytvideon evoluutiosta ovat niin sanotut mikrodraamat. Käytännössä kyse on elokuvista tai tv-sarjoista, jotka on pilkottu hyvin lyhyisiin jaksoihin joko someen tai varta vasten kehitetyille alustoille. Käyttäjät voivat katsoa sisältöä katsomalla mainoksia, ostamalla ”tokeneita” tai tilaamalla palvelun nähdäkseen enemmän kuin ensimmäiset jaksot. Konsulttiyhtiö Deloitte ennakoi trendiraportissaan, että mikrodraamat eivät ole enää ohimenevä trendi, vaan rajusti kasvava bisnes. Ne vetoavat erityisesti nuoreen kohderyhmään, pirstaleiseen huomiokykyyn ja mobiilikäyttäjiin, ja niiden ansaintamallit, kuten jaksokohtaiset mikromaksut, ovat osoittautuneet tuottoisiksi. Mikrodraama ei ole täysin uusi asia, mutta sosiaalisen videon kova kasvu ruokkii tätä ilmiötä.
TEEMA: Teknologia ja jakelu
TRENDI 4: Zero click -ilmiö syö hakuliikennettä, ja se on vaikea pala etenkin pienille medioille
Zero clickillä tarkoitetaan rakenteellista muutosta ihmisten tiedonhakutavoissa, kun he saavat vastauksensa yhä useammin tekoälykoosteista käymättä tiedon alkulähteillä. Hakukoneliikenne, kuten someliikennekin, on pienille medioille usein suhteellisesti tärkeämpää kuin suurille, joten pudotus trafiikkiluvuissa voi iskeä niihin kaikista kipeimmin.
Yksi kiinnostavimpia ajatuksia on, että median arvo ikään kuin alkaisi siirtyä datan rakenteeseen, eikä julkaisupaikkaan. Kun sisältö pilkotaan ja sitä rikastetaan koneluettavaan muotoon, se mahdollistaa sen paremman hyödyntämisen esimerkiksi löydettävyyden parantamiseksi. Media-alalta yksi käytännön esimerkki on News Atom -hanke. Kärjistäen: ilman koneluettavassa muodossa olevaa tavaraa sisällöistä on hyvin vaikeaa tehdä niin sanottua nestemäistä sisältöä eli liquid contentia – käsite, josta ei muuten ole pöhisty tämän vuoden mediaseminaareissa läheskään yhtä paljon kuin viime vuonna. Jostain sekin kertoo.
Sen sijaan media-alan seminaareissa yhä useammin toistuva kirjainlyhenne on MCP. Se on standardoitu rajapinta, jolla tekoäly saa plugin-tyyppisesti pääsyn niihin toimintoihin, joihin se kytketään. Tässä Tilastokeskuksen esimerkki, tässä Guardianin. MCP mahdollistaa sekä työkalukehitystä median sisällä että yleisöille näkyviä ominaisuuksia.
TRENDI 5: Tekoälyagentit yleistyvät ihan oikeasti, mutta myyntipuheiden taakse on entistä vaikeampaa nähdä
Tekoälyagenttia on niin vaikea määritellä, ettei siihen ralliin kannata edes lähteä. Tässä piileekin ongelma: lapsi uhkaa hukkua pesuveden mukana myyntipuheisiin. Kuluttajan on syytä olla tarkkana. Silti: Tekoälypohjaisten agenttien käyttötapaukset alkavat vihdoin oikeasti yleistyä hiljalleen myös mediassa, mutta olen sitä mieltä, että tämäkin asia kaipaa enemmän realistista käytännönläheistä otetta ja vähemmän kattotason ”miksi ette ole jo ottaneet agentteja käyttöön”-kouhotusta, joka kääntyy itseään vastaan. Välähdyksiä realistisesta tulevaisuudesta mediassa voi katsoa vaikka Tampereen yliopiston kokeilusta täältä, vaikka kokeilu vielä raakile olikin.
”Tokens are the new budget”, tokenit ovat uusi budjetti [mediayhtiöille]. Tämä saksalaisen mediayhtiön Ippen Median teknologiajohtajan Markus Frantzin heitto Wan-Ifran Newsroom Summitissa jäi mieleen. Näinhän se on. Tekoälyn käyttö ei ole ilmaista, agenttiarmeijan varsinkaan.
Ei vuosi 2026 ole tässä yhtään helpompi kuin 2025. Kuulostaa ehkä itsestäänselvyydeltä, mutta tämä tuli jälleen mieleen, kun Reuters-instituutti kertoi tuoreesta tekoälykyselystään brittijournalisteille. Tekoälyn käyttö on yleistä, mutta melko rajoittunutta. Strateginen johtaminen ja koulutus eivät ole pysyneet yksittäisten innostujien tahdissa. Vain noin kolmannes kertoi työnantajansa tarjoavan koulutusta tekoälytyökalujen käyttöön.
TEEMA: BISNES
TRENDI 7: Youtube ja Netflix oppivat toisiltaan
Tämän trendin pöllin surutta yhdestä suosikkitrendiraportistani eli konsulttiyhtiö AlixPartnersilta, joka osaa pukea kehityskulut kansantajuisesti sanoiksi. Kaksi jättiläistä eli Youtube ja Netflix lähentyvät toimintatavoiltaan toisiaan huomattavasti vuonna 2026. Mainostulojen jättiläinen YouTube satsaa Netflix-tyyliseen ”tv-laatuiseen” sisältöön kasvattaakseen tilaajamääriään. Samaan aikaan Netflix lisää lyhytvideoita ja suoria lähetyksiä vähentääkseen riippuvuuttaan pelkistä tilausmaksuista.
TRENDI 8: Äänikirjat vahvemmin osaksi perustarjontaa
Suomessa Spotifyn marraskuussa 2025 tekemä lanseeraus on vedenjakaja, koska se rikkoi vallitsevaa markkinadynamiikkaa merkittävällä tavalla. Äänikirjoista tuli yhtäkkiä podcastien kaltaista perustarjontaa sen sijaan, että niitä varten pitäisi ladata erillissovellus. Spotify löytyy jo melkein kaikilta. Spotify-diilin nostattamaan keskusteluun voit tutustua esimerkiksi media-alan asiantuntijan, kirjailija Kari Haakanan blogissa.
TRENDI 9: Bundlauksen uudet muodot ja ”frenemy”-aikakausi
AlixPartners kutsuu trendiraportissaan ”suoratoistosotien” uusinta vaihetta frenemy-aikakaudeksi, jossa kovatkin kilpailijat tekevät yhteistyötä, koska globaalin suoratoistomarkkinan kasvu hidastuu. Odotettavissa on entistä enemmän palveluiden niputtamista (bundlaus) ja sisältöjen ristiinlisensointia kilpailijoiden kesken. Tämä kehitys näkyy jo nyt: suoratoistopalvelut eivät pidä kaikista originaaleistaan kiinni enää verissäpäin.
Bundlausta kokeilee enenevässä määrin uutismediakin. Edustamallani Sanomilla on uudehko +Kaikki-tilauksensa, ruotsalaisella Bonnier Newsillä +Allt. Uusia tilausmalleja varmasti kokeillaan, myös tekoälykehityksen siivittämänä. Yhteistyö kilpailijoiden kanssa on kuitenkin delikaatimpaa kuin suoratoistomarkkinassa.
Kriittinen näkökulma: mikä trendi ei toteudu vuonna 2026?
Puolitosissani joka vuosi ajattelen, että ennakointiin olisi hyvä sisällyttää jonkinlaista tulosvastuuta. Selvitin vuosi sitten, mitä kaikkea sellaista on povattu mediaan, jota ei kuitenkaan ole tapahtunut. Monestihan tulevaisuus toteutuu hieman eri lailla tai ajassa kuin on ajateltu.
No, mitä ei ole vielä tapahtunut? Lineaarinen televisio ei ole vieläkään kuollut (kuten ei tekstikään), vaikka trendi on kiistaton. Lohkoketjusta veikattiin läpimurtoa jo aikaa sitten, hiljaista on. Älypuhelinten myynti ei ole hidastunut, kuten ennakoitiin.
Tälle vuodelle tulee mieleen eritoten yksi asia: jo vuosia monissa trendiraporteissa on uskottu ”wearablesien” eli puettavan teknologian kuten älylasien valtavirtaistumiseen. Esimerkiksi Metan älylaseista on tänä vuonna puhuttu paljon, mutta ei näiden laitteiden kohdalla voida hyvällä tahdollakaan puhua minkäänlaisesta valtavirtaistumisesta. Uskaltaisin lyödä vetoa, että ei myöskään vuonna 2026.
Ja kun kriittisen näkökulman lupasin, palautan lopuksi mieliin intialaisen Times Internet -mediayhtiön Senior Director of Productin Ritvij Parrikhin kommentit kansainvälisen uutismediajärjestön INMA:n tekoälyä käsittelevässä webinaarissa jokin aika sitten. Hiljaista oli, kun hän aika vakuuttavasti perusteli, miksi hänen mielestään laajat kielimallit eivät tule välttämättä koskaan mullistamaan uutismedian liiketoimintaa ainakaan sillä tavalla kuin ennakoimme, koska niiden tuoma kustannussäästö on rajallinen (mm. finetuunaaminen ja ylläpito on kallista) ja toisaalta kaikkien saavutettavissa, eli pysyvää kilpailuetua ei synny. Tällaisetkin näkökulmat ovat virkistäviä, sillä tekoälynarratiivi tuppaa olemaan usein samansuuntaista. Parrikh korosti, että ei ole sitä mieltä, etteikö kyse olisi mullistavasta teknologiasta sinänsä. Hänen mielestään uutismediassa sen todellinen hyöty saattaa kuitenkin jäädä tukirooliin eli mm. ”nappuloiksi käyttöjärjestelmiin”.
Ehkä olen itse hieman optimistisempi, mutta kävi miten kävi, erittäin mielenkiintoisia aikoja elämme!
Mitä oikein tapahtuu, missä ja miksi? Kokoan tähän kirjoitukseen toimintaympäristöhavaintoja mediasta syksyltä 2025. Tein samanlaisen koonnin heinäkuussa kesältä, ja nyt siis uudelleen tuoreemmilla lähteillä. Painotus on uutismediassa.
ARVOT JA ASENTEET
Luottamus uutismediaan laski historiallisen alhaiseksi Yhdysvalloissa. Lähteet: Poynter 3.10.2025, Gallup 2.10.2025. Vuoden 1972 huippulukemista – 72% amerikkalaisista luotti kysyttäessä paljon tai jokseenkin paljon – on tultu 28 prosenttiin (samalla kuitenkin hyvä muistaa, että Suomessa uutisluottamus on yhä kansainvälisessä verrannossa maailman huippua).
LIIKETOIMINTA
Suomessa mediamainonnan määrä on ollut syksyn kaikki kuukaudet miinuksella vuoteen 2024 verrattuna, ilmenee Kantarin keräämistä tiedoista. Yleensä laskua selittävät suurelta osin printtimainonnan laskutrendi. Esimerkiksi syyskuussa mediaryhmistä kasvussa olivat radio, verkkomainonta (sisältää myös somen ja hakumainonnan) ja ulkomainonta. Lähde: Kantar 22.10.2025.
Alma MedianIltalehden ”maksa tai suostu”-evästemalli on epäilemättä yksi syksyn puheenaiheista media-alalla. Lähteitä: Yle 21.10.2025, Iltalehti 21.20.2025, Ilta-Sanomat 23.10.2025.
Sanoman ilmoitus vähentää STT:n käyttöä tai luopua siitä on myös herättänyt paljon keskustelua. Lähteitä: Sanoma 8.9.2025, Suomen Lehdistö 11.9.2025.
MTV:n muutosneuvottelut toivat synkkiä pilviä Suomen media-alalle syyskuussa. Lähde: MTV 8.9.2025.
TEKOÄLY
Ennätyksellisen laaja tutkimus: Tekoälyavustajat vääristävät uutissisältöjä lähes joka toisessa vastauksessa. Lähde: Yle, Euroopan yleisradioliitto EBU 22.10.2025.
Tekoälychätien käyttö uutisten kuluttamiseen on vielä marginaalista, mutta suhteellisesti suurinta nuorissa – mutta ei nuorissa kuitenkaan niin suurta kuin ehkä voisi olettaa tekoälychätien yleisen käyttöasteen perusteella. Lähde: Reuters-instituutti 7.10.2025.
Niin sanotut agenttiset työnkulut ja ratkaisut erilaisiin tarpeisiin alkavat aidosti pikku hiljaa konkretisoitua media-alallakin. Tosin, aina kun kuulet väitteen ”we have agentic workflows”, suhtaudu kriittisesti: termin alla myydään kaikkea mahdollista. Lähteitä: INMA, INMA 2.10.2025.
Mielipidejournalismi näyttäisi tuovan eniten klikkejä ChatGPT:n kautta uutismediaan – vaikka ei niitä klikkeja kaikkineen silti kauheasti tule. Lähde: Suomen Lehdistö 13.10.2025.
Uutispalvelu täysin tekolyllä? Kokonaan tekoälyn avulla tehdyt ja pyörivät uutissivustot ovat ajatuksena monella tavalla ongelmallisia, eivätkä tähänastiset toteutukset vakuuta (riippuu tietysti esimerkiksi, haluaako saavuttaa oikeita yleisöjä vai bottiyleisöjä…) – tässä kuitenkin yksi esimerkki, ilmeisesti norjalaistaustainen Viasport. Kesällä suomalaisvoimin julkaistu Freepress.ai on laadukkaampi ja sanoo pyörivänsä osin ihmisvoimin, mutta on herättänyt kysymyksiä tekijänoikeuksista.
Googlen tekoälytila eli AI Mode tuli näkyviin lokakuussa myös suomalaiskäyttäjille. Uutistoimijat ovat huolissaan muun muassa siksi, että liikenne tekoälyhakujen kautta on minimaalista, toisaalta niiden tiivistämä tai muuten käyttämä tieto on usein virheellistä. Lähteitä: Ilta-Sanomat 8.10.2025, BBC 9.9.2025.
Minun ja Jaakon johtamisaiheisen podin voit kuunnella myös suoraan tästä upotuksesta:
YLEISÖT
Tuore ruotsalaistutkimus: Nuoret kuluttavat vähemmän yhteiskunnallisia uutisia ja enemmän rikossisältöjä kuin ennen. Muutoksen taustalla on raportin mukaan yhtenä syynä sosiaalisen median käytön nousu. Lähde: Yleisradion toimintaympäristökatsaus 9/2025.
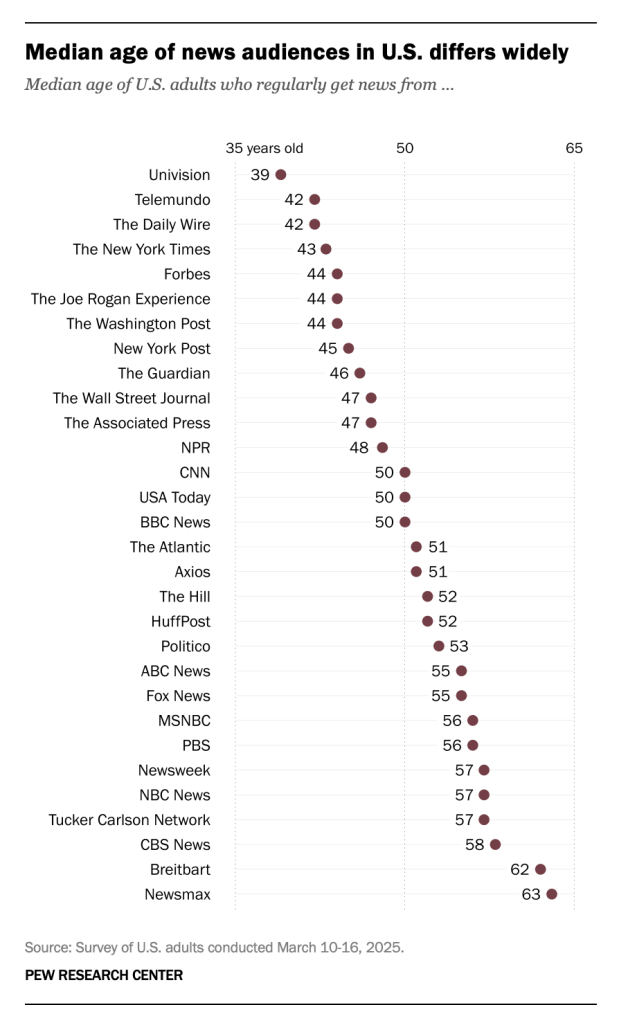
Suurten yhdysvaltalaisten uutistoimijoiden yleisöjen keski-ikä vaihtelee huomattavasti. Nuorimmat yleisöt Pew-tutkimuslaitoksen tutkimuksessa olivat espanjankielisellä Univisionilla (mediaani 39 vuotta) ja vanhimmat oikeistolaisilla Newsmaxilla (63) ja Breitbartilla (62). Joe Roganin podcastin kuuntelijoiden keski-ikä on 44 vuotta. Lähde: Pew-tutkimuslaitos, 28.8.2025.
Yllättävän moni on kysynyt minulta, millä tavalla tämä tekoälymyllerryksen aika johtamismielessä eroaa siitä jo suht kaukaiselta tuntuvasta ajasta, kun uutismediassa ruvettiin toden teolla miettimään printti–digi-siirtymää. On kysytty myös, millaista muutosjohtamisen pitäisi olla AI-aikakaudella nimenomaan journalismin kontekstissa eli käytännössä työympäristössä, jossa aika monella on koko ajan aika kiire.
Tämä blogikirjoitus on yritys jäsentää ajatukseni ja mielipiteeni tästä teemasta jonkinlaiseksi kokonaisuudeksi.
1. Päätöksenteko ja resurssit
Mikä toimii sinun mediassasi, ei välttämättä toimi toisen. Organisaation koolla on väliä. Jos resurssit ovat pienet, ovat myös roolit ja arjen käytännöt väistämättä erilaisia kuin isommassa talossa. Esimerkiksi näin:
Iso toimija: Keskitetty vai hajautettu organisoituminen, vai jotain siltä väliltä? Mielipiteeni: välimalli paras – pääasia, että liiketoiminnan tarpeet tunnetaan mahdollisimman hyvin ja toimeenpanoon ei synny pullonkauloja. Mediataloissa on aina ollut jonkinasteinen kuilu sisältö- ja kehityspuolen välillä. Sen minimointi on kaikkien etu, ja kyllä siihen tahtoa löytyy.
Pieni toimija: Mistä aloittaa, jos on aivan minimaaliset resurssit, eikä kykyä rakentaa esimerkiksi omia työkaluja? Mielipiteeni: Esim. ChatGPT Business tai Enterprise & litterointityökalu Goodtape kuukausimaksuilla alkuun osalle henkilöstöä. Rajoitteet selviksi: mitä niihin voi laittaa ja mitä ei. Kehityspäällikkö tai vastaava koordinoi. Jos mahdollista, voit nimetä tiimeihin/osastoille tekoälyvastaavat, jotka muodostavat ydinkäyttäjäryhmän ja parhaimmillaan levittävät innostusta ympärilleen.
2. Älä tee AI-strategiaa
Tai siis aivan ehdottomasti tee AI-strategia, mutta älä hyvä ihminen kutsu sitä tekoälystrategiaksi. Yrityksessä on vain yksi strategia. Teet sitten suuntatyötä, tiekarttaa tai toimintasuunnitelmaa, pidä ajatus kirkkaana: tässä on tavoitetila, ja näillä askelilla me sitä kohti menemme. Tämä toimii myös selkänojana tarvittaessa kipeillekin päätöksille: mitä priorisoidaan. Mielipiteeni: Jos yksi kohderyhmä on uutistoimitus, ydinviesti on saatava tiristettyä muutamaan slaidiin selkosuomeksi, muuten sitä ei muista kukaan. Kaikkien sitä ei tarvitsekaan muistaa, mutta vähintään keskijohdon pitää. Tarkista tasaisin väliajoin suuntatyösi merivedenkestävyys: puoli vuotta sitten tehdyt kriittiset oletukset voivat olla jo vanhentuneita.
Isosti ajatteleminen vai pikkuasioiden viilaaminen? Jonkinlainen suuntatyö varmistaa, että organisaatio ajattelee tarpeeksi isosti: mistä saadaan hyötyä mahdollisimman laajalti. Kolikon toinen puoli on se, että monesti sieltä ruohonjuuritason arjesta nousevat tarpeet ja toiveet tekoälyn hyödyntämiselle ovat tärkeitä ja konkreettisia, vaikka eivät “strategisiksi hankkeiksi” välttämättä yltäisikään esimerkiksi potentiaalisen käyttäjäjoukon pienuuden vuoksi. Mielipiteeni: älä jätä pikkuasioiden viilaamista liikaa huomiotta, jos haluat edistää tekoäly-ymmärrystä omassa mediassasi, muuten et välttämättä saa läpi isojakaan. Ja kun ajattelet isosti, koeta nähdä hypen yli.
Jos ajattelet, että tehtäväsi on kehittää tai saada ihmiset käyttämään tekoälytyökaluja, ajattelet liian pienesti. Auta kehittämään työnkulkuja, työn tekemisen tapoja. Mielipiteeni: Tiedetään, tämä on helpommin sanottu kuin tehty. Mutta tässäkin keskijohto – tiimin/osastojen vetäjät – ovat esimerkillään avainasemassa.
3. Arjen käytäntöjä
Selvitä lähtötaso. Jos teet kyselyn, pakota kaikki vastaamaan vaikka firman vetäytymisessä. Mielipiteeni: Alhaisen vastausprosentin kyselyillä et tee oikeasti mitään. Ideaalitilanteessa voit seurata työkalujen osalta käyttöä ns. kovasta analytiikasta.
Luo uusia rakenteita: tietoiskuja, työpajoja, 1:1-tuokioita, “syväsukelluksia”…räätälöi työpajat kunkin tiimin/osaston tarpeisiin, mikäli mahdollista. Selvitä, millaisia arjen ongelmia ja haasteita kenelläkin on – ne ovat todennäköisesti aivan erilaisia kuvaajalla, deskin pikavuorolaisella tai featurejuttujen tekijällä – ja pohdi, voisiko ainakin osaa niistä helpottaa tekoälyn avulla. Mielipiteeni: Työpajan ei tarvitse olla ylifasilitoitua ydinfysiikkaa. Esimerkiksi näin: Kesto 1,5 tuntia. 1) Vapaamuotoinen alkukeskustelu ja mahdollisen ennakkotehtävän läpikäynti: missä mennään & toiveet, 2) Alustus: työkalut ja muutama esimerkki, 3) Jokainen tekee yhden itselleen uuden asian jollain tekoälytyökalulla, 4) Yhdessä purku lopuksi.
Ruoki edelläkävijöiden innostusta: jos he haluavat koluta läpi n8n:t (wau), zapierit (mjoo) ja powerautomatet (wau mutta huoh), anna heille siihen resursseja ja aikaa. Mielipiteeni: Totta kai on varmistettava tekoälyn vastuullinen käyttö, mutta älä tapa intoa.
Oppien jakaminen ja jatkuva seuranta. Osastojen/tiimien väliin syntyy helposti siiloja. Naapurissa ei välttämättä lainkaan tiedetä, mitä toisella puolella tehdään. Mielipiteeni: On jaksettava toistaa, vaikka se kävisikin jo vähän tylsäksi. Vältä tätä: toimitukseen syntyy AI-ajan päivystäviä ATK-tukihenkilöitä, joiden puoleen käännytään liian helposti. Tiimien/osastojen esihenkilöt ovat muutoksen johtamisessa avainasemassa, koska he voivat näyttää esimerkkiä.
Tuo kuvituskuva? Kolmiot muistuttavat siitä, että asioita on syytä tehdä paitsi ylhäältä alas mutta myös fiksusti alhaalta ylös. Numerot kuvaavat karkeaa jaottelua tekoälytyökalujen käytöstä uutistoimituksissa – perustuu lähinnä mutuun ja joihinkin kansainvälisiin tutkimuslähteisiin: 10 prosenttia on edelläkävijöitä, 20 prosenttia ei juurikaan käytä ainakaan vielä ja keskellä on porukka, joka käyttää vaihtelevasti.