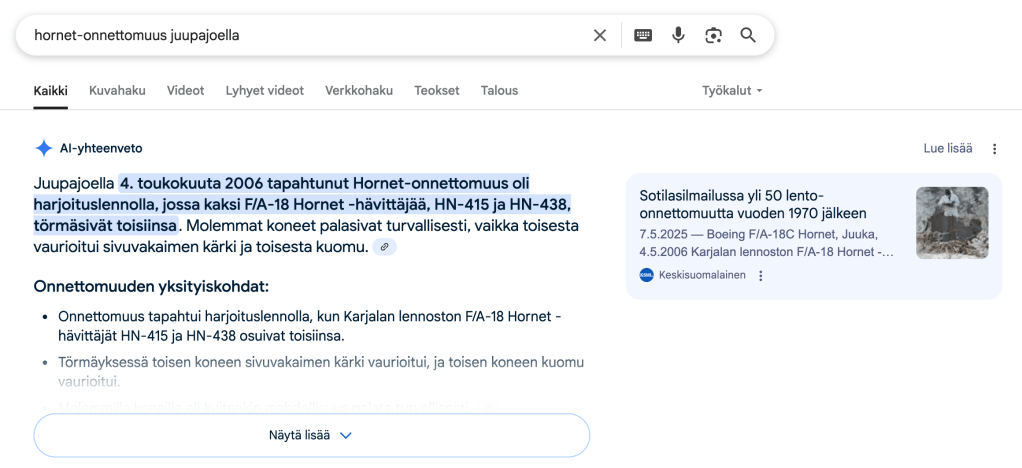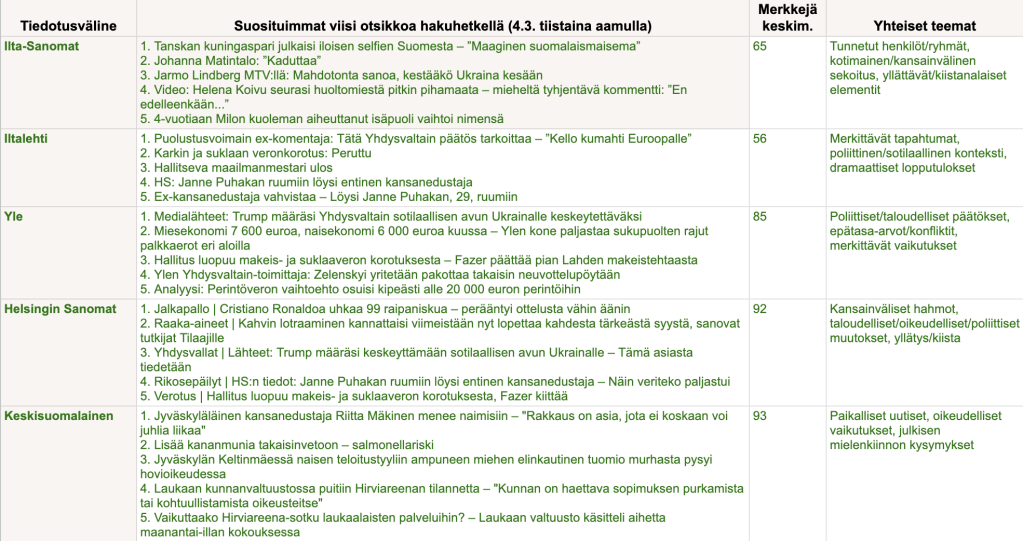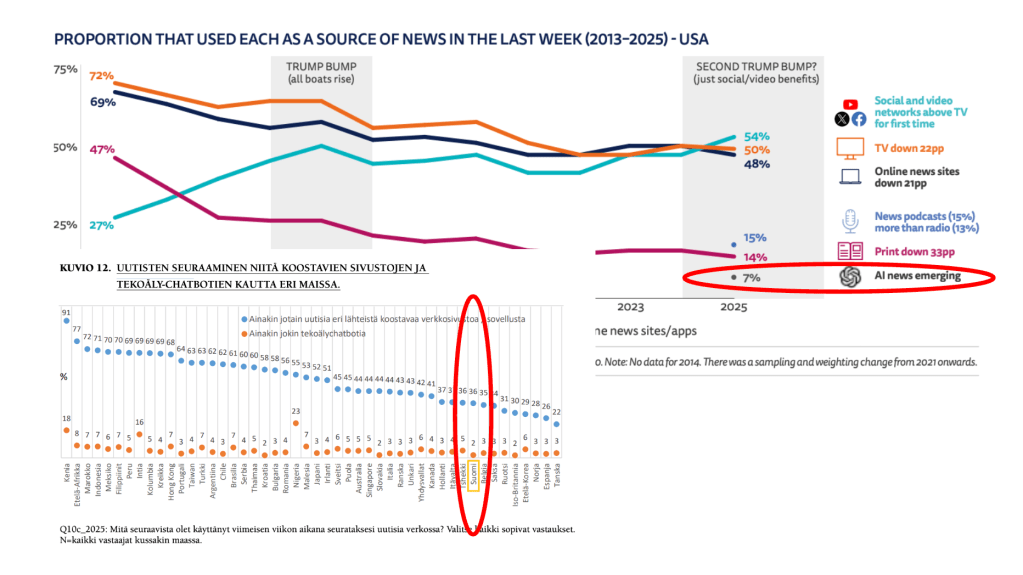
”Seitsemän prosenttia ihmisistä käyttää chatboteja uutisten kuluttamiseen [Yhdysvalloissa]. Se kuulostaa minusta yllättävän alhaiselta luvulta.”
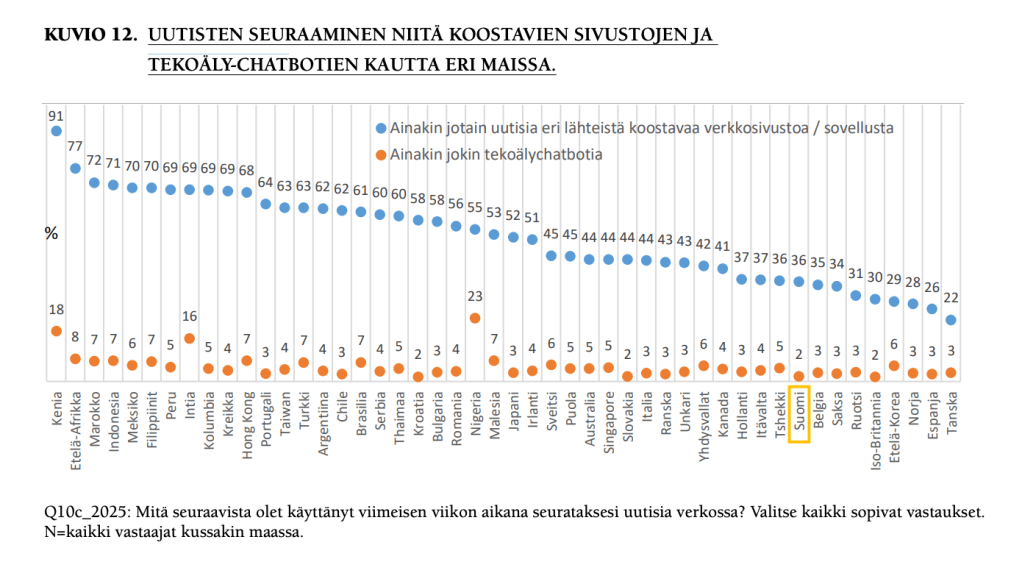
Näin kommentoi Reuters-instituutin Digital News Report 2025:n tulosta Linkedinissä Florent Daudens, joka on ohjelmistoyhtiö Hugging Facella työskentelevä tekoälyn ja journalismin asiantuntija. Nuorissa osuus toki on isompi, alle 25-vuotiaissa 15 prosenttia.
Mutta silti, aika pientä.
Daudens ei ollut ainoa yllättynyt.
Suomessa luku on vielä alhaisempi, 2-3 prosenttia (lue täältä Uutismedia verkossa 2025:n eli Suomen-maaraportin koosteeni).
Kontrasti tekoälychatien käyttöön yleisesti on suuri: esimerkiksi amerikkalaisista 28 % käyttää tekoälytyökaluja viikottain.
Itse näen tässä kaikuja uutismedian historiasta monessakin mielessä. Digital News Reportin tuloksia pohtiessa on syytä tiedostaa ainakin nämä kysymykset:
- Yleinen tekoälykäyttö vs. uutiskäyttö. Vedämmekö turhan helposti yhtäläisyysmerkkejä uusien teknologioiden yleisen käytön ja uutiskäytön välillä?
- Eihän Alexan kaltaisten virtuaaliassistenttienkaan kautta ole oikeastaan haluttu kuunnella uutisia, vaan pikemminkin musiikkia.
- Olemmeko jälleen vanhan sanonnan edessä: läheinen tulevaisuus yliarvoidaan, kaukainen aliarvioidaan?
- Jos jokin asia on teknisesti mahdollista toteuttaa, tarkoittaako se aina, että ihmiset haluaisivat juuri sitä?
- Tässä kohtaa olen tuttavapiirissä kärjistäen viitannut usein heittoon, jonka mukaan uutisia tullaan joskus lukemaan jääkaapin ovesta. Monikaan ei vaan tunnu pohtivan, miksi ihmeessä joku haluaisi näin tehdä, vaikka se olisikin teknisesti mahdollista.
- Vaatiiko tekoälychatien käyttö uutisten kuluttajilta liikaa aktiivisuutta siihen nähden, että uutisia tykätään kuitenkin kuluttaa eniten, no, passiivisesti? Tähän vastaan itse empimättä, että kyllä.
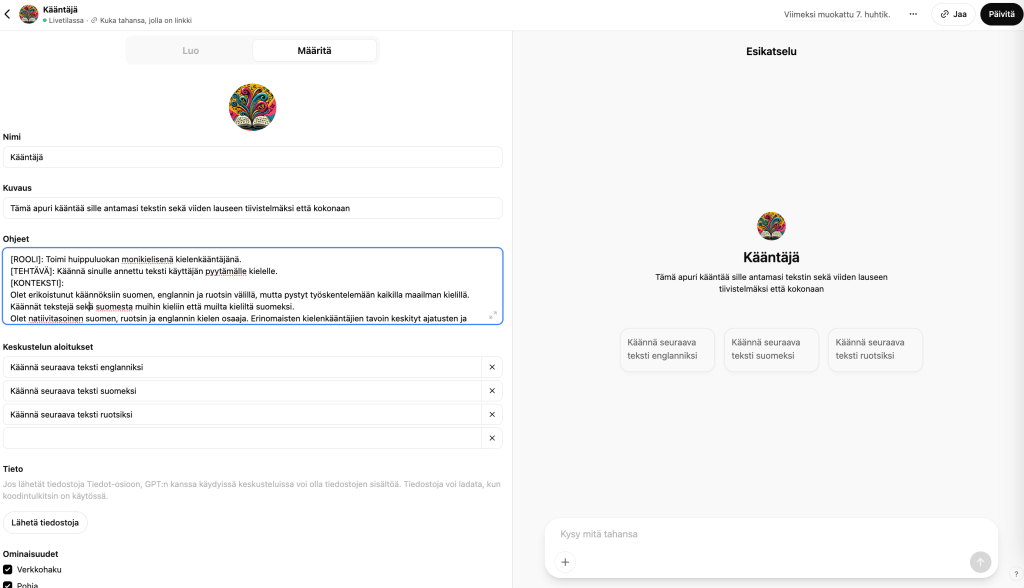
- Kuka jaksaa kirjoittaen tai jutellen pyytää nimenomaan_uutisia? Osa ns. uutisfriikeistä, joihin itsekin kuulun, varmasti kyllä. Iso massa? Hmm. Tiedämme myös uutismedioiden varhaisista kokeiluista tekoälychateillä, että niitä käytetään mieluiten valmiiden oletuspainikkeiden kautta. Miksi? Koska se on vaivattomampaa kuin näpyttely. Tästä seuraa isompi kysymys: miksi edes tehdä chatboteja, jos niitä käytetään lähinnä vain oletuspainikkein. Toisin päin: jos tekoälychatien käyttö kyetään tekemään nimenomaan uutisten kuluttamiseen mahdollisimman vaivattomaksi, on siinä enemmän potentiaalia.
- Potentiaalia ainakin jossain määrin varmasti on: Uutismedia verkossa 2025 -raportissa kartoitettiin myös suomalaisten näkemystä erilaisiin tekoälyn mahdollistamiin esitystapoihin nimenomaan uutispalvelussa. 11 prosenttia ilmoitti, että voisi olla kiinnostunut käyttämään tekoälychatbotia, joka vastaa uutisia koskeviin kysymyksiin.
- Kaikki edellä mainitut pointit huomioiden, tämä ei kuitenkaan ole mediankäyttäjälle pelkästään valintakysymys.
- Googe kehittää tekoälyominaisuuksiaan siihen suuntaan, että tulevaisuudessa on vaikeampi olla käyttämättä tekoälychateja uutistenkin kuluttamiseen kuin nyt.
- ”Voi olettaa, että tekoälyn mahdollistamat erilaiset uutissisältöjen hakumenetelmät tulevat muuttamaan ihmisten tapoja hakeutua uutisten äärelle. He eivät ehkä jatkossa enää samassa määrin ajattele seuraavansa tietyn uutismedian uutisia, vaan ylipäätään verkosta löytyvää tietoa kulloinkin itseä kiinnostavasta aiheesta. Tämä voi entisestään vaikeuttaa ihmisten sitouttamista yksittäisten uutismedioiden tilaajiksi.”, todetaan Uutismedia verkossa 2025 -raportissa.